データ・モデリングの概念
Cassandraでのデータ・モデリングのアプローチ方法。CQLドキュメント全体を通じてPro Cycling統計例が使用されています。
データ・モデリングは、実体(格納する項目)と実体間の関係を識別するプロセスです。データ・モデルを作成するには、データのアクセスに使用するパターンと、実行するクエリーの種類を識別します。これらの2つのアイデアは、データの編成と構造、およびデータベースのテーブルの設計と作成に関する情報を提供します。データのインデックスを作成するとパフォーマンスが向上する可能性が高いため、どのカラムにセカンダリ・インデックスを持たせるかを決めます。
Cassandraのデータ・モデリングでは、クエリー駆動型のアプローチを使用します。このアプローチでは、特定のクエリーがデータを編成するための鍵となります。クエリーとはテーブルからデータを選択した結果であり、スキーマとはテーブル内のデータの編成方法の定義です。Cassandraのデータベース設計は、高速な読み取りと書き込みに対する要件に基づいているため、スキーマの設計が優れているほど、データの書き込みと取得が高速になります。
一方、リレーショナル・データベースは、設計されたテーブルと関係に基づいてデータを正規化した後、実行されるクエリーを書き込みます。リレーショナル・データベースにおけるデータ・モデリングはテーブル駆動型で、テーブル間の関係はクエリー内でのテーブル結合として表現されます。
Cassandraのデータ・モデルは、調整可能な整合性を伴って行ストアにパーティションされます。調整可能な整合性とは、すべての読み取りまたは書き込み操作に対して、クライアント・アプリケーションが、要求されたデータに必要な整合性を定めることを意味します。行はテーブルにまとめられます。テーブルのプライマリ・キーの最初の要素はパーティション・キーです。パーティション内では、各行がキーの残りのカラムによってクラスター化されています。他のカラムには、プライマリ・キーとは別にインデックスを付けることができます。Cassandraは分散データベースであるため、ノード上のデータをパーティションごとにグループ分けすると、読み取りと書き込みの効率が向上します。質問に対する回答を得るためにクエリーする必要のあるパーティションの数が少ないほど、応答は高速になります。整合性レベルの調整はレイテンシーを左右するもう1つの要因ですが、これはデータ・モデリング・プロセスの一部ではありません。
Cassandraのデータ・モデリングでは、クエリーに重点が置かれます。このトピック全体を通じてPro Cycling統計例を使用して、特定のクエリーに対してCassandraテーブル・スキーマをモデル化する方法を示します。このデータ・モデルの概念的モデルは、実体と関係を示します。
実体とその関係については、テーブルの設計時に考慮します。クエリーは1つのテーブルにアクセスするように設計するのが最適であるため、クエリーの対象となる関係に関与するすべての実体がこのテーブルに含まれている必要があります。以下の最初の例に示すように、一部のテーブルでは1つの実体とその属性が関与します。他のテーブルでは、2番目の例に示すように、複数の実体とその属性が関与します。すべてのデータを1つのCassandraテーブルに含める方法はリレーショナル・データベースのアプローチと相反します。リレーショナル・データベースのアプローチでは、データは2つ以上のテーブルに格納され、外部キーを使用してテーブル間のデータが関連付けられます。Cassandraではこの1つのテーブルと1つのクエリーのアプローチを使用するため、クエリーはより高速に実行できます。
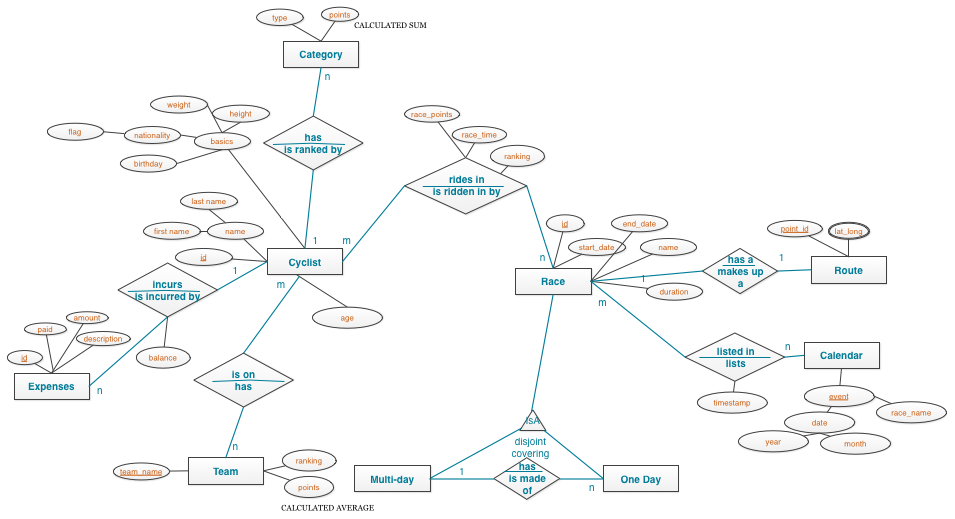
Pro Cycling統計に対する1つの基本的なクエリー(Q1)は、サイクリストのリストです。このリストには、各サイクリストのID、名、および姓が含まれます。テーブル内のサイクリストを一意に識別するために、UUIDを使用したIDが使用されます。すべてのサイクリストをリストする単純なクエリーを実行するために、識別されているすべてのカラムと、IDのパーティション・キー(K)を含むテーブルが作成されます。以下の図は、Pro Cyclingデータ・モデルに対する論理モデルの一部を示しています。
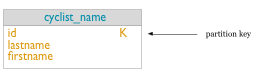
関連するクエリー(Q2)では、特定の人種のカテゴリーに属するすべてのサイクリストを検索します。Cassandraでは、すべてのサイクリストをカテゴリー別にグループ分けしたテーブルを作成すると、このクエリーの効率が向上します。一部の同じカラム(ID、姓)が必要になりますが、テーブルのプライマリ・キーにはパーティション・キーとしてのカテゴリー(K)と、ID別のパーティション内のグループ(C)が含まれます。この選択により、サイクリストごとに一意のレコードが作成されます。
これらは2つの単純なクエリーです。CQLを使用したデータ・モデリングを示すために、後で追加の例を紹介します。
テーブルの設計における主要な原則は、リレーショナル・データベース・モデリングのような、他のテーブルに対するテーブルの関係ではないことに注意してください。Cassandraのデータは1つのテーブルごとに1つのクエリーとして編成されている場合が多く、データは多くのテーブル間で繰り返されます。これは、非正規化と呼ばれるプロセスです。一方、リレーショナル・データベースではデータを 正規化し、重複をできる限り取り除きます。実体間の関係は重要です。データがCassandraに格納される順序がデータの取得のしやすさと速度に大きく影響する場合があるためです。スキーマ設計は、関連する属性を同じテーブルに含めることで、実体間の関係のほとんどを捕捉します。アプリケーション・コード内のクライアント側結合は、テーブル・スキーマでは関係の複雑さを捕捉できない場合にのみ使用します。