You can map a file in an external file system, such as S3 native file system to a
table in Hive.
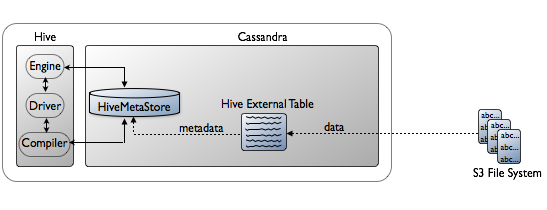
You can map a file in an external file system, such as S3 native file system to a
table in Hive. The DSE Hadoop cluster continues to use the Cassandra File System
(CFS). The data source is external to Hive, located in S3 for example. You create a
Hive external table for querying the data in an external file system. When you drop
the external table, only the table metadata that is stored in the HiveMetaStore
keyspace is removed. The data persists in the external file system.
First, set up the hive-site.xml and
core-site.xml files, and then create an external table as
described in this procedure.
Procedure
-
Open the file for editing.
The default location of
the
hive-site.xml file depends on the type of
installation:
| Installer-Services and Package installations |
/etc/dse/hive/hive-site.xml
|
| Installer-No Services and Tarball
installations |
install_location/resources/hive/conf/hive-site.xml
|
-
Add a property to hive-site.xml to set the default file
system to be the native S3 block file system. Use
fs.default.name as the name of the file system and
the location of the bucket as the value. For example, if the S3 bucket name is
mybucket:
<property>
<name>fs.default.name</name>
<value>s3n://mybucket</value>
</property>
-
Save the file.
-
Open the file for editing.
The default location of
the
core-site.xml file depends on the type of
installation:
| Installer-Services and Package installations |
/etc/dse/hadoop/conf/core-site.xml
|
| Installer-No Services and Tarball
installations |
install_location/resources/hadoop/conf/core-site.xml
|
-
Add these properties to core-site.xml to specify the access key ID and the
secret access key credentials for accessing the native S3 block
filesystem:
<property>
<name>fs.s3n.awsAccessKeyId</name>
<value>ID</value>
</property>
<property>
<name>fs.s3n.awsSecretAccessKey</name>
<value>Secret</value>
</property>
-
Save the file and restart Cassandra.
-
Create a directory in s3n://mybucket named, for example,
mydata_dir.
-
Create a data file named mydata.txt, for example. Delimit
fields using =.
"key1"=100
"key2"=200
"key3"=300
-
Put the data file you created in
s3n://mybucket/mydata_dir.
-
Using cqlsh, create a keyspace and a
CQL table schema to accommodate the data on S3.
cqlsh> CREATE KEYSPACE s3_counterpart WITH replication =
{'class': 'NetworkTopologyStrategy', 'Analytics': 1};
cqlsh> USE s3_counterpart;
cqlsh:s3_counterpart> CREATE TABLE mytable
( key text PRIMARY KEY , data int );
-
Start Hive, and on the Hive command line, create an external table for the data
on S3. Specify the S3 file name as shown in this example.
hive> CREATE EXTERNAL TABLE mytable (key STRING, value INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '=' STORED AS TEXTFILE LOCATION 's3n://mybucket/mydata_dir/';
Now, having the S3 data in Hive, you can query the data using
Hive.
-
Select all the data in the file on S3.
SELECT * from mytable;
OK
key1 100
key2 200
key3 300