CREATE TABLE cycling.cyclist_name (
id UUID PRIMARY KEY,
lastname text,
firstname text
);
CREATE CUSTOM INDEX fn_prefix ON cyclist_name (firstname) USING 'org.apache.cassandra.index.sasi.SASIIndex';
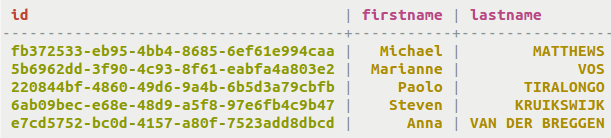
SELECT * FROM cyclist_name WHERE firstname LIKE 'M%';
部分文字列に基づく一致を検出できないクエリーはたくさんあります。次のクエリーはすべて失敗します。
SELECT * FROM cyclist_name WHERE firstname = 'MARIANNE';
SELECT * FROM cyclist_name WHERE firstname LIKE 'm%';
SELECT * FROM cyclist_name WHERE firstname LIKE '%m%';
SELECT * FROM cyclist_name WHERE firstname LIKE '%m%' ALLOW FILTERING;
SELECT * FROM cyclist_name WHERE firstname LIKE '%M%';
SELECT * FROM cyclist_name WHERE firstname = 'M%';
SELECT * FROM cyclist_name WHERE firstname = '%M';
SELECT * FROM cyclist_name WHERE firstname = '%M%';
SELECT * FROM cyclist_name WHERE firstname = 'm%';
SELECT * FROM cyclist_name WHERE firstname = 'Marianne';
SELECT * FROM cyclist_name WHERE firstname = 'MariAnne' ALLOW FILTERING;
SELECT * FROM cyclist_name WHERE firstname LIKE '%m%';
SELECT * FROM cyclist_name WHERE firstname LIKE 'M%';
SELECT * FROM cyclist_name WHERE firstname LIKE '%M';
SELECT * FROM cyclist_name WHERE firstname LIKE 'm%';
CREATE CUSTOM INDEX fn_suffix_allcase ON cyclist_name (firstname) USING 'org.apache.cassandra.index.sasi.SASIIndex'
WITH OPTIONS = {
'mode': 'CONTAINS',
'analyzer_class': 'org.apache.cassandra.index.sasi.analyzer.NonTokenizingAnalyzer',
'case_sensitive': 'false'
};
ALTER TABLE cyclist_name ADD age int;
UPDATE cyclist_name SET age=23 WHERE id=5b6962dd-3f90-4c93-8f61-eabfa4a803e2;
INSERT INTO cyclist_name (id,age,firstname,lastname) VALUES (8566eb59-07df-43b1-a21b-666a3c08c08a,18,'Marianne','DAAE');
SELECT * FROM cyclist_name WHERE firstname='Marianne' and age > 20 allow filtering;
ALTER TABLE cyclist_name ADD comments text;
UPDATE cyclist_name SET comments ='Rides hard, gets along with others, a real winner' WHERE id = fb372533-eb95-4bb4-8685-6ef61e994caa;
UPDATE cyclist_name SET comments ='Rides fast, does not get along with others, a real dude' WHERE id = 5b6962dd-3f90-4c93-8f61-eabfa4a803e2;
CREATE CUSTOM INDEX stdanalyzer_idx ON cyclist_name (comments) USING 'org.apache.cassandra.index.sasi.SASIIndex'
WITH OPTIONS = {
'mode': 'CONTAINS',
'analyzer_class': 'org.apache.cassandra.index.sasi.analyzer.StandardAnalyzer',
'analyzed': 'true',
'tokenization_skip_stop_words': 'and, the, or',
'tokenization_enable_stemming': 'true',
'tokenization_normalize_lowercase': 'true',
'tokenization_locale': 'en'
};