クラスター化カラム
クラスター化カラムに対するクエリーを制限して、クラスター化セグメント全体の範囲を検索します。
クラスター化カラムは、パーティション内のデータの順序を決定します。テーブルに複数のクラスター化カラムがある場合、データはネストされたソート順で格納されます。データベースはクラスター化情報を使用してパーティション内のデータの場所を特定します。クラスター化カラムにロジック文を使用してクラスター化セグメントを特定し、データのスライスを返します。
クラスター化カラムまたはインデックス・カラムに対してクエリーに制限がない場合は、そのパーティションのすべてのデータが返されます。
順序がクラスター化の制限に与える影響
データベースはクラスター化カラムを使用してパーティションのデータの場所を判断するため、等号(=)またはIN演算子を使用して、上位のクラスター化カラムを明確に特定する必要があります。クエリーで、範囲演算子(>、>=、<、<=)を使用して制限できるのは最下位のみです。
データの格納方法
CREATE TABLE numbers (
key int,
col_1 int,
col_2 int,
col_3 int,
col_4 int,
PRIMARY KEY ((key), col_1, col_2, col_3, col_4));
key | col_1 | col_2 | col_3 | col_4 -----+-------+-------+-------+------- 100 | 1 | 1 | 1 | 1 100 | 1 | 1 | 1 | 2 100 | 1 | 1 | 1 | 3 100 | 1 | 1 | 2 | 1 100 | 1 | 1 | 2 | 2 100 | 1 | 1 | 2 | 3 100 | 1 | 2 | 2 | 1 100 | 1 | 2 | 2 | 2 100 | 1 | 2 | 2 | 3 100 | 2 | 1 | 1 | 1 100 | 2 | 1 | 1 | 2 100 | 2 | 1 | 1 | 3 100 | 2 | 1 | 2 | 1 100 | 2 | 1 | 2 | 2 100 | 2 | 1 | 2 | 3 100 | 2 | 2 | 2 | 1 100 | 2 | 2 | 2 | 2 100 | 2 | 2 | 2 | 3 (18 rows)
データベースはネストされたソート順を使用してデータの格納と検索を行います。 データはクエリーが探索する階層に格納されます。
{ "key" : "100" {
"col_1" : "1" {
"col_2" : "1" {
"col_3" : "1" {
"col_4" : "1",
"col_4" : "2",
"col_4" : "3" },
"col_3" : "2" {
"col_4" : "1",
"col_4" : "2",
"col_4" : "3" } },
"col_2" : "2" {
"col_3" : "2" {
"col_4" : "1",
"col_4" : "2",
"col_4" : "3" } } },
"col_1" : "2" {
"col_2" : "1" {
"col_3" : "1" …
パーティションのフルスキャンを避けてクエリーを効率化するには、等号またはIN演算子を使用して、ソート順の上位カラム(col_1、col_2、col_3)を特定する必要があります。最後のカラム(col_4)では範囲を使用できます。
クラスター化セグメントのデータの選択
SELECT * FROM numbers
WHERE key = 100
AND col_1 = 1 AND col_2 = 1 AND col_3 = 1
AND col_4 <= 2;key | col_1 | col_2 | col_3 | col_4 -----+-------+-------+-------+------- 100 | 1 | 1 | 1 | 1 100 | 1 | 1 | 1 | 2 (2 rows)
IN演算子は中~大規模なデータセットのパフォーマンスに影響を与える場合があります。複数のセグメントを選択すると、指定したすべてのセグメントが読み込まれ、フィルター処理されます。
SELECT * FROM numbers
WHERE key = 100
AND col_1 IN (1, 2)
AND col_2 = 1 AND col_3 = 1
AND col_4 <= 2;以下の図は、複数のセグメントをフィルター処理するためにデータベースで読み込む必要があるすべてのセグメントを示しています。
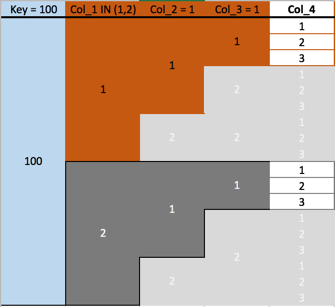
key | col_1 | col_2 | col_3 | col_4 -----+-------+-------+-------+------- 100 | 1 | 1 | 1 | 1 100 | 1 | 1 | 1 | 2 100 | 2 | 1 | 1 | 1 100 | 2 | 1 | 1 | 2 (4 rows)
無効な制限
SELECT * FROM numbers
WHERE key = 100
AND col_4 <= 2;InvalidRequest: Error from server: code=2200 [Invalid query] message="PRIMARY KEY column "col_4" cannot be restricted as preceding column "col_1" is not restricted"
最上位のクラスター化カラムのみを制限する
パーティション・カラムと異なり、クエリーのロジック文で下位のクラスター化カラムを除外することができます。
SELECT * FROM numbers
WHERE key = 100 AND col_1 = 1
AND col_2 > 1;key | col_1 | col_2 | col_3 | col_4 -----+-------+-------+-------+------- 100 | 1 | 2 | 2 | 1 100 | 1 | 2 | 2 | 2 100 | 1 | 2 | 2 | 3 (3 rows)
複数のクラスター化セグメントにまたがる範囲を返す
スライス取得を行うと、クラスター化セグメント全体を確認して、複数のカラムの値が一致する行を見つけることができます。スライス・ロジック文は、1つの行の場所を見つけて、その行の前後とその行、およびその間にあるすべての行を返すことができます。
(clustering1, clustering2[, …]) range_operator (value1, value2[, …])
[AND (clustering1, clustering2[, …]) range_operator (value1, value2[, …])]パーティション全体のスライス
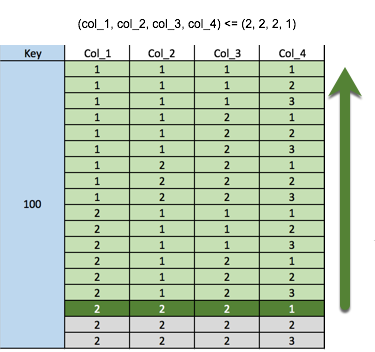
SELECT * FROM numbers
WHERE key = 100
AND (col_1, col_2, col_3, col_4) <= (2, 2, 2, 1);データベースは一致する行を見つけると、特定した行の前にあるすべてのレコードを結果セットで返します。
SELECT * FROM numbers
WHERE key = 100
AND (col_1, col_2, col_3, col_4) <= (2, 1, 1, 4);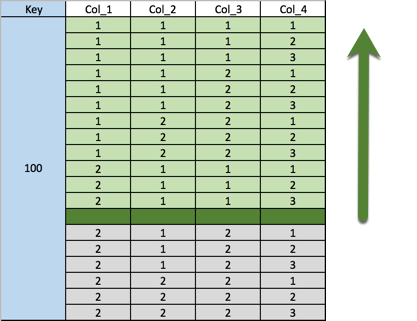
クラスター化セグメントのスライス
下位のセグメントでスライスを見つける場合も同じ規則がスライス制約に適用されます。等号またはINを使用して上位のクラスター化セグメントを特定し、下位のセグメントの範囲を指定します。
SELECT * FROM numbers
WHERE key = 100 AND col_1 = 1 AND col_2 = 1
AND (col_3, col_4) >= (1, 2)
AND (col_3, col_4) < (2, 3);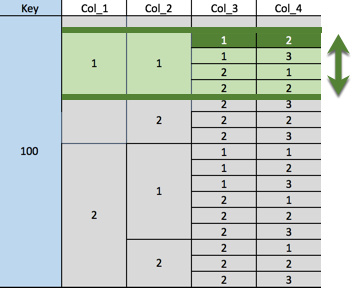
無効なクエリー
SELECT * FROM numbers
WHERE key = 100 AND col_1 = 1
AND (col_2, col_3, col_4) >= (1, 1, 2)
AND (col_3, col_4) < (2, 3);InvalidRequest: Error from server: code=2200 [Invalid query] message="Column "col_3" cannot be restricted by two inequalities not starting with the same column"
手順
CREATE TABLE cycling.events (
Year int,
Start_Month int,
Start_Day int,
End_Month int,
End_Day int,
Race TEXT,
Discipline TEXT,
Location TEXT,
UCI_code TEXT,
PRIMARY KEY ((YEAR, Discipline), Start_Month, Start_Day, Race));
SELECT start_month as month, start_day as day, race FROM cycling.events
WHERE year = 2017 AND discipline = 'Road'
AND (start_month, start_day) < (2, 14) AND (start_month, start_day) > (1, 15); month | day | race
-------+-----+-----------------------------------------------------------------
1 | 23 | Vuelta Ciclista a la Provincia de San Juan
1 | 26 | Cadel Evans Great Ocean Road Race - Towards Zero Race Melbourne
1 | 26 | Challenge Mallorca: Trofeo Porreres-Felanitx-Ses Salines-Campos
1 | 28 | Cadel Evans Great Ocean Road Race
1 | 28 | Challenge Mallorca: Trofeo Andratx-Mirador des Colomer
1 | 28 | Challenge Mallorca: Trofeo Serra de Tramuntana -2017
1 | 29 | Cadel Evans Great Ocean Road Race
1 | 29 | Grand Prix Cycliste la Marseillaise
1 | 29 | Mallorca Challenge: Trofeo Palma
1 | 31 | Ladies Tour of Qatar
2 | 1 | Etoile de Besseges
2 | 1 | Jayco Herald Sun Tour
2 | 1 | Volta a la Comunitat Valenciana
2 | 5 | G.P. Costa degli Etruschi
2 | 6 | Tour of Qatar
2 | 9 | South African Road Championships
2 | 11 | Trofeo Laigueglia
2 | 12 | Clasica de Almeria
(18 rows)