アーキテクチャーの概要
DataStax Enterpriseを理解して使用するための基本情報。
DataStax Enterpriseの仕組み
Apache Cassandra™の優れたディストリビューションを搭載したDataStax Enterpriseでは、コードがシームレスに統合されるため、アプリケーションでさまざまなテクニックを活用してモバイル・アプリやオンライン・アプリケーションを作成することが可能です。DSEは、単一障害点なしで複数のノードにわたってビッグ・データのワークロードを処理するように設計されています。そのアーキテクチャーは、システムおよびハードウェアには障害が発生するものだということを前提にしています。
DSEは、クラスター内のすべてのノードにデータが分散されるピアツーピア分散システムを同種ノードに横断的に採用することによって障害の問題に対処します。各ノードは、ピアツーピアのゴシップ通信プロトコルを使用して、クラスター全体でそれ自体および他のノードに関する状態情報を頻繁に交換します。各ノードでシーケンシャルに書き込まれるコミット・ログにより、データの永続性を保証するために書き込みアクティビティが捕捉されます。データは、その後インデックスが付けられ、memtableと呼ばれるライトバック・キャッシュに似たインメモリー構造に書き込まれます。メモリー構造が満杯になると、データはSSTableデータ・ファイル形式でディスクに書き込まれます。すべての書き込みは自動的にパーティションされ、クラスター全体にレプリケーションされます。DSEは、コンパクションを使用して、定期的にSSTableを統合し、トゥームストーンによって削除とマークされた古いデータを破棄します。クラスター全体のデータの整合性を確保するために、さまざまなリペア・メカニズムが採用されています。
DSEデータベースは、行ストア・データベースにパーティションされます。ここで、行は必要なプライマリ・キーを使用してテーブルに構成されています。データベースのアーキテクチャーでは、権限を与えられたすべてのユーザーが、CQL言語を使用して任意のデータ・センターの任意のノードに接続し、データにアクセスできます。使い勝手がいいように、CQLはSQLと同じような構文を使用し、テーブル・データと連動します。開発者は、cqlsh、DataStax Studio、DataStax DevCenter、およびアプリケーション言語向けのドライバー経由でCQLにアクセスできます。通常、クラスターには、さまざまなテーブルで構成されたアプリケーションごとに1つのキースペースがあります。
クライアントの読み取りまたは書き込み要求は、クラスター内の任意のノードに送信できます。要求を持つクライアントがノードに接続されると、そのノードは、クライアントの特定の操作のコーディネーターとしての役目を果たします。コーディネーターは、クライアント・アプリケーションと、要求されたデータを所有するノード間で、代理人としての役目を果たします。コーディネーターは、クラスターがどのように構成されているかに基づいて、リングのどのノードが要求を受け取るかを決定します。
主な構成要素
- ノード
- データの格納先。これは基本的なデータベース・インフラストラクチャー・コンポーネントです。
- クラスター
- データを格納するための分散ノードのグループ。クラスターは、1つのノード、1つのデータ・センター、または複数のデータ・センターを持つことができます。
- データ・センター
- レプリケーションを目的にクラスター内でまとめて構成された関連ノードのグループ。データ・センターは、物理的なデータ・センターまたは仮想データ・センターが可能です。別々のデータ・センターを使用することで、トランザクションが他のワークロードの影響を受けるのを防ぎ、レイテンシーを低くします。レプリケーション係数に基づいて、複数のデータ・センターにデータが書き込まれます。データ・センターが複数の物理的な所在地をまたぐことがあってはなりません。
- レプリケーション
- 複数のノードにあるデータのコピーを格納するプロセス。レプリケーションにより、信頼性とフォールト・トレランスが確保されます。コピーの数はレプリケーション係数により設定されます。
- コミット・ログ
- すべてのデータは、永続性のためにまずコミット・ログに書き込まれます。そのすべてのデータがSSTableにフラッシュされた後、コミット・ログをアーカイブ、削除、または再利用できます。
- SSTable
- ソート済み文字列テーブル(SSTable)は、データベースがmemtableを定期的に書き込む不変データ・ファイルです。SSTableは追加書き込みのみで、ディスクにシーケンシャルに格納され、データベース・テーブルごとに維持されます。
- CQLテーブル
- テーブル行単位でフェッチされる、順序付きのカラムの集まりです。テーブルはカラムから構成され、プライマリ・キーを持ちます。
DataStax Enterpriseを構成するための主なコンポーネント
- ゴシップ
- DSEクラスターに属する他のノードの場所と状態の情報を探して共有するピアツーピア通信プロトコルです。ゴシップ情報は、ノードが再起動されるとすぐに使用できるように、各ノードによってローカルに保持されます。
- パーティショナー
- パーティショナーは、ロード・バランス機能のために、クラスター内のノード全体にデータを均等に分散します。
- レプリケーション係数
- レプリケーションは、複数のノードにあるデータのコピーを格納するプロセスです。レプリケーションにより、信頼性とフォールト・トレランスが確保されます。コピーの数はレプリケーション係数により設定されます。
- レプリカ配置ストラテジ
- レプリケーション・ストラテジは、レプリカをどのノードに配置するかを決定します。データの最初のレプリカは、単に最初のコピーであるということだけです。いかなる意味合いにおいても独自性を持つわけではありません。将来拡張する必要が生じたときに、複数のデータ・センターに拡張するのが簡単なため、ほとんどのデプロイには、NetworkTopologyStrategyを強く推奨します。
- スニッチ
- スニッチは、ノードのIPアドレスから、ラックやデータ・センターなどの物理位置および仮想位置にマップします。スニッチは、データベースに対してネットワーク・トポロジーを伝えることで、要求を効率的にルーティングさせ、マシンをデータ・センターおよびラックにグループ分けしてデータベースがレプリカを分散できるようにします。
- cassandra.yaml構成ファイル
- クラスターの初期化プロパティの設定、テーブルのキャッシング・パラメーター、調整およびリソース利用のプロパティ、タイムアウト設定、クライアント接続、バックアップ、およびセキュリティのためのメインの構成ファイルです。デフォルトでは、ノードは管理対象のデータをcassandra.yamlファイルに設定されているディレクトリーに格納するように構成されます。
- dse.yaml構成ファイル
- DSE Advanced Security(DSE拡張セキュリティ)、DSE Search、DSE Graph、およびDSE Analytics用の構成ファイル。
- システム・キースペース・テーブルのプロパティ
- ストレージ構成属性は、プログラムで、またはCQLなどのクライアント・アプリケーションを使用して、キースペースまたはテーブルごとに設定します。
データ・モデリングの基本概念
- データ・モデルの設計
- データ・モデルの設計は、リレーショナル・データベースで行うような実体と関係のモデリングではなく、実行するクエリーに基づいています。
- Keyspace
- リレーショナル・データベースのスキーマに類似した、データの最も外側のグループ化。すべてのテーブルはキースペース内部に格納されます。キースペースは、レプリケーション用の定義コンテナーです。
- テーブル
- テーブルにはプライマリ・キーに基づいてデータが格納されます。プライマリ・キーは、パーティション・キーとオプションのクラスター化カラムで構成されます。
- パーティション・キーは、データが格納されるノードを定義します。
- クラスター化カラムは、パーティション内での行の順序を定義します。
- プライマリ・キーは、テーブル内のデータにアクセスするために使用されます。注: 以前のバージョンのDataStax EnterpriseとApache Cassandra™では、カラム・ファミリーは多くの点でテーブルと同義でした。
図 1. テーブル 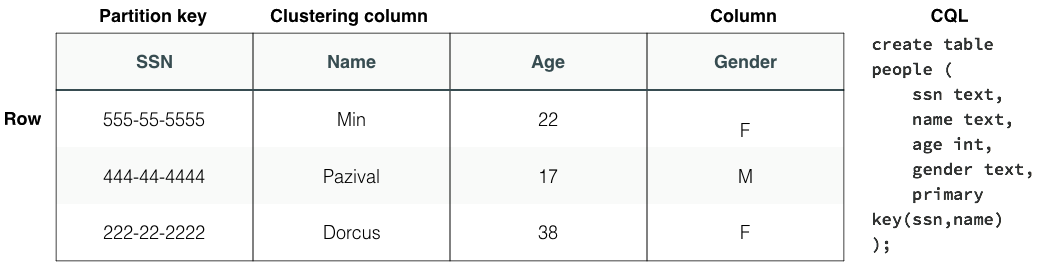
- データ・モデリングに関するその他の情報
-
- CQLドキュメントでのデータ・モデリングの概念。
- CQLドキュメントでCQLを使用する。
- 「時系列データ・モデリングの概要」ホワイト・ペーパー。
- 「ユーザー・プロファイル・データ・モデリングの概要」ホワイト・ペーパー。
- 「スーパー・モデラーになる」ウェビナー。
- 「使用されないデータ・モデル、有効期間の長いデータ・モデル」ウェビナー。
- C* Summit 2013:「次に来るデータ・モデル」ウェビナー。
|
パッケージ・インストールInstaller-Servicesインストール |
/etc/dse/cassandra/cassandra.yaml |
|
tarボール・インストールInstaller-No Servicesインストール |
installation_location/resources/cassandra/conf/cassandra.yaml |