DSE Searchのアーキテクチャー
DSE Searchのアーキテクチャーの概要。
分散環境では、データが複数のノードに分散されています。DSE Searchノードをそれぞれのデータ・センターにデプロイして、すべてのノードでDSE Searchを実行します。
最初にデータがデータベースに書き込まれ、次にインデックスが更新されます。
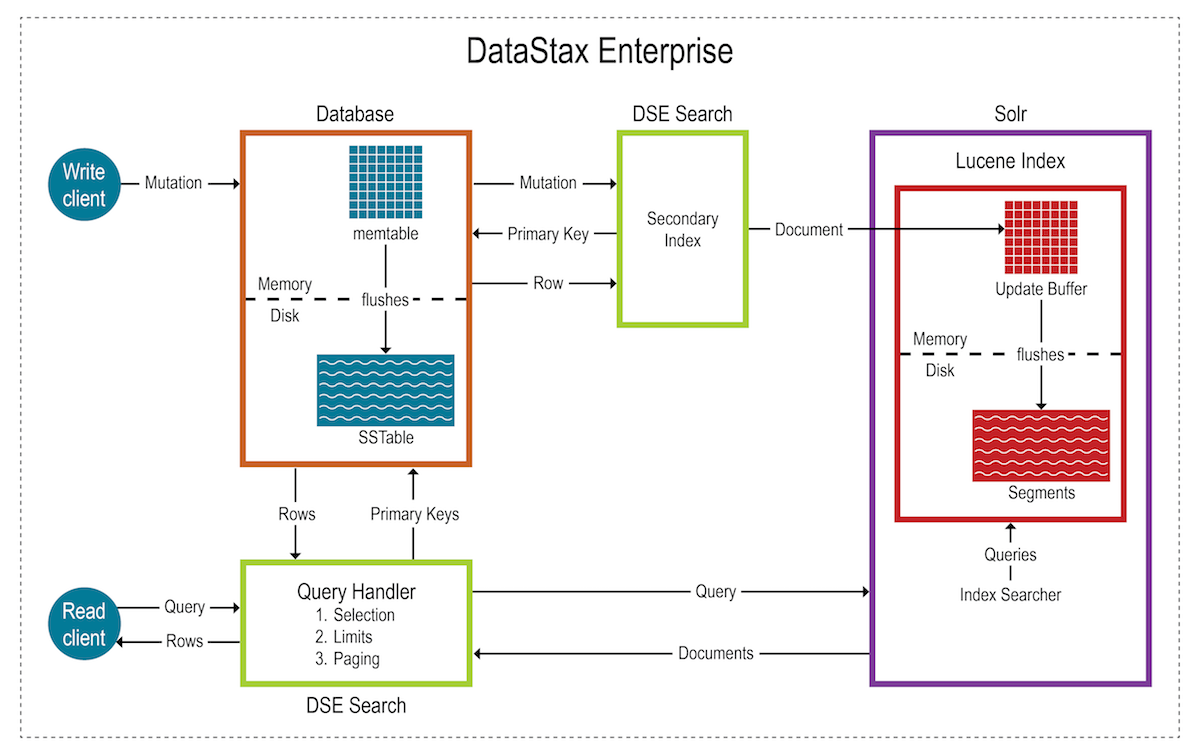
CQLを使用してテーブルを更新すると、検索インデックスが更新されます。更新後、インデックスの作成が自動的に行われます。書き込みは耐久性があります。レプリカ・ノードへのすべての書き込みは、メモリーとコミット・ログに記録されてから、成功として確認応答されます。メモリー・テーブルがディスクにフラッシュされる前にクラッシュまたはサーバーの障害が発生すると、失われた書き込みを回復するために、再起動時にコミット・ログが再生されます。
DSE Searchの用語
DSE Searchの場合、1つのノード上のドキュメントのインデックスに以下のような複数の名前が付けられています。
- 検索インデックス(以前は検索コアと呼ばれていました)
- コレクション
- コレクションのシャード
データベースとDSE Searchの概念のマッピングについては、次の表を参照してください。
| データベース | 検索単一ノード環境 |
|---|---|
| テーブル | 検索インデックス(コア)またはコレクション |
| 行 | ドキュメント |
| プライマリ・キー | ユニーク・キー |
| カラム | フィールド |
| ノード | なし |
| パーティション | なし |
| キースペース | なし |
DSE Searchの仕組み
- 検索インデックスの各ドキュメントは一意であり、ユーザー定義のスキーマに従うフィールドのセットが含まれています。
- スキーマにはフィールド型が列挙され、そのインデックスの作成方法が定義されます。
- DSE Searchは、検索インデックスをテーブルにマップします。
- 各テーブルには、特定のノードに関する別々の検索インデックスがあります。
- Solrドキュメントは行に、ドキュメントのフィールドはカラムにマップされます。
- シャードは、ローカル・ノード上のデータのサブセットのインデックス付きデータです。
- キースペースは検索インデックスの名前のプレフィックスになりますが、Solrにはこれに対応する部分はありません。
- 検索クエリーは、すべてのトークン範囲をカバーするのに十分なノードにルーティングされます。
- 可能性のある結果をすべて得るために、クエリーはすべてのトークン範囲に送信されます。
- 検索エンジンは、レプリケーション係数(RF)を踏まえて、各ノードが担当するトークン範囲を考慮し、すべての範囲をクエリーするのに必要なノードの最小数を計算します。
- DSE Searchノードで、分散クエリーのシャード選択アルゴリズムは、一連の基準を使用して最も処理能力の高いノードにサブクエリーをルーティングします。 シャード・ルーティングはトークンを認識しますが、検索クエリーで特定のトークン範囲が指定されていない限り制限されません。
- レプリケーションを使用した場合、ノードまたは検索インデックスには、テーブル(コレクション)データの複数のパーティション(シャード)が含まれます。レプリケーション係数がクラスター・ノードの数と等しい場合を除き、ノードまたは検索インデックスには、テーブルまたはコレクションのデータの一部しか含まれていません。