Defining a multi-column partition key
A partition key can have a partition key defined with multiple table columns which determines which node stores the data.
NULL value cannot be
inserted into a PRIMARY KEY column. This restriction applies to
both partition keys and clustering columns.Data is retrieved using the partition key. Keep in mind that to retrieve data from the table, values for all columns defined in the partition key have to be supplied, if secondary indexes are not used. The table shown uses race_year and race_name in the primary key, as a composite partition key. To retrieve data, both parameters must be identified.
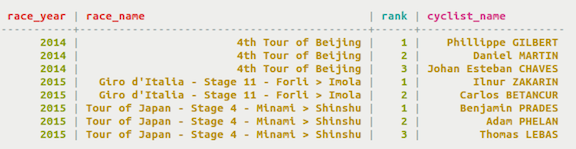
The database stores an entire row of data on a node by partition key. If you have too much data in a partition and want to spread the data over multiple nodes, use a composite partition key.
Using a composite partition key
Use a composite partition key to identify where data will be stored.
NULL value cannot be
inserted into a PRIMARY KEY column. This restriction applies to
both partition keys and clustering columns.A composite partition key table can be created in two different ways, as shown.
Procedure
-
Create the table rank_by_year_and_name in the
cycling keyspace. Use race_year
and race_name for the composite partition key. The table
definition shown has an additional column rank used in the
primary key. Before creating the table, set the keyspace with a
USEstatement. This example identifies the primary key at the end of the table definition. Note the double parentheses around the first two columns defined in thePRIMARY KEY.USE cycling; CREATE TABLE rank_by_year_and_name ( race_year int, race_name text, cyclist_name text, rank int, PRIMARY KEY ((race_year, race_name), rank) );
-
The keyspace name can be used to identify the keyspace in the
CREATE TABLEstatement instead of theUSEstatement.CREATE TABLE cycling.rank_by_year_and_name ( race_year int, race_name text, cyclist_name text, rank int, PRIMARY KEY ((race_year, race_name), rank) );