概要 - Gremlin Consoleの概要
データを挿入し、探索を実行します。
グラフ・データベースは、オブジェクト間の単純な関係や複雑な関係を発見する上で役立ちます。関係は、オブジェクトがオブジェクト同士およびオブジェクトの環境と対話する方法の基本となるものです。グラフ・データベースは、オブジェクト間の関係を完璧に表現することができます。
- 頂点
- 頂点とは、人、場所、自動車、レシピ、または名詞として考えられるその他すべてのものを含むオブジェクトです。
- エッジ
- エッジは、2つの頂点の間の関係を定義します。人は、ソフトウェアを作成できます。また、作者は本を執筆することができます。エッジを定義するときには動詞を考えてください。
プロパティ・グラフは一般的に、サイズがかなり大きくなりますが、グラフのクエリーの性質は、そのグラフに頂点、エッジ、または頂点とエッジの両方が多数含まれるかどうかによって異なります。グラフ・データベースの概念をわかりやすく説明できるよう、サイズの小さい「トイ」グラフを使用することにします。この例では、世界の食べ物を探索します。
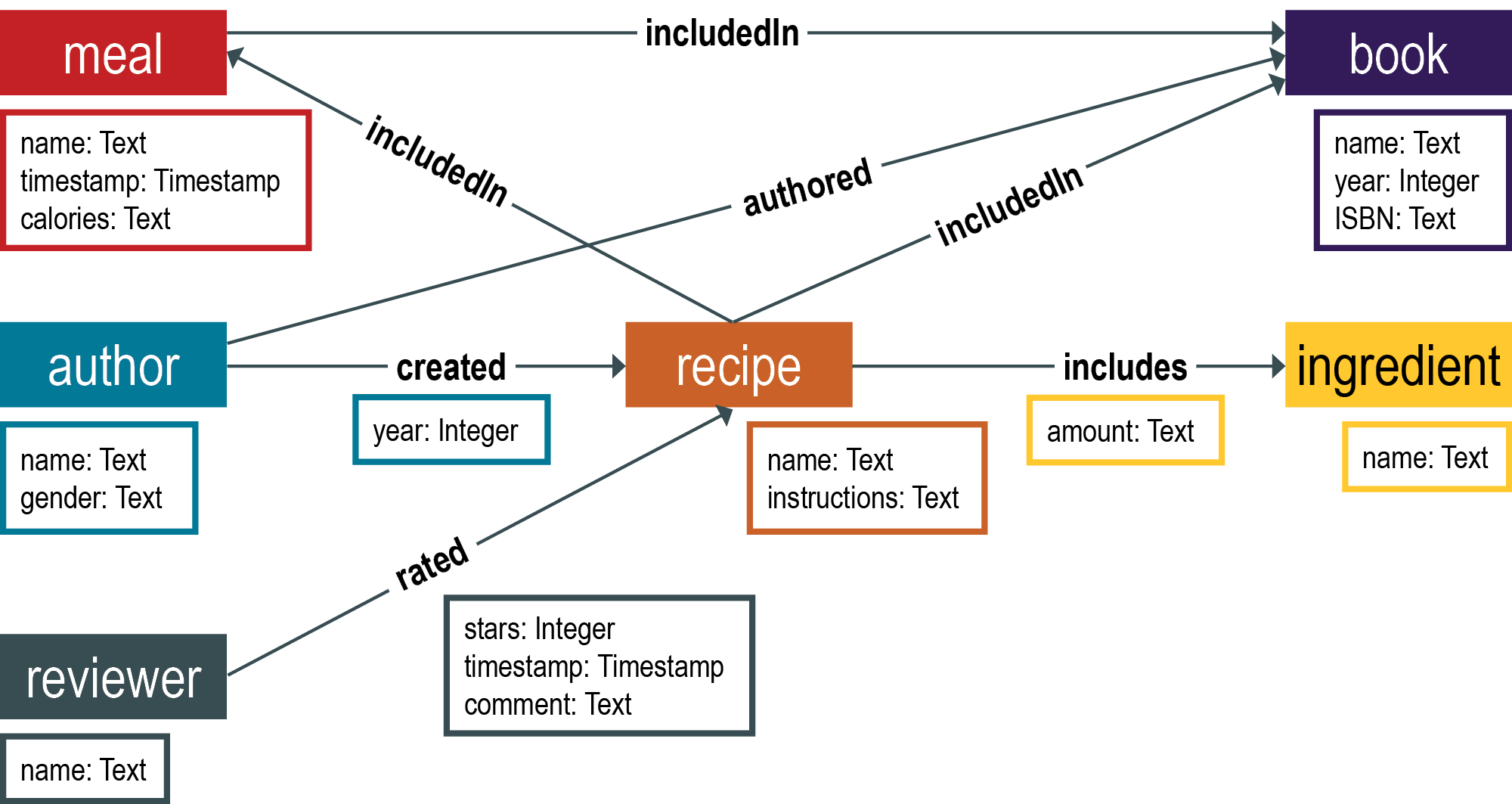
グラフ・データベース内の頂点とエッジのタイプを区別できるよう、各要素にラベルが付けられています。作者に関する情報を格納する頂点には、authorというラベルが付けられています。グラフ内のエッジには、authoredというラベルが付けられています。ラベルは、グラフを構成する頂点とエッジのタイプを指定します。適切なラベルを指定することは、グラフ・データ・モデリングにおける重要なステップです。
通常、頂点とエッジにはプロパティがあります。たとえば、author頂点はnameというプロパティを持つ場合があります。author頂点のプロパティの例としては、これ以外にも性別や現在の職業などがあります。エッジにもプロパティがあります。createdエッジは、隣接するrecipe頂点が作成された日時を識別するtimestampプロパティを持つ場合があります。
グラフ・データベース内の情報は、グラフ探索を使用して取得できます。グラフ探索では、探索の開始点を定義し、結果をフィルター処理して、グラフ・データに関するクエリーの回答を見つけることのできる単一または一連の探索ステップによりグラフをウォークスルーします。
グラフ探索を実行して情報を取得するには、最初にデータを挿入する必要があります。このセクションに記載されている手順を使用すると、最小限の構成とスキーマの作成でDSE Graphの基礎を理解することができます。
手順
- DSEをインストールします。
- DSE Graphを起動します。
-
Gremlin Consoleを起動します。
$ bin/dse gremlin-console
\,,,/ (o o) -----oOOo-(3)-oOOo-----plugin activated: tinkerpop.tinkergraph plugin activated: tinkerpop.server plugin activated: tinkerpop.utilities ==>Connected - localhost/127.0.0.1:8182-[4edf75f9-ed27-4add-a350-172abe37f701] ==>Set remote timeout to 2147483647ms ==>All scripts will now be sent to Gremlin Server - [localhost/127.0.0.1:8182]-[4edf75f9-ed27-4add-a350-172abe37f701] - type ':remote console' to return to local mode gremlin>
Gremlin Consoleは、プロンプトで入力されたすべてのコマンドを、コマンドを処理するGremlin Serverに送信します。DSE Graphは、各DSEノード上でGremlin Server tinkerpop.serverを実行します。Gremlin ConsoleはGremlin Serverに自動的に接続します。DSEデータベースのキースペースごとに1つのグラフ・インスタンスとして格納されるグラフを作成する必要があります。
Gremlin Consoleはremoteモードで自動的に実行され、Gremlin Serverでコマンドを処理します。Gremlin Consoleはデフォルトにより、リモート・サーバーでコマンドを実行するセッションを開きます。Gremlin Consoleは以下を使用して、ローカルでコマンドを実行するように切り替えることができます。
このコマンドの実行後は、すべてのコマンドをリモートで送信する必要があります。コマンドを再び使用すると、コンテキストがGremlin Serverに切り替わります。:remote console -
データを保持するグラフを作成します。systemコマンドは、DSE Graph内のグラフに影響するコマンドを実行するために使用されます。
gremlin> system.graph('test').create()==>null
グラフが作成されたら、グラフ探索を実行できるように、グラフ探索gを構成します。グラフ探索は、グラフ・データに対するクエリーを実行し、結果を返します。グラフ探索は、標準OLTP探索エンジンである特定の探索ソースに結合します。
-
これまでに作成したすべてのグラフをリストするには、以下を使用します。
system.graphs()==>test ==>anotherTest
-
グラフ探索
gを構成し、デフォルトのグラフ探索設定であるtest.gを使用します。このステップにより、暗黙的なgraphオブジェクトも作成されます。gremlin> :remote config alias g test.g==>g=test.g
注: グラフ探索が:remote config alias g some_graph.gコマンドによって別名で作成されている場合、このコマンドは使用できません。システム・コマンドにアクセスするには、:remote config alias resetを使用して別名をリセットします。graphコマンドは、通常は頂点またはエッジをデータベースに追加するか、他のグラフ情報を取得します。gコマンドは、通常は結果を取得するためのクエリーを実行します。
-
まず、スキーマ・モードをDevelopmentに設定します。Developmentはより寛大なモードであるため、テスト中にいつでもスキーマを追加できます。また、広範なグラフ探索でのデータを検査するためのテスト目的でフルスキャンを実行することもできます。実稼働環境に対してはProductionスキーマ・モードを設定し、異常な動作につながるような対話的スキーマの変更を避ける必要があります。また、フルスキャンはオフにします。
schema.config().option('graph.schema_mode').set('Development') schema.config().option('graph.allow_scan').set('true') -
探索ステップ
count()を使用して、グラフ内に存在する頂点の数を確認します。まだデータを追加していないため、現在の数はゼロになるはずです。グラフ探索gはV()と連鎖して、すべての頂点が取得されます。またcount()によって頂点の数が取得されます。gremlin> g.V().count()==>0
注:注:
g.V().count()を使用してグラフのフルスキャンを行うクエリーは、大きなグラフでは実行しないでください。複数のDSEノードが構成されている場合、この探索手順ではグラフ・データを含むクラスター内のすべてのノードの全パーティションを徹底的にウォークスルーします。
単純な例は、2つの頂点、1人の作者(Julia Child)、1冊の本(The Art of French Cooking, Vol. 1)、およびこれらの間のエッジで構成され、Julia Childがその本の作者であることが識別されます。以下に示すように、スキーマを作成せずに3つの要素を作成できます。ただし以下で説明するように、DSE Graphはスキーマに関してベストの推測を行います。
-
まず、Julia Childの頂点を作りましょう。頂点ラベルはauthorで、nameとgenderに対してキーと値のプロパティのペアが2つ作成されます。頂点ラベルを設定する、キーと値のペアに対してキーを指定するためのラベルの使用に注目してください。コマンドを実行し、生、テーブル、およびグラフの各ビューを表示するためのボタンを使用して結果を確認します。
gremlin> juliaChild = graph.addVertex(label,'author', 'name','Julia Child', 'gender','F')==>v[{~label=author, member_id=0, community_id=1080937600}]それぞれのビューには以下の同一の情報が表示されます。- member_id、community_id、およびlabelで構成される自動生成id
- member_idとcommunity_idは、グラフ内の頂点をグループ化するために使用されます(詳細情報)。
注: DSE 6.0では、標準の自動生成IDは廃止されました。カスタムIDにはいくつかの変更が加えられ、次のコマンドで示されるように、プロパティ・キーは異なる種類の情報に対して再利用できます。プロパティは複数の頂点ラベルで使用できるという点において「グローバル」ですが、グラフ探索のプロパティを指定する際、それは常に頂点ラベルと併用されるということを理解しておくことが重要です。partitionKeyおよびclusteringKeyを使用して頂点IDを指定する方法が一般的になる可能性が高くなります。次のコマンドを実行してbook頂点を作成します。コマンドは2回実行しないでください。実行すると、重複が発生します。
- member_id、community_id、およびlabelで構成される自動生成id
-
本をグラフ内に作成します。
gremlin> artOfFrenchCookingVolOne = graph.addVertex(label, 'book','name', 'The Art of French Cooking, Vol. 1', 'year', 1961)==>v[{~label=book, member_id=1, community_id=1080937600}]author頂点と同様に、作成されたbook頂点に関するid情報が表示されます。
次の2つのコマンドを実行します。最初のコマンドは、author頂点とbook頂点の間のエッジを作成します。2番目のコマンドは、
valueMap()を使用して2つの頂点を取得するグラフ探索です。author頂点のプロパティ・キー情報を確認するには、valueMap()を使用します。探索gは、探索ステップV()ですべての頂点を確認し、探索ステップvalueMap()を使用して、各頂点のプロパティ値のキーと値のリストを出力します。 -
エッジを作成し、頂点のデータを表示します。
gremlin> juliaChild.addEdge('authored', artOfFrenchCookingVolOne) gremlin> g.V().valueMap()gremlin> juliaChild.addEdge('authored', artOfFrenchCookingVolOne) ==>e[{out_vertex={~label=author, member_id=0, community_id=1080937600}, local_id=6bd73210-0e70-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=1, community_id=1080937600}, ~type=authored}][{~label=author, member_id=0, community_id=1080937600}-authored->{~label=book, member_id=1, community_id=1080937600}] gremlin> g.V().valueMap() ==>{gender=[F], name=[Julia Child]} ==>{name=[The Art of French Cooking, Vol. 1], timestamp=[1961]}注意: クエリー対象の頂点またはエッジに非常に多くのプロパティ・キーがある場合、プロパティを指定せずにvalueMap()を指定すると、スロー・クエリーのレイテンシーが発生する可能性があります。valueMap('name')のように特定のプロパティを指定できます。これでデータが用意されました。キーと値のペアは、作成されたauthor頂点に対するnameとgenderのプロパティ・キーとその値に加えて、作成されたbook頂点に対するnameとtimestampを識別します。
-
さらに複雑な探索の基本的な開始点となるグラフ探索では、
has()ステップを頂点ラベルauthorおよびプロパティname = Julia Childとともに使用して、特定の頂点を識別します。この一般的なグラフ探索は、特定の情報でグラフの検索を絞り込むために使用されます。gremlin> g.V().has('author', 'name', 'Julia Child')==>v[{~label=author, member_id=0, community_id=1080937600}]idは自動的に生成され、頂点ラベルおよびグラフ内の頂点の場所に関連付けられている2つのコンポーネントで構成されます。idコンポーネントについては、「グラフ探索の構造」で説明されています。
-
特定のプロパティ・キーの値のみが必要な場合は、探索ステップの
values()ステップが使用されます。以下のこの例では、すべての頂点のnameが取得されます。gremlin> g.V().values('name')頂点は2つのみ存在するため、2つの結果が書き込まれます。複数の頂点が存在する場合は、
nameを含むすべての頂点の結果が探索ステップによって返されます。==>Julia Child ==>The Art of French Cooking, Vol. 1 -
エッジの情報を取得することもできます。次のコマンドは、すべてのエッジをフィルター処理して
authoredエッジ・ラベルを持つエッジを検索します。エッジの情報には、内向きおよび外向きの頂点に関する詳細のほか、エッジ・パラメーターであるid、label、およびtypeが表示されます。gremlin> g.E().hasLabel('authored')==>e[{out_vertex={~label=author, member_id=0, community_id=1080937600}, local_id=6bd73210-0e70-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=1, community_id=1080937600}, ~type=authored}] [{~label=author, member_id=0, community_id=1080937600}-authored->{~label=book, member_id=1, community_id=1080937600}] -
探索ステップ
count()は頂点の数とエッジの数の両方をカウントする場合に便利です。エッジをカウントするには、V()ではなくE()を使用します。エッジは1つであるはずです。gremlin> g.E().count()==>1 -
このチュートリアルの始めに実行した頂点のカウントの探索を再実行すると、2つの頂点が得られます。
gremlin> g.V().count()==>2
さらにデータをグラフに追加する前に、ここでスキーマについて話をしましょう。スキーマは、グラフで使用される、可能なプロパティとデータ型を定義するために使用されます。これらのプロパティは、次に頂点ラベルとエッジ・ラベルの定義で使用されます。スキーマの作成における最後の重要なステップは、インデックスの作成です。インデックスは、グラフ探索の効率と速度を向上させる上で、重要な役割を果たします。
詳細情報は、「スキーマの作成」および「インデックスの作成」に関するドキュメントに含まれています。
まず、プロパティ・キー用のスキーマを作成しましょう。次の2つのセル内の最初のコマンドは、最初の2つの頂点とエッジを作成したときに設定されたスキーマを消去します。スキーマの作成が完了したら、これらの要素のデータを長いスクリプトに再入力します。
-
以前のスキーマを消去します。Nullの値が返された場合は、コマンドに成功したことを意味します。
gremlin> schema.clear()==>null -
プロパティ・キーを作成します。
// Property Keys // Check for previous creation of property key with ifNotExists() schema.propertyKey('name').Text().ifNotExists().create() schema.propertyKey('gender').Text().create() schema.propertyKey('instructions').Text().create() schema.propertyKey('category').Text().create() schema.propertyKey('year').Int().create() schema.propertyKey('timestamp').Timestamp().create() schema.propertyKey('ISBN').Text().create() schema.propertyKey('calories').Int().create() schema.propertyKey('amount').Text().create() schema.propertyKey('stars').Int().create() // single() is optional, as it is the default schema.propertyKey('comment').Text().single().create() // Example of a multiple property that can have several values // schema.propertyKey('nickname').Text().multiple().create() // Next 2 lines define two properties, then create a meta-property 'livedIn' on 'country' // A meta-property is a property of a property // EX: 'livedIn': '1999-2005' 'country': 'Belgium' schema.propertyKey('livedIn').Text().create() schema.propertyKey('country').Text().multiple().properties('livedIn').create()// A series of null returns will mark the successful completion of all property key creation ==>null各プロパティは、データ型を使用して定義する必要があります。DSE Graphデータ型は、DSEデータベースのデータ型と整合しています。ここで使用されるデータ型は、Text、Int、およびTimestampです。デフォルトでは、プロパティには単一のカーディナリティがありますが、複数のカーディナリティを使用して定義することもできます。複数のカーディナリティを使用すると、1つのプロパティに複数の値を割り当てることができます。
また、プロパティは独自のプロパティ、つまりメタプロパティを持つことができます。メタプロパティは、1つ下のレベルにのみネストでき、個々のプロパティに情報を入力する上で役立ちます。プロパティ・キーは、既に存在する可能性のある定義を上書きするのを避けるために、追加の
ifNotExists()メソッドを使用して作成できます。プロパティ・キーを作成した後は、頂点ラベルとエッジ・ラベルを定義できます。 -
頂点ラベルとエッジ・ラベルを作成します。
// Vertex Labels schema.vertexLabel('author').ifNotExists().create() schema.vertexLabel('recipe').create() // Example of creating vertex label with properties // schema.vertexLabel('recipe').properties('name','instructions').create() // Example of adding properties to a previously created vertex label // schema.vertexLabel('recipe').properties('name','instructions').add() schema.vertexLabel('ingredient').create() schema.vertexLabel('book').create() schema.vertexLabel('meal').create() schema.vertexLabel('reviewer').create() // Example of custom vertex id: // schema.propertyKey('city_id').Int().create() // schema.propertyKey('sensor_id').Uuid().create() // schema().vertexLabel('FridgeSensor').partitionKey('city_id').clusteringKey('sensor_id').create() // Edge Labels schema.edgeLabel('authored').ifNotExists().create() schema.edgeLabel('created').create() schema.edgeLabel('includes').create() schema.edgeLabel('includedIn').create() schema.edgeLabel('rated').connection('reviewer','recipe').create()// A series of null returns will mark the successful completion of all vertex label and edge label creation ==>null頂点ラベルのスキーマはtypeラベルを定義し、頂点ラベルに関連付けられるプロパティをオプションで定義します。頂点ラベルを含むプロパティの関連付けを定義するために、2つのメソッドが用意されています。定義は、ラベルの作成中、または頂点ラベルの追加後に追加できます。
ifNotExists()メソッドは、任意のスキーマの作成に使用できます。DSE Graphでは、グラフごとに入力できる頂点ラベル数は200までです。
頂点idは自動的に生成されますが、必要に応じてカスタム頂点idを作成できます。このカスタム頂点id例についてはマニュアルでさらに詳しく説明されていますが、パーティション・キーとクラスター化キーを定義できることを覚えておいてください。
エッジ・ラベルのスキーマは、typeラベルを定義し、
connection()を使用してエッジ・ラベルにより接続される2つの頂点ラベルをオプションで定義します。ratedエッジ・ラベルは、外向き頂点ラベルreviewerと内向き頂点ラベルrecipeを持つ隣接する頂点の間のエッジを定義します。デフォルトでは、エッジには複数のカーディナリティがありますが、単一のカーディナリティを使用して定義することもできます。複数のカーディナリティを使用すると、複数のエッジに異なるプロパティ値を持たせる一方で、同じエッジ・ラベルを割り当てることができます。 -
インデックスを作成します。
// Vertex Indexes // Secondary schema.vertexLabel('author').index('byName').secondary().by('name').add() // Materialized schema.vertexLabel('recipe').index('byRecipe').materialized().by('name').add() schema.vertexLabel('meal').index('byMeal').materialized().by('name').add() schema.vertexLabel('ingredient').index('byIngredient').materialized().by('name').add() schema.vertexLabel('reviewer').index('byReviewer').materialized().by('name').add() // Search // schema.vertexLabel('recipe').index('search').search().by('instructions').asText().add() // schema.vertexLabel('recipe').index('search').search().by('instructions').asString().add() // If more than one property key is search indexed // schema.vertexLabel('recipe').index('search').search().by('instructions').asText().by('category').asString().add() // Property index using meta-property 'livedIn': schema.vertexLabel('author').index('byLocation').property('country').by('livedIn').add() // Edge Index schema.vertexLabel('reviewer').index('ratedByStars').outE('rated').by('stars').add()// A series of null returns will mark the successful completion of all index creation ==>nullインデックスの作成は、複雑で非常に重要なトピックです。ここでは、複数の種類のインデックスが作成されます。簡単に説明すると、セカンダリ・インデックスとマテリアライズド・インデックスは、DSEデータベースの組み込みインデックス作成機能を使用する2種類のインデックスです。検索インデックスは、SolrベースのDSE Searchを使用します。1つの頂点ラベルには1つのみの検索インデックスを使用できますが、複数のプロパティを含めることができます。プロパティ・インデックスを使用すると、メタプロパティのインデックスを作成できます。エッジ・インデックスを使用すると、エッジのプロパティのインデックスを作成できます。インデックスは、
add()を使用して、以前作成した頂点ラベルに追加されます。すべてのセルを実行してスキーマを作成した後は、次のコマンドを使用してスキーマを確認します。 -
スキーマを確認します。
gremlin> schema.describe()==>schema.propertyKey("instructions").Text().single().create() schema.propertyKey("livedIn").Text().single().create() schema.propertyKey("country").Text().multiple().properties("livedIn").create() schema.propertyKey("amount").Text().single().create() schema.propertyKey("gender").Text().single().create() schema.propertyKey("year").Int().single().create() schema.propertyKey("calories").Int().single().create() schema.propertyKey("stars").Int().single().create() schema.propertyKey("ISBN").Text().single().create() schema.propertyKey("name").Text().single().create() schema.propertyKey("comment").Text().single().create() schema.propertyKey("category").Text().single().create() schema.propertyKey("timestamp").Timestamp().single().create() schema.edgeLabel("authored").multiple().create() schema.edgeLabel("rated").multiple().properties("stars").create() schema.edgeLabel("includedIn").multiple().create() schema.edgeLabel("created").multiple().create() schema.edgeLabel("includes").multiple().create() schema.vertexLabel("meal").properties("name").create() schema.vertexLabel("meal").index("byMeal").materialized().by("name").add() schema.vertexLabel("ingredient").properties("name").create() schema.vertexLabel("ingredient").index("byIngredient").materialized().by("name").add() schema.vertexLabel("author").properties("country", "name").create() schema.vertexLabel("author").index("byName").secondary().by("name").add() schema.vertexLabel("author").index("byLocation").property("country").by("livedIn").add() schema.vertexLabel("book").create() schema.vertexLabel("recipe").properties("name").create() schema.vertexLabel("recipe").index("byRecipe").materialized().by("name").add() schema.vertexLabel("reviewer").properties("name").create() schema.vertexLabel("reviewer").index("byReviewer").materialized().by("name").add() schema.vertexLabel("reviewer").index("ratedByStars").outE("rated").by("stars").add() schema.edgeLabel("rated").connection("reviewer", "recipe").add()schema.describe()コマンドは、入力されたスキーマを再作成するために使用できるスキーマを表示します。スキーマを作成せずにデータを入力した場合、このコマンドは各プロパティに設定されているデータ型を確認します。現時点では、DSE Graphにおいて、一度作成したスキーマを変更することはできません。追加のプロパティ、頂点ラベル、エッジ・ラベル、およびインデックスは作成できますが、たとえば、プロパティのデータ型は変更できません。開発中および学習時はスキーマを作成せずにデータを入力すると便利ですが、実際のアプリケーションではそれを行わないことを強くお勧めします。このため、Productionモードではデータの読み込み後にスキーマを作成できないようになっています。
-
describe()リスト内で特定の型の項目のスキーマのみを検索する必要がある場合は、追加のステップで改行により出力を分割し、indexに対して示されているように、文字列をgrep検索できます。このノートブックに示されているように、GremlinはGroovyを使用するため、Groovyコマンドはグラフ探索を操作します。gremlin> schema.describe().split('\n').grep(~/.*index.*/)==>schema.vertexLabel("meal").index("byMeal").materialized().by("name").add() ==>schema.vertexLabel("ingredient").index("byIngredient").materialized().by("name").add() ==>schema.vertexLabel("author").index("byName").secondary().by("name").add() ==>schema.vertexLabel("author").index("byLocation").property("country").by("livedIn").add() ==>schema.vertexLabel("recipe").index("byRecipe").materialized().by("name").add() ==>schema.vertexLabel("reviewer").index("byReviewer").materialized().by("name").add() ==>schema.vertexLabel("reviewer").index("ratedByStars").outE("rated").by("stars").add() -
これでスキーマが作成されたため、次のスクリプトを使用してさらに頂点とエッジを追加します。recipeデータ・モデルでさらに多くの接続を検証するために、より多くの頂点とエッジをグラフに入力します。以下に示す情報を使用して、generateRecipe.groovyスクリプト・ファイルを作成します。最初のコマンド
g.V().drop().iterate()に注目してください。このコマンドは、新しいデータを読み込む前に、すべての頂点とエッジのデータをグラフから削除します。// Add all vertices and edges for Recipe g.V().drop().iterate() // author vertices juliaChild = graph.addVertex(label, 'author', 'name','Julia Child', 'gender', 'F') simoneBeck = graph.addVertex(label, 'author', 'name', 'Simone Beck', 'gender', 'F') louisetteBertholie = graph.addVertex(label, 'author', 'name', 'Louisette Bertholie', 'gender', 'F') patriciaSimon = graph.addVertex(label, 'author', 'name', 'Patricia Simon', 'gender', 'F') aliceWaters = graph.addVertex(label, 'author', 'name', 'Alice Waters', 'gender', 'F') patriciaCurtan = graph.addVertex(label, 'author', 'name', 'Patricia Curtan', 'gender', 'F') kelsieKerr = graph.addVertex(label, 'author', 'name', 'Kelsie Kerr', 'gender', 'F') fritzStreiff = graph.addVertex(label, 'author', 'name', 'Fritz Streiff', 'gender', 'M') emerilLagasse = graph.addVertex(label, 'author', 'name', 'Emeril Lagasse', 'gender', 'M') jamesBeard = graph.addVertex(label, 'author', 'name', 'James Beard', 'gender', 'M') // book vertices artOfFrenchCookingVolOne = graph.addVertex(label, 'book', 'name', 'The Art of French Cooking, Vol. 1', 'year', 1961) simcasCuisine = graph.addVertex(label, 'book', 'name', "Simca's Cuisine: 100 Classic French Recipes for Every Occasion", 'year', 1972, 'ISBN', '0-394-40152-2') frenchChefCookbook = graph.addVertex(label, 'book', 'name','The French Chef Cookbook', 'year', 1968, 'ISBN', '0-394-40135-2') artOfSimpleFood = graph.addVertex(label, 'book', 'name', 'The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution', 'year', 2007, 'ISBN', '0-307-33679-4') // recipe vertices beefBourguignon = graph.addVertex(label, 'recipe', 'name', 'Beef Bourguignon', 'instructions', 'Braise the beef. Saute the onions and carrots. Add wine and cook in a dutch oven at 425 degrees for 1 hour.') ratatouille = graph.addVertex(label, 'recipe', 'name', 'Rataouille', 'instructions', 'Peel and cut the eggplant. Make sure you cut eggplant into lengthwise slices that are about 1-inch wide, 3-inches long, and 3/8-inch thick') saladeNicoise = graph.addVertex(label, 'recipe', 'name', 'Salade Nicoise', 'instructions', 'Take a salad bowl or platter and line it with lettuce leaves, shortly before serving. Drizzle some olive oil on the leaves and dust them with salt.') wildMushroomStroganoff = graph.addVertex(label, 'recipe', 'name', 'Wild Mushroom Stroganoff', 'instructions', 'Cook the egg noodles according to the package directions and keep warm. Heat 1 1/2 tablespoons of the olive oil in a large saute pan over medium-high heat.') spicyMeatloaf = graph.addVertex(label, 'recipe', 'name', 'Spicy Meatloaf', 'instructions', 'Preheat the oven to 375 degrees F. Cook bacon in a large skillet over medium heat until very crisp and fat has rendered, 8-10 minutes.') oystersRockefeller = graph.addVertex(label, 'recipe', 'name', 'Oysters Rockefeller', 'instructions', 'Saute the shallots, celery, herbs, and seasonings in 3 tablespoons of the butter for 3 minutes. Add the watercress and let it wilt.') carrotSoup = graph.addVertex(label, 'recipe', 'name', 'Carrot Soup', 'instructions', 'In a heavy-bottomed pot, melt the butter. When it starts to foam, add the onions and thyme and cook over medium-low heat until tender, about 10 minutes.') roastPorkLoin = graph.addVertex(label, 'recipe', 'name', 'Roast Pork Loin', 'instructions', 'The day before, separate the meat from the ribs, stopping about 1 inch before the end of the bones. Season the pork liberally inside and out with salt and pepper and refrigerate overnight.') // ingredients vertices beef = graph.addVertex(label, 'ingredient', 'name', 'beef') onion = graph.addVertex(label, 'ingredient', 'name', 'onion') mashedGarlic = graph.addVertex(label, 'ingredient', 'name', 'mashed garlic') butter = graph.addVertex(label, 'ingredient', 'name', 'butter') tomatoPaste = graph.addVertex(label, 'ingredient', 'name', 'tomato paste') eggplant = graph.addVertex(label, 'ingredient', 'name', 'eggplant') zucchini = graph.addVertex(label, 'ingredient', 'name', 'zucchini') oliveOil = graph.addVertex(label, 'ingredient', 'name', 'olive oil') yellowOnion = graph.addVertex(label, 'ingredient', 'name', 'yellow onion') greenBean = graph.addVertex(label, 'ingredient', 'name', 'green beans') tuna = graph.addVertex(label, 'ingredient', 'name', 'tuna') tomato = graph.addVertex(label, 'ingredient', 'name', 'tomato') hardBoiledEgg = graph.addVertex(label, 'ingredient', 'name', 'hard-boiled egg') eggNoodles = graph.addVertex(label, 'ingredient', 'name', 'egg noodles') mushroom = graph.addVertex(label, 'ingredient', 'name', 'mushrooms') bacon = graph.addVertex(label, 'ingredient', 'name', 'bacon') celery = graph.addVertex(label, 'ingredient', 'name', 'celery') greenBellPepper = graph.addVertex(label, 'ingredient', 'name', 'green bell pepper') groundBeef = graph.addVertex(label, 'ingredient', 'name', 'ground beef') porkSausage = graph.addVertex(label, 'ingredient', 'name', 'pork sausage') shallot = graph.addVertex(label, 'ingredient', 'name', 'shallots') chervil = graph.addVertex(label, 'ingredient', 'name', 'chervil') fennel = graph.addVertex(label, 'ingredient', 'name', 'fennel') parsley = graph.addVertex(label, 'ingredient', 'name', 'parsley') oyster = graph.addVertex(label, 'ingredient', 'name', 'oyster') pernod = graph.addVertex(label, 'ingredient', 'name', 'Pernod') thyme = graph.addVertex(label, 'ingredient', 'name', 'thyme') carrot = graph.addVertex(label, 'ingredient', 'name', 'carrots') chickenBroth = graph.addVertex(label, 'ingredient', 'name', 'chicken broth') porkLoin = graph.addVertex(label, 'ingredient', 'name', 'pork loin') redWine = graph.addVertex(label, 'ingredient', 'name', 'red wine') // meal vertices SaturdayFeast = graph.addVertex(label, 'meal', 'name', 'Saturday Feast', 'timestamp', '2015-11-30', 'calories', 1000) EverydayDinner = graph.addVertex(label, 'meal', 'name', 'EverydayDinner', 'timestamp', '2016-01-14', 'calories', 600) JuliaDinner = graph.addVertex(label, 'meal', 'name', 'JuliaDinner', 'timestamp', '2016-01-14', 'calories', 900) // author-book edges juliaChild.addEdge('authored', artOfFrenchCookingVolOne) simoneBeck.addEdge('authored', artOfFrenchCookingVolOne) louisetteBertholie.addEdge('authored', artOfFrenchCookingVolOne) simoneBeck.addEdge('authored', simcasCuisine) patriciaSimon.addEdge('authored', simcasCuisine) juliaChild.addEdge('authored', frenchChefCookbook) aliceWaters.addEdge('authored', artOfSimpleFood) patriciaCurtan.addEdge('authored', artOfSimpleFood) kelsieKerr.addEdge('authored', artOfSimpleFood) fritzStreiff.addEdge('authored', artOfSimpleFood) // author - recipe edges juliaChild.addEdge('created', beefBourguignon, 'year', 1961) juliaChild.addEdge('created', ratatouille, 'year', 1965) juliaChild.addEdge('created', saladeNicoise, 'year', 1962) emerilLagasse.addEdge('created', wildMushroomStroganoff, 'year', 2003) emerilLagasse.addEdge('created', spicyMeatloaf, 'year', 2000) aliceWaters.addEdge('created', carrotSoup, 'year', 1995) aliceWaters.addEdge('created', roastPorkLoin, 'year', 1996) jamesBeard.addEdge('created', oystersRockefeller, 'year', 1970) // recipe - ingredient edges beefBourguignon.addEdge('includes', beef, 'amount', '2 lbs') beefBourguignon.addEdge('includes', onion, 'amount', '1 sliced') beefBourguignon.addEdge('includes', mashedGarlic, 'amount', '2 cloves') beefBourguignon.addEdge('includes', butter, 'amount', '3.5 Tbsp') beefBourguignon.addEdge('includes', tomatoPaste, 'amount', '1 Tbsp') ratatouille.addEdge('includes', eggplant, 'amount', '1 lb') ratatouille.addEdge('includes', zucchini, 'amount', '1 lb') ratatouille.addEdge('includes', mashedGarlic, 'amount', '2 cloves') ratatouille.addEdge('includes', oliveOil, 'amount', '4-6 Tbsp') ratatouille.addEdge('includes', yellowOnion, 'amount', '1 1/2 cups or 1/2 lb thinly sliced') saladeNicoise.addEdge('includes', oliveOil, 'amount', '2-3 Tbsp') saladeNicoise.addEdge('includes', greenBean, 'amount', '1 1/2 lbs blanched, trimmed') saladeNicoise.addEdge('includes', tuna, 'amount', '8-10 ozs oil-packed, drained and flaked') saladeNicoise.addEdge('includes', tomato, 'amount', '3 or 4 red, peeled, quartered, cored, and seasoned') saladeNicoise.addEdge('includes', hardBoiledEgg, 'amount', '8 halved lengthwise') wildMushroomStroganoff.addEdge('includes', eggNoodles, 'amount', '16 ozs wmyIde') wildMushroomStroganoff.addEdge('includes', mushroom, 'amount', '2 lbs wild or exotic, cleaned, stemmed, and sliced') wildMushroomStroganoff.addEdge('includes', yellowOnion, 'amount', '1 cup thinly sliced') spicyMeatloaf.addEdge('includes', bacon, 'amount', '3 ozs diced') spicyMeatloaf.addEdge('includes', onion, 'amount', '2 cups finely chopped') spicyMeatloaf.addEdge('includes', celery, 'amount', '2 cups finely chopped') spicyMeatloaf.addEdge('includes', greenBellPepper, 'amount', '1/4 cup finely chopped') spicyMeatloaf.addEdge('includes', porkSausage, 'amount', '3/4 lbs hot') spicyMeatloaf.addEdge('includes', groundBeef, 'amount', '1 1/2 lbs chuck') oystersRockefeller.addEdge('includes', shallot, 'amount', '1/4 cup chopped') oystersRockefeller.addEdge('includes', celery, 'amount', '1/4 cup chopped') oystersRockefeller.addEdge('includes', chervil, 'amount', '1 tsp') oystersRockefeller.addEdge('includes', fennel, 'amount', '1/3 cup chopped') oystersRockefeller.addEdge('includes', parsley, 'amount', '1/3 cup chopped') oystersRockefeller.addEdge('includes', oyster, 'amount', '2 dozen on the half shell') oystersRockefeller.addEdge('includes', pernod, 'amount', '1/3 cup') carrotSoup.addEdge('includes', butter, 'amount', '4 Tbsp') carrotSoup.addEdge('includes', onion, 'amount', '2 medium sliced') carrotSoup.addEdge('includes', thyme, 'amount', '1 sprig') carrotSoup.addEdge('includes', carrot, 'amount', '2 1/2 lbs, peeled and sliced') carrotSoup.addEdge('includes', chickenBroth, 'amount', '6 cups') roastPorkLoin.addEdge('includes', porkLoin, 'amount', '1 bone-in, 4-rib') roastPorkLoin.addEdge('includes', redWine, 'amount', '1/2 cup') roastPorkLoin.addEdge('includes', chickenBroth, 'amount', '1 cup') // book - recipe edges beefBourguignon.addEdge('includedIn', artOfFrenchCookingVolOne) saladeNicoise.addEdge('includedIn', artOfFrenchCookingVolOne) carrotSoup.addEdge('includedIn', artOfSimpleFood) // meal - recipe edges beefBourguignon.addEdge('includedIn', SaturdayFeast) carrotSoup.addEdge('includedIn', SaturdayFeast) oystersRockefeller.addEdge('includedIn', SaturdayFeast) carrotSoup.addEdge('includedIn', EverydayDinner) roastPorkLoin.addEdge('includedIn', EverydayDinner) beefBourguignon.addEdge('includedIn', JuliaDinner) saladeNicoise.addEdge('includedIn', JuliaDinner) // meal - book edges EverydayDinner.addEdge('includedIn', artOfSimpleFood) SaturdayFeast.addEdge('includedIn', simcasCuisine) JuliaDinner.addEdge('includedIn', artOfFrenchCookingVolOne) g.V()スクリプトをGremlin Consoleで読み込んでスクリプトを実行します。
"/tmp"は、スクリプトを作成したディレクトリーに置き換えます。gremlin> :load /tmp/generateRecipe.groovy// A series of returns for vertices and edges will mark the successful completion of the script // Sample vertex ==>v[{~label=author, member_id=0, community_id=1878171264}] // Sample edge ==>e[{out_vertex={~label=meal, member_id=27, community_id=1989847424}, local_id=545b88b0-0e7b-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=10, community_id=1878171264}, ~type=includedIn}] [{~label=meal, member_id=27, community_id=1989847424}-includedIn->{~label=book, member_id=10, community_id=1878171264}]timestampプロパティは、有効なDSEデータベースのタイムスタンプのデータ型に対応するTimestampデータ型です。 -
頂点の数を再びカウントします。
gremlin> g.V().count()==>56データを読み込むためのスクリプトを作成するために、graphloaderツールを使用することもできます。詳細については、graphloaderのドキュメントを参照してください。
グラフ探索を使用してグラフを探索すると、興味深い結論が得られることがあります。
-
グラフには複数の頂点authorが存在するため、特定の
nameを指定して特定の頂点を検索する必要があります。この探索は、Julia Childのnameを持つ(has)頂点に対し、格納されている頂点の情報を取得します。頂点がauthorであるという制約もhas句に含まれていることに注目してください。gremlin> g.V().has('author','name','Julia Child')==>v[{~label=author, member_id=0, community_id=1878171264}] -
この次の探索では、
has()はname = Julia Childでフィルター処理される頂点情報を取得します。探索ステップoutE()は、authoredラベルを含むその頂点から外向きエッジを検出します。gremlin> g.V().has('name','Julia Child').outE('authored')エッジの情報が返されます。
==>e[{out_vertex={~label=author, member_id=0, community_id=1878171264}, local_id=521f5450-0e7b-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=10, community_id=1878171264}, ~type=authored}][{~label=author, member_id=0, community_id=1878171264}-authored->{~label=book, member_id=10, community_id=1878171264}] ==>e[{out_vertex={~label=author, member_id=0, community_id=1878171264}, local_id=523155b0-0e7b-11e6-b5e4-0febe4822aa4, in_vertex={~label=book, member_id=12, community_id=1878171264}, ~type=authored}] [{~label=author, member_id=0, community_id=1878171264}-authored->{~label=book, member_id=12, community_id=1878171264}] -
代わりに、すべての作者が執筆した本をクエリーで検索する場合、最後の例ではエッジが取得されますが、隣接するbook頂点は取得されません。探索ステップ
inV()を追加して、外向きエッジに接続される頂点をすべて検索した後、これらの頂点の本のタイトルを出力します。V().outE().inV()により、連鎖されている探索ステップが頂点から外向きエッジに沿って隣接する頂点に移行する様子に注目してください。外向きエッジには特定のフィルター値であるauthoredが与えられます。gremlin> g.V().outE('authored').inV().values('name')==>The Art of French Cooking, Vol. 1 ==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>The Art of French Cooking, Vol. 1 ==>The French Chef Cookbook ==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>The Art of French Cooking, Vol. 1 ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution -
本のタイトルが結果のリスト内で重複していることに注目してください。これは、リスト項目が作者ごとに返されるためです。本に3人の作者が存在する場合は、3つのリスト項目が返されます。この重複は、探索ステップ
dedup()で除去できます。gremlin> g.V().outE('authored').inV().values('name').dedup()==>The Art of French Cooking, Vol. 1 ==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>The French Chef Cookbook ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution -
本のタイトルが結果のリスト内で重複していることに注目してください。これは、リスト項目が作者ごとに返されるためです。本に3人の作者が存在する場合は、3つのリスト項目が返されます。この重複は、探索ステップ
dedup()で除去できます。gremlin> g.V().outE('authored').inV().values('name').dedup()==>Simca's Cuisine: 100 Classic French Recipes for Every Occasion ==>The Art of French Cooking, Vol. 1 ==>The Art of Simple Food: Notes, Lessons, and Recipes from a Delicious Revolution ==>The French Chef Cookbook -
特定の作者に対して
has()ステップを再挿入することで探索を絞り込みます。Julia Childが執筆した本をすべて検索します。gremlin> g.V().has('name','Julia Child').outE('authored').inV().values('name')==>The Art of French Cooking, Vol. 1 ==>The French Chef Cookbook -
前回の例とこの例では、同じ結果が得られます。ただし、探索ステップの数と探索ステップの種類はパフォーマンスに影響を及ぼします。エッジが明示的に求められる場合は、探索ステップ
outE()を使用する必要があります。この例では、エッジが探索されて、接続されている頂点に関する情報が取得されますが、エッジの情報はクエリーには重要ではありません。gremlin> g.V().has('name','Julia Child').out('authored').values('name')==>The Art of French Cooking, Vol. 1 ==>The French Chef Cookbook探索ステップ
out()は、エッジ・ラベルauthoredに基づいて、エッジ情報を取得せずに、接続されているbook頂点を取得します。大きなグラフ探索では、探索におけるこのわずかな差はレイテンシー問題に発展することがあります。 -
追加の探索ステップで、結果を引き続き微調整します。連鎖されている別の
has探索ステップを追加すると、1967年より後に出版されたJulia Child著書の本のみが検索されます。この例でも、gt、つまりgreater than関数の使用が表示されます。gremlin> g.V().has('name','Julia Child').out('authored').has('year', gt(1967)).values('name')==>The French Chef Cookbook -
開発またはテスト中のときに、各頂点ラベルで頂点の数をチェックすると、データが読まれていることを確認できることがよくあります。頂点ラベルごとの頂点の数を検索するには、探索ステップ
label()に続き、探索ステップgroupCount()を使用します。ステップgroupCount()は、前のステップからの結果を集計するのに役立ちます。gremlin> g.V().label().groupCount()==>{meal=3, ingredient=31, author=10, book=4, recipe=8} -
データを出力ファイルに書き込んで情報を保存または交換します。Gryoファイルはバイナリー形式のファイルで、データをDSE Graphに再読み込みするために使用できます。この次のコマンドでは、グラフのI/Oを使用してグラフ全体をファイルに書き込みます。他のファイル形式は、
gryo()をgraphml()またはgraphson()に置き換えることで書き込むことができます。gremlin> graph.io(gryo()).writeGraph("/tmp/recipe.gryo")注:graph.io()はサンドボックス・モードでは無効です。==>null -
Gryoファイルを読み込むには、マッピング用スクリプトを作成した後に、
graphloaderを使用します。$ graphloader mappingGRYO.groovy -graph recipe -address localhost
Gryoデータの読み込みの詳細は、「DSE Graph Loaderの使用」の「Gryoデータの読み込み」で説明されています。
次のタスク
探索のさらなる詳細は、「探索を使用したクエリーの作成」に含まれています。さまざまな読み込みオプションについて調べる必要がある場合は、「DSE Graph Loader」または「DSE Graphの使用」を参照してください。