結果のソートと制限
単純なクエリーの場合のSELECTコマンドの使用。
データを選択するテーブルにクエリーするのは、データがデータベースに格納されているためです。CQLは、SQLと同様に、単純または複雑な修飾子を使用してデータを選択(SELECT)できます。最も単純な場合、クエリーは、テーブルにあるデータをすべて選択します。最も複雑な場合では、クエリーは、どのデータを取得して表示するかを記述し、ユーザー定義関数に基づいて新しい値の計算も行います。
SASIのインデックス作成については、「SASIの使用」のクエリーの説明を参照してください。
PER PARTITION LIMITを使用した、返される行数の制御
DataStax Enterprise 5.1以降では、PER PARTITION LIMITオプションを使用して、クエリーで各パーティションから返される行数の最大数を設定します。データを複数のパーティションにソートするテーブルを作成します。
CREATE TABLE cycling.rank_by_year_and_name (
race_year int,
race_name text,
cyclist_name text,
rank int,
PRIMARY KEY ((race_year, race_name), rank) );データを挿入した後、テーブルには以下の値が格納されます。
race_year | race_name | rank | cyclist_name
-----------+--------------------------------------------+------+----------------------
2014 | 4th Tour of Beijing | 1 | Phillippe GILBERT
2014 | 4th Tour of Beijing | 2 | Daniel MARTIN
2014 | 4th Tour of Beijing | 3 | Johan Esteban CHAVES
2015 | Giro d'Italia - Stage 11 - Forli > Imola | 1 | Ilnur ZAKARIN
2015 | Giro d'Italia - Stage 11 - Forli > Imola | 2 | Carlos BETANCUR
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 1 | Benjamin PRADES
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 2 | Adam PHELAN
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 3 | Thomas LEBAS次に、レース年とレース名ごとに上位2名のサイクリストを取得するには、次のコマンドとPER PARTITION LIMIT 2を使用します。
SELECT * FROM cycling.rank_by_year_and_name
PER PARTITION LIMIT 2;出力:
race_year | race_name | rank | cyclist_name
-----------+--------------------------------------------+------+-------------------
2014 | 4th Tour of Beijing | 1 | Phillippe GILBERT
2014 | 4th Tour of Beijing | 2 | Daniel MARTIN
2015 | Giro d'Italia - Stage 11 - Forli > Imola | 1 | Ilnur ZAKARIN
2015 | Giro d'Italia - Stage 11 - Forli > Imola | 2 | Carlos BETANCUR
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 1 | Benjamin PRADES
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 2 | Adam PHELAN手順
-
テーブルのデータをすべて表示するには、単純な
SELECTクエリーを使用します。SELECT * FROM cycling.cyclist_category;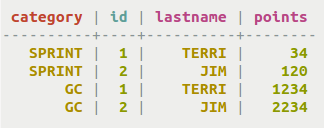
-
以下の例は、categoryをフィルターとして使用するクエリーを作成する方法を示しています。
SELECT * FROM cycling.cyclist_category WHERE category = 'SPRINT';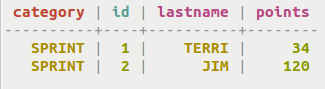
categoryがパーティション・キーまたはクラスター化カラムでない場合、このクエリーは拒否されることに注意してください。クエリーは、cyclist_categoryテーブル全体の連続取得を必要とします。DataStax Enterpriseではこれは重要な概念として理解しておく必要があり、すべてのノードのデータをすべてスキャンするのは非常に時間がかかるため、その実行はブロックされます。パーティション・キーとクラスター化カラムを
WHERE句で使用すると、連続した行のセットを選択することになります。クエリーはセカンダリ・インデックスを使用してフィルター処理することができます。「インデックスの作成と維持」を参照してください。lastnameに基づいたクエリーは、lastnameカラムのインデックスが作成されている場合には満足のいく結果が得られます。
-
DataStax Enterprise 5.1以降では、セカンダリ・インデックスが作成されていない場合でも、
ALLOW FILTERINGも使用すればクラスター化カラムをWHERE句内で定義できます。テーブル定義、SELECTコマンドの順に指定します。race_start_dateはセカンダリ・インデックスのないクラスター化カラムであることに注意してください。CREATE TABLE cycling.calendar ( race_id int, race_name text, race_start_date timestamp, race_end_date timestamp, PRIMARY KEY (race_id, race_start_date, race_end_date));SELECT * FROM cycling.calendar WHERE race_start_date='2015-06-13' ALLOW FILTERING;
-
すべてのデータを選択する代わりに、カラムを選択して表示することもできます。
SELECT category, points, lastname FROM cycling.cyclist_category;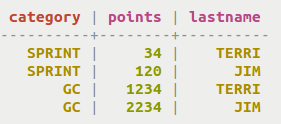
-
大きなテーブルの場合は、
LIMITを使用して取得する行の数を制限します。デフォルトの制限は10,000行です。データをサンプリングするには、小さい数を選択します。10,000行を超えるデータを取得するには、LIMITを大きな値に設定します。SELECT * From cycling.cyclist_name LIMIT 3;
-
ORDER BY句を使用すると、表示順を微調整できます。 パーティション・キーは、WHERE句で定義する必要があります。また、ORDER BY句は、順序指定に使用するクラスター化カラムを定義します。CREATE TABLE cycling.cyclist_cat_pts ( category text, points int, id UUID,lastname text, PRIMARY KEY (category, points) ); SELECT * FROM cycling.cyclist_cat_pts WHERE category = 'GC' ORDER BY points ASC;
-
タプルは、全体で取得されます。この例では、
ASを使用してタプル名のヘッダーを変更します。SELECT race_name, point_id, lat_long AS CITY_LATITUDE_LONGITUDE FROM cycling.route;
-
DataStax Enterprise 5.1以降では、
PER PARTITION LIMITオプションを使用して、クエリーで各パーティションから返される行数の最大数を設定します。これは、パーティションが正しく分割されていればクエリーで「上位3位」を選択できるので、興味深い手法です。データを複数のパーティションにソートし、データを挿入するテーブルを作成します。CREATE TABLE cycling.rank_by_year_and_name ( race_year int, race_name text, cyclist_name text, rank int, PRIMARY KEY ((race_year, race_name), rank) );race_year | race_name | rank | cyclist_name -----------+--------------------------------------------+------+---------------------- 2014 | 4th Tour of Beijing | 1 | Phillippe GILBERT 2014 | 4th Tour of Beijing | 2 | Daniel MARTIN 2014 | 4th Tour of Beijing | 3 | Johan Esteban CHAVES 2015 | Giro d'Italia - Stage 11 - Forli > Imola | 1 | Ilnur ZAKARIN 2015 | Giro d'Italia - Stage 11 - Forli > Imola | 2 | Carlos BETANCUR 2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 1 | Benjamin PRADES 2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 2 | Adam PHELAN 2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 3 | Thomas LEBAS -
次に、
PER PARTITION LIMITを使用して、レース年とレース名のペアごとに上位2名のサイクリストを取得します。SELECT * FROM cycling.rank_by_year_and_name PER PARTITION LIMIT 2;race_year | race_name | rank | cyclist_name -----------+--------------------------------------------+------+------------------- 2014 | 4th Tour of Beijing | 1 | Phillippe GILBERT 2014 | 4th Tour of Beijing | 2 | Daniel MARTIN 2015 | Giro d'Italia - Stage 11 - Forli > Imola | 1 | Ilnur ZAKARIN 2015 | Giro d'Italia - Stage 11 - Forli > Imola | 2 | Carlos BETANCUR 2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 1 | Benjamin PRADES 2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 2 | Adam PHELAN