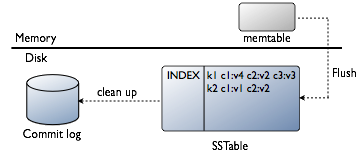
How Cassandra stores data
A brief description and illustration of how Cassandra stores and distributes data.
In the memtable, data is organized in sorted order.
For efficiency, Cassandra does not repeat the names of the columns in memory or in the SSTable. For example, the following writes occur:
write (k1, c1:v1) write (k2, c1:v1 C2:v2) write (k1, c1:v4 c3:v3 c2:v2)
In the memtable, Cassandra stores this data after receiving the writes:
k1 c1:v4 c2:v2 c3:v3 k2 c1:v1 c2:v2
In the commit log on disk, Cassandra stores this data after receiving the writes:
k1, c1:v1 k2, c1:v1 C2:v2 k1, c1:v4 c3:v3 c2:v2
In the SSTable on disk, Cassandra stores this data after flushing the memtable:
k1 c1:v4 c2:v2 c3:v3 k2 c1:v1 c2:v2