Anatomy of a graph traversal
The anatomy of a graph traversal explores the results of each traversal step.
Structure of a graph traversal
Simple traversals can be complex, but generally do not employ specialized techniques such as recursion or branching.
Break down the chain of a graph traversal into traversal
steps:
g.V().hasLabel('recipe').count()- The graph traversal
g gwill return an error if run alone- All vertices are gathered with
V() - All the vertices will be returned. A sample of the
result:
gremlin> g.V()==>v[{~label=recipe, recipeId=2003}] ==>v[{~label=recipe, recipeId=2005}] ==>v[{~label=ingredient, ingredId=3017}] ==>v[{~label=ingredient, ingredId=3028}] ==>v[{~label=person, personId=1}] ==>v[{~label=person, personId=3}] ==>v[{~label=book, bookId=1004}] ==>v[{~label=book, bookId=1001}] ==>v[{~label=meal, type="lunch", mealId=4003}] - Filter out the vertices labeled as a recipe with
hasLabel('recipe') - Only the vertices that are recipes will be
returned:
gremlin> g.V().hasLabel('recipe') ==>v[{~label=recipe, recipeId=2003}] ==>v[{~label=recipe, recipeId=2005}] ==>v[{~label=recipe, recipeId=2006}] ==>v[{~label=recipe, recipeId=2007}] ==>v[{~label=recipe, recipeId=2001}] ==>v[{~label=recipe, recipeId=2002}] ==>v[{~label=recipe, recipeId=2004}] ==>v[{~label=recipe, recipeId=2008}] - Count the number of vertices with
count() - The number of vertices returned from the last traversal step is
totalled:
gremlin> g.V().hasLabel('recipe').count() ==>8
Graph traversal with edges
Before trying the traversals displayed below, run the following script either in Studio
(copy and paste) or Gremlin console (:load
/tmp/generateReviews.groovy):
// reviewer vertices
johnDoe = graph.addVertex(label, 'person', 'personId', 11, 'name','John Doe')
johnSmith = graph.addVertex(label, 'person', 'personId', 12, 'name', 'John Smith')
janeDoe = graph.addVertex(label, 'person', 'personId', 13, 'name','Jane Doe')
sharonSmith = graph.addVertex(label, 'person', 'personId', 14, 'name','Sharon Smith')
betsyJones = graph.addVertex(label, 'person', 'personId', 15, 'name','Betsy Jones')
beefBourguignon = g.V().has('recipe', 'recipeId', 2001, 'name','Beef Bourguignon').tryNext().orElseGet {graph.addVertex(label, 'recipe', 'recipeId', 2001, 'name', 'Beef Bourguignon')}
spicyMeatLoaf = g.V().has('recipe', 'recipeId', 2005, 'name','Spicy Meatloaf').tryNext().orElseGet {graph.addVertex(label, 'recipe', 'recipeId', 2005, 'name', 'Spicy Meatloaf')}
carrotSoup = g.V().has('recipe', 'recipeId', 2007, 'name','Carrot Soup').tryNext().orElseGet {graph.addVertex(label, 'recipe', 'recipedId', 2007, 'name', 'Carrot Soup')}
// reviewer - recipe edges
johnDoe.addEdge('reviewed', beefBourguignon, 'timestamp', Instant.parse('2014-01-01T00:00:00.00Z'), 'stars', 5, 'comment', 'Pretty tasty!')
johnSmith.addEdge('reviewed', beefBourguignon, 'timestamp', Instant.parse('2014-01-23T00:00:00.00Z'), 'stars', 4)
janeDoe.addEdge('reviewed', beefBourguignon, 'timestamp', Instant.parse('2014-02-01T00:00:00.00Z'), 'stars', 5, 'comment', 'Yummy!')
sharonSmith.addEdge('reviewed', beefBourguignon, 'timestamp', Instant.parse('2015-01-01T00:00:00.00Z'), 'stars', 3, 'comment', 'It was okay.')
johnDoe.addEdge('reviewed', spicyMeatLoaf, 'timestamp', Instant.parse('2015-12-31T00:00:00.00Z'), 'stars', 4, 'comment', 'Really spicy - be careful!')
sharonSmith.addEdge('reviewed', spicyMeatLoaf, 'timestamp',Instant.parse('2014-07-23T00:00:00.00Z'), 'stars', 3, 'comment', 'Too spicy for me. Use less garlic.')
janeDoe.addEdge('reviewed', carrotSoup, 'timestamp', Instant.parse('2015-12-30T00:00:00.00Z'), 'stars', 5, 'comment', 'Loved this soup! Yummy vegetarian!')Any number of traversal steps can be chained into a traversal, filtering and transforming
the graph data as required. In some cases, edges will be the result, and perhaps unexpected.
Consider the following
traversal:
g.V().hasLabel('recipe').has('name', 'Beef Bourguignon').inE().values('comment')g.V().hasLabel('recipe'). It is then followed by:- A traversal step to pick only the vertices with the recipe title specified
- The filter should capture one recipe if recipe titles are
unique.
gremlin> g.V().hasLabel('recipe').has('name', 'Beef Bourguignon') ==>v[{~label=recipe, recipeId=2001}] - A traveral step that retrieves incoming edges
- Notice from the two edges sampled from the complete result that edges with any label
are filtered with this step. Using
inE('reviewed')would be more precise if the target result are only ratings.gremlin> g.V().hasLabel('recipe').has('name', 'Beef Bourguignon').inE() ==>e[{~label=includedIn, ~out_vertex={~label=ingredient, ingredId=3001}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=95672dd0-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=ingredient, ingredId=3001}-includedIn->{~label=recipe, recipeId=2001}] ==>e[{~label=includedIn, ~out_vertex={~label=ingredient, ingredId=3002}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=9567ca17-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=ingredient, ingredId=3002}-includedIn->{~label=recipe, recipeId=2001}] ==>e[{~label=includedIn, ~out_vertex={~label=ingredient, ingredId=3003}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=9567ca16-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=ingredient, ingredId=3003}-includedIn->{~label=recipe, recipeId=2001}] ==>e[{~label=includedIn, ~out_vertex={~label=ingredient, ingredId=3004}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=9567ca14-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=ingredient, ingredId=3004}-includedIn->{~label=recipe, recipeId=2001}] ==>e[{~label=includedIn, ~out_vertex={~label=ingredient, ingredId=3005}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=956754e0-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=ingredient, ingredId=3005}-includedIn->{~label=recipe, recipeId=2001}] ==>e[{~label=created, ~out_vertex={~label=person, personId=1}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=956495c4-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=person, personId=1}-created->{~label=recipe, recipeId=2001}] ==>e[{~label=reviewed, ~out_vertex={~label=person, personId=11}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=95775a70-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=person, personId=11}-reviewed->{~label=recipe, recipeId=2001}] ==>e[{~label=reviewed, ~out_vertex={~label=person, personId=12}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=95773361-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=person, personId=12}-reviewed->{~label=recipe, recipeId=2001}] ==>e[{~label=reviewed, ~out_vertex={~label=person, personId=13}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=95773360-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=person, personId=13}-reviewed->{~label=recipe, recipeId=2001}] ==>e[{~label=reviewed, ~out_vertex={~label=person, personId=14}, ~in_vertex={~label=recipe, recipeId=2001}, ~local_id=95778180-2e3d-11e8-8043-6bfe97ac83b9}] [{~label=person, personId=14}-reviewed->{~label=recipe, recipeId=2001}] - Parsing out the comment property from the rated edges
- Here, the
inE()is specified with the edge labelreviewed. The property values are retrieved for the property keycomment:gremlin> g.V().hasLabel('recipe').has('name', 'Beef Bourguignon').inE('reviewed').values('comment') ==>Yummy! ==>Pretty tasty! ==>It was okay.
Building graph traversals one step at a time can yield interesting results and insight into how to create traversals.
The path of a graph traversal
A traversal step exists that will show the path taken by a graph traversal. First, find the
results for a traversal that answers the question about what recipes that list beef and
carrots as ingredients are included in the cookbooks, given the cookbook and recipe
title?
gremlin> g.V().hasLabel('ingredient').has('name',within('beef','carrots')).in().as('Recipe').
out().hasLabel('book').as('Book').
select('Book','Recipe').by('name').
by('name')
==>{Book=The Art of French Cooking, Vol. 1, Recipe=Beef Bourguignon}
==>{Book=The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution, Recipe=Carrot Soup}One expects that the traversal path will be from
ingredient to
recipe to book. To check if this assumption is correct,
add path() to the end of the
traversal.gremlin> g.V().hasLabel('ingredient').has('name',within('beef','carrots')).
in().as('Recipe').
out().hasLabel('book').as('Book').
select('Book','Recipe').
by('name').by('name').path()
==>[v[{~label=ingredient, ingredId=3001}], v[{~label=recipe, recipeId=2001}], v[{~label=book, bookId=1001}],
{Book=The Art of French Cooking, Vol. 1, Recipe=Beef Bourguignon}]
==>[v[{~label=ingredient, ingredId=3028}], v[{~label=recipe, recipeId=2007}], v[{~label=book, bookId=1004}],
{Book=The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution, Recipe=Carrot Soup}]Traversal metrics
In addition to tracing the output of each graph traversal step, metrics can produce
interesting insights as well. To add metrics to the last traversal shown, use some
additional chained
steps:
gremlin> g.V().has('recipe', 'name', 'Beef Bourguignon').inE().values('comment').profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep(vertex,[],(label = recipe & name ... 1 1 9.710 77.19
query-optimizer 0.946
\_condition=((label = recipe & name = Beef Bourguignon) & (true))
query-setup 0.051
\_isFitted=true
\_isSorted=false
\_isScan=false
index-query 7.131
\_indexType=Search
\_usesCache=false
\_statement=SELECT "recipeId" FROM "newComp"."recipe_p" WHERE "solr_query" = '{"q":"*:*", "fq":["name:Bee
f\\ Bourguignon"]}' LIMIT ?; with params (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
DsegVertexStep(IN,edge,direction = IN,Unordered) 10 10 2.275 18.09
query-optimizer 0.421
\_condition=((true) & direction = IN)
query-setup 0.016
\_isFitted=true
\_isSorted=false
\_isScan=false
vertex-query 0.475
\_usesCache=false
\_statement=SELECT * FROM "newComp"."recipe_e" WHERE "recipeId" = ? LIMIT ? ALLOW FILTERING; with params
(java.lang.Integer) 2001, (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_usesIndex=false
DsegPropertiesStep([comment],value,label = comm... 3 3 0.593 4.71
>TOTAL - - 12.579 -Looking at the metrics, the question of performance comes to mind. For instance, is there
any way to optimize the traversal shown above? In fact, a simple modification results in a
time
savings:
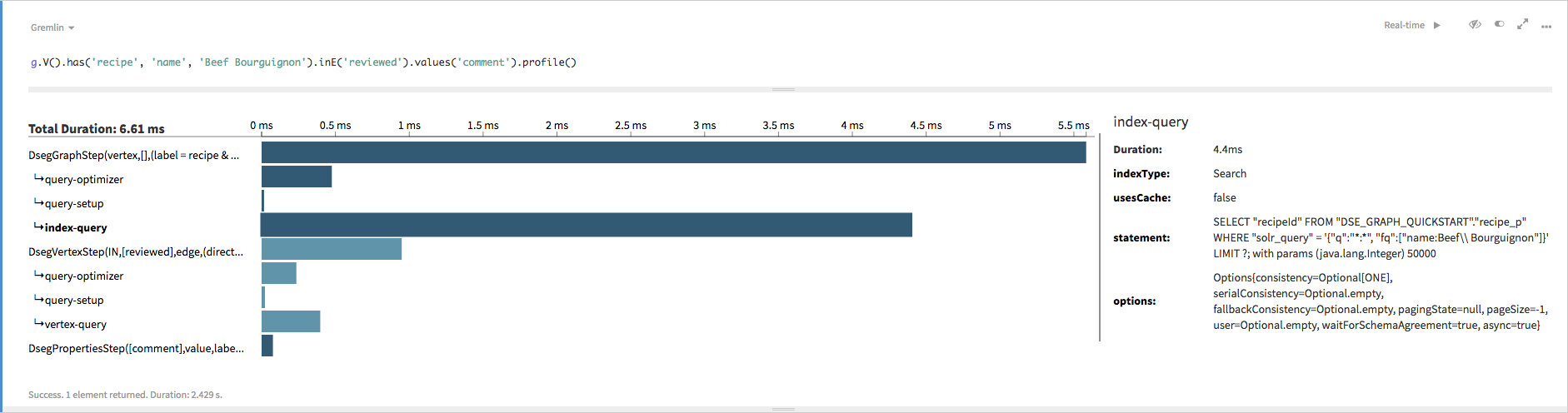
gremlin> g.V().has('recipe', 'name', 'Beef Bourguignon').inE('reviewed').values('comment').profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
DsegGraphStep(vertex,[],(label = recipe & name ... 1 1 7.109 83.34
query-optimizer 0.342
\_condition=((label = recipe & name = Beef Bourguignon) & (true))
query-setup 0.013
\_isFitted=true
\_isSorted=false
\_isScan=false
index-query 6.110
\_indexType=Search
\_usesCache=false
\_statement=SELECT "recipeId" FROM "DSE_GRAPH_QUICKSTART"."recipe_p" WHERE "solr_query" = '{"q":"*:*", "fq":["name:Bee
f\\ Bourguignon"]}' LIMIT ?; with params (java.lang.Integer) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
DsegVertexStep(IN,[reviewed],edge,(direction = ... 4 4 1.234 14.47
query-optimizer 0.187
\_condition=((direction = IN & label = reviewed) & (true))
query-setup 0.009
\_isFitted=true
\_isSorted=false
\_isScan=false
vertex-query 0.474
\_usesCache=false
\_statement=SELECT * FROM "DSE_GRAPH_QUICKSTART"."recipe_e" WHERE "recipeId" = ? AND "~~edge_label_id" = ? LIMIT ? ALL
OW FILTERING; with params (java.lang.Integer) 2001, (java.lang.Integer) 65633, (java.lang.Int
eger) 50000
\_options=Options{consistency=Optional[ONE], serialConsistency=Optional.empty, fallbackConsistency=Option
al.empty, pagingState=null, pageSize=-1, user=Optional.empty, waitForSchemaAgreement=true, asyn
c=true}
\_usesIndex=false
DsegPropertiesStep([comment],value,label = comm... 3 3 0.186 2.19
>TOTAL - - 8.530 - inE() has been replaced by
inE('reviewed'), to find only the edges that are reviews. Although each
measurement can vary, generally the second traversal will outperform the first
traversal.DataStax Studio provides more easy to use metrics, in which scrolling over or selecting any
phase of the traversal can be explored: