Graph data modeling introduction
Brief introduction to the parts of a graph data model.
Data modeling for graph databases is generally a simple process. Imagine information written on a whiteboard as vertices and lines connecting them, and you are 90% done with a graph database data model.
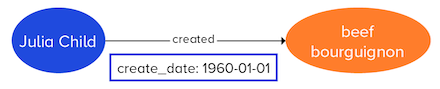
Julia Child was a famous chef who created many recipes. One of the recipes she created for an American audience in 1961 was beef bourguignon. In the diagram above, a person, Julia Child, is linked to a recipe, beef bourguignon. Person and recipe are two types of vertex, and the line adjoining the vertices, or edge, identifies the relationship as "created". Vertices and edges have associated properties, such as a person's name, a recipe name, and the date associated with the edge. Properties are a basic element that are used in a query about the graph, and consist of a property key and property value. In graph databases, a vertex is incident to an edge, and an edge is incident to a vertex. A vertex is adjacent to another vertex if they share an edge. A generalized view of this data model is shown below:
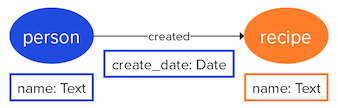
Each vertex is assigned a vertex label to identify a specific type of vertex. The vertex
labels shown here are person and recipe. Each edge must also
have an edge label specifying its type. The edge label shown is created.
The properties shown are name and createDate.
DSE Graph limits the number of vertex labels to 200 per graph.
For more complex graphs, multiple edges can connect vertices, and multiple properties can be assigned to vertices and edges. Both properties and edges can have multiple cardinality. Vertex properties can have meta-properties, a property on a property.
An important concept to be aware of is the nature of vertices and edges as addressable elements. Indexes play a critical role in querying graphs, and vertex labels must be a part of every index. Only vertices are globally addressable, whereas edges are only locally addressable. In practice, what this situation means is that edges can only be indexed locally for a particular vertex label. Edges are about the relationship of vertices, and are classified as second-class citizens; vertices are entities and are first-class citizens for which all graph operations are available. To illustrate the nature of the second-class citizenry of edges, meta-properties of edges cannot be indexed and used to narrow queries, making those edges better modeled as vertices if the data stored in the meta-properties must be used to narrow down a query.
For the remaining 10% of your effort, optimization of whether an aspect of your whiteboard graph should be a vertex or an edge is the most pressing factor. If an aspect used as an edge begins to be used more than a few times, it should become a vertex instead. For instance, we could add a vertex property to the author to add their country of origin. However, since many authors will come from the same country, such as the China or France, creating a location vertex type can be more advantageous to later querying operations.