インデックスはどのように格納され、更新されるか
DataStax Enterpriseがどのようにインデックスを格納し、分散させるかの簡単な説明。
セカンダリ・インデックスは、非プライマリ・キー・カラムに格納されたデータのテーブルをフィルターします。たとえば、プライマリ・キーとしてサイクリストの姓を使用してサイクリストの名前および年齢を格納するテーブルには、年齢のセカンダリ・インデックスが含まれており、年齢によるクエリーが可能です。クエリーは、テーブルから取得したデータの連続したスライスとなる必要があるため、非プライマリ・キー・カラムに一致するクエリーはアンチパターンです。
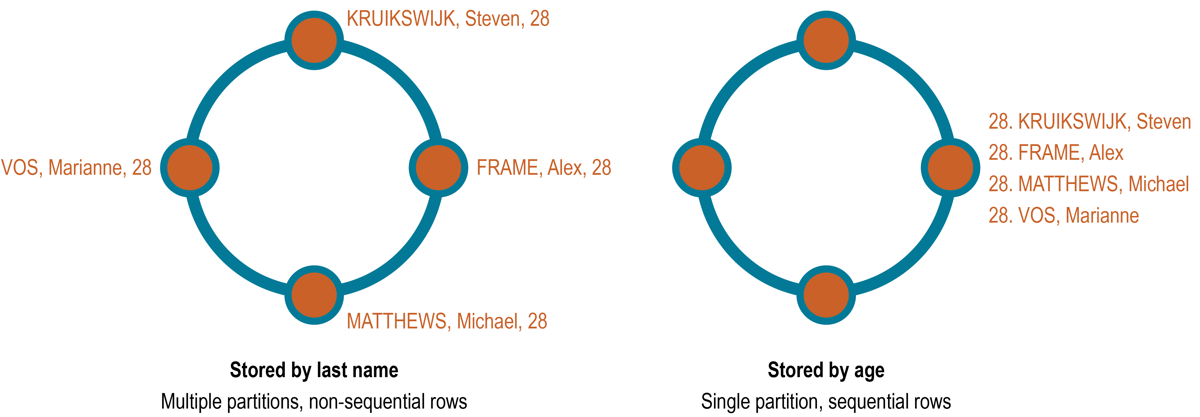
テーブル行が姓に基づいて格納されている場合、テーブルは、異なるノードに格納された複数のパーティションに分散される可能性があります。Matthewsという姓を持つすべてのサイクリストなどの、特定の姓の範囲に基づくクエリーでは、テーブルから連続した行を取得します。ただし、28歳のすべてのサイクリストなど、年齢に基づくクエリーでは、値をクエリーするためにすべてのノードが必要です。年齢のインデックスを使用できますが、効果的な解決策は、年齢順のマテリアライズド・ビューまたは追加のテーブルを作成することです。
セカンダリ・インデックスは、テーブルのカラムに対して作成されます。これらのインデックスは、隠されているテーブルの中の各ノードにローカルに格納され、バックグラウンド・プロセスで作成されます。クエリーにパーティション・キー条件とセカンダリ・インデックス・カラム条件が両方とも含まれている場合は、クエリーを1つのノードのパーティションに対して直接実行できるため、クエリーが成功します。
特定のパーティション・キーに制限されないクエリーでセカンダリ・インデックスが使用される場合、このクエリーでは、すべてのノードがクエリーされるため、ひどい読み取りレイテンシーが発生します。このようなパラメーターを持つクエリーは、クエリー・オプションALLOW FILTERINGが使用される場合にのみ許可されます。このオプションは、プロダクション環境には適しておらず、トラブルのないインデックス作成を保証するものではありません。どのような場合にインデックスを使用するのかを知ることは不可欠です。
リレーショナル・データベースと同様、インデックスを最新の状態に保つために処理時間とリソースが使用されるため、不要なインデックスは排除すべきです。カラムが更新されると、インデックスもこれに伴って更新されます。古いカラム値がmemtableに残る場合、これは一般に小さな行セットを繰り返し更新したときに起こりますが、DataStax Enterprise(DSE)はこのように古くなったインデックス・エントリーを削除します。そうしないと、古くなったエントリーはコンパクションによってパージされるまでそこに残ります。コンパクションによるパージが行われる前に読み取りで古いインデックス・エントリーが見つかった場合は、読み取りスレッドによってこれが無効にされます。