グラフ・データ・モデリングの紹介
グラフ・データ・モデルの一部に対する簡単な紹介。
グラフ・データベースのデータ・モデリングは、一般的に単純なプロセスです。ホワイトボードに書き込まれた情報が、頂点と線で結ばれており、グラフ・データベースのデータ・モデルで90%が完了していると考えてください。

Julia Childは、多くのレシピを生み出した有名なシェフでした。彼女が1961年にアメリカの読者のために作り出したレシピの1つが、ビーフ・ブルギニヨンでした。上の図では、Julia Childという人物が、ビーフ・ブルギニヨンのレシピに結びつけられています。人物とレシピは2種類の頂点であり、頂点に隣接する線(エッジ)は関係を「created」として識別しています。頂点とエッジには、人物の名前、レシピ名、エッジに関連付けられた日付など、関連付けられたプロパティがあります。プロパティは、グラフに関するクエリーで使用される基本要素であり、プロパティ・キーとプロパティ値で構成されます。グラフ・データベースでは、頂点がエッジに入射し、エッジが頂点に入射します。頂点は別の頂点に隣接しています。このデータ・モデルの一般化された図を以下に示します。
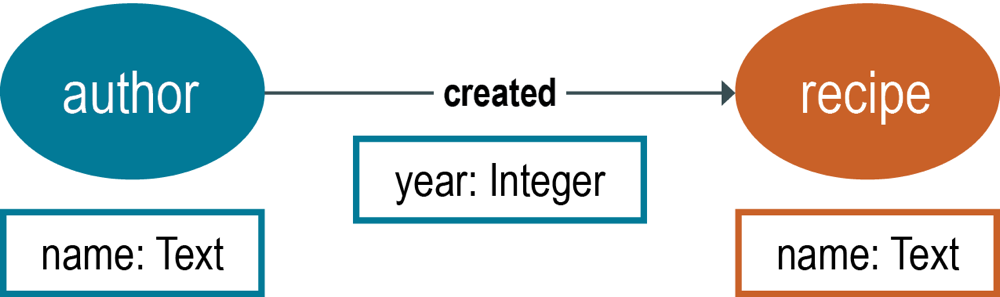
各頂点は、特定のタイプの頂点を識別するために、頂点ラベルに割り当てられています。この例での頂点ラベルは、authorとrecipeです。各エッジにも、そのタイプを指定するエッジ・ラベルが必要です。エッジ・ラベルはcreatedと表示されています。示されているプロパティは、nameとyearです。
DSE Graphでは、グラフごとに入力できる頂点ラベル数は200までです。
さらに複雑なグラフでは、複数のエッジを頂点に接続でき、複数のプロパティを頂点とエッジに割り当てることができます。プロパティとエッジの両方が、複数のカーディナリティを持つことができます。頂点プロパティは、プロパティのプロパティであるメタプロパティを持つことができます。
知っておくべき重要な概念は、アドレス指定可能な要素としての頂点とエッジの性質です。インデックスはグラフをクエリーする際に極めて重要な役割を果たし、頂点ラベルはすべてのインデックスの一部でなければなりません。グローバルにアドレス指定できるのは頂点だけですが、エッジはローカルのみでアドレス指定が可能です。実際に、この状況が意味することは、エッジにローカルにインデックスを付けることができるのは、特定の頂点ラベルに対してのみということです。エッジは頂点の関係に関するものであり、第2クラスの市民として分類されます。頂点はエンティティであり、すべてのグラフ操作が利用可能な第1クラスの市民です。エッジの第2クラスの市民の性質を示すために、エッジのメタプロパティをインデックス化して、クエリーの絞り込みに使用することはできません。メタプロパティに格納されたデータをクエリーの絞り込みに使用する必要がある場合は、これらのエッジを頂点として上手くモデル化することです。
残り10%の努力に関しては、ホワイトボードのグラフの一側面が頂点かエッジかを最適化することが最も重要な要素となります。エッジとして使用される一側面が数回以上使用されるようになると、そのエッジは頂点になるはずです。たとえば、頂点プロパティを作成者に追加して、作成者の出身国を追加することができます。しかし、多くの作成者の出身国は中国やフランスなどの同じ国であるため、場所の頂点タイプを作成した方が後でクエリー操作を行うのに良いかもしれません。