複数カラムのパーティション・キーの定義
パーティション・キーには、複数のテーブル・カラムで定義したパーティション・キーを含めることができます。このパーティション・キーによって、データの格納先となるノードが決まります。
複合パーティション・キーのあるテーブルでは、DataStax Enterpriseはパーティション・キーとして複数のカラムを使用します。これらのカラムは、取得を容易にするためにパーティション内で論理集合を形成します。単純なパーティション・キーとは対照的に、複合パーティション・キーではデータの存在場所を特定するために2つ以上のカラムを使用します。複合パーティション・キーは、格納されたデータが大きすぎて単一のパーティションに収まらない場合に使用されます。パーティション・キーに複数のカラムを使用すると、データがチャンクまたはバケットに分割されます。データはグループ分けされますが、小さいチャンクになります。この方法は、クラスターが1つのノードにデータを繰り返し書き込む際、パーティションで大量の書き込みが行われるために、ホットスポットや輻輳が発生する場合に有効です。DataStax Enterpriseは時系列データによく使用されるため、ホットスポットが実際に問題となることがあります。year:month:day:hourによって着信データをバケットに分割し、4つのカラムを使用してパーティションにルーティングすることでホットスポットを減らすことができます。
データはパーティション・キーを使用して取得します。セカンダリ・インデックスを使用しない場合、テーブルからデータを取得するには、パーティション・キーで定義したすべてのカラムの値を指定する必要があることに注意してください。ここに示したテーブルは、複合パーティション・キーとして、プライマリ・キーでrace_yearとrace_nameを使用しています。データを取得するには、両方のパラメーターを指定する必要があります。
データベースは、データの行全体をパーティション・キーに従ってノードに格納します。パーティションにデータが多すぎるため、データを複数のノードに分散させたい場合は、複合パーティション・キーを使用してください。
複合パーティション・キーの使用
複合パーティション・キーを使用して、データの格納場所を識別します。
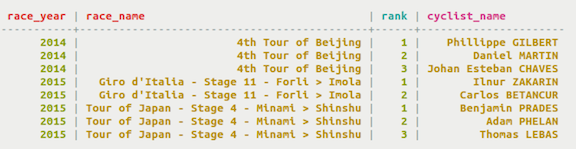
データを複数のパーティションに分散し、クエリーを実行してソートされた結果を取得するために使用できるカラム・セットを作成するには、プライマリ・キーで複合パーティション・キーを使用します。次の例では、レースに参加したサイクリストのランキングと名前を格納するrank_by_year_and_nameテーブルを作成します。このテーブルでは、プライマリ・キーの複合パーティション・キーを定義するカラムとしてrace_yearとrace_nameを使用します。クエリーは、年度とレース名の値を指定することにより、レースに参加したサイクリストのランキングを取得します。
複合パーティション・キー・テーブルは、以下に示すように2通りの異なる方法で作成できます。
手順
-
cyclingキースペースにテーブルrank_by_year_and_nameを作成します。複合パーティション・キーとしてrace_yearとrace_nameを使用します。ここに示したテーブル定義には、プライマリ・キーで使用される追加のカラムrankがあります。テーブルを作成する前に
USE文を使用してキースペースを設定します。この例では、プライマリ・キーはテーブル定義の末尾で指定されています。PRIMARY KEYで定義された最初の2つのカラムは二重の丸かっこで囲まれていることに注意してください。USE cycling; CREATE TABLE rank_by_year_and_name ( race_year int, race_name text, cyclist_name text, rank int, PRIMARY KEY ((race_year, race_name), rank) );
-
USE文の代わりに、CREATE TABLE文でキースペース名を使用してキースペースを指定できます。CREATE TABLE cycling.rank_by_year_and_name ( race_year int, race_name text, cyclist_name text, rank int, PRIMARY KEY ((race_year, race_name), rank) );