グラフ・データ・モデリングの概要
一部のグラフ・データ・モデルについての簡単な説明。
通常、グラフ・データベースのデータ・モデリングは簡単なプロセスです。ホワイトボードに書かれた頂点と線で表した情報を想像できたら、グラフ・データベースのデータ・モデルが90%完成したも同然です。

ジュリア・チャイルドは、多くのレシピを生み出している有名な料理人です。1961年に、彼女が米国のファンのために作ったレシピの1つが牛肉のブルゴーニュ風煮込みです。上図では、ジュリア・チャイルド(Julia Child)という人が牛肉のブルゴーニュ風煮込み(beef bourguignon)というレシピにリンクされています。人とレシピは2つのタイプの頂点であり、頂点をつなげる線つまり辺は、その関係が「作った」であると識別します。頂点と辺は、人の名前、レシピ名、辺に関連付けられている日付など、関連付けられているプロパティを持っています。プロパティは、グラフに関するクエリーで使用される基本要素であり、プロパティ・キーとプロパティ値で構成されています。グラフ・データベースでは、頂点は辺に対するインシデントであり、辺は頂点に対するインシデントです。頂点は別の頂点に隣接しています。このデータ・モデルの一般化されたビューを以下に示します。
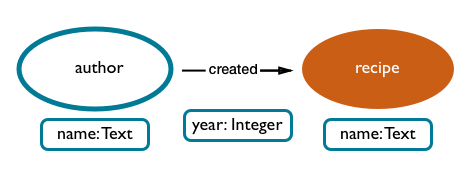
各頂点には、特定のタイプの頂点を識別する頂点ラベルが割り当てられます。ここに示される頂点ラベルはauthorとrecipeです。各辺もそのタイプを指定する辺ラベルを持っていなければなりません。示されている辺ラベルはcreatedです。示されているプロパティはnameとyearです。
より複雑なグラフでは、複数の辺が頂点をつなぐことができ、複数のプロパティを頂点と辺に割り当てることができます。頂点プロパティは、プロパティのプロパティであるメタプロパティを持つことができます。
残りの10%の作業の最も重要な要素は、ホワイトボードのグラフの要素を頂点または辺のどちらにするかという最適化です。辺として使おうと考えていた要素を何度も使うようであれば、それは頂点にするべきでしょう。たとえば、作成者(author)に出身国の頂点プロパティを追加することを考えてみましょう。この場合、作成者の多くが中国やフランスなど同じ国から来ると考えられるので、場所の頂点タイプを作成すれば、後々のクエリー操作にとって有利になる可能性があります。