How is data written?
Understand how Cassandra writes and stores data.
- Logging data in the commit log
- Writing data to the memtable
- Flushing data from the memtable
- Storing data on disk in SSTables
Logging writes and memtable storage
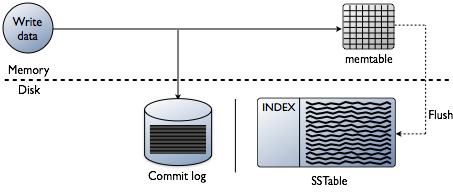
When a write occurs, Cassandra stores the data in a memory structure called memtable, and to provide configurable durability, it also appends writes to the commit log on disk. The commit log receives every write made to a Cassandra node, and these durable writes survive permanently even if power fails on a node. The memtable is a write-back cache of data partitions that Cassandra looks up by key. The memtable stores writes in sorted order until reaching a configurable limit, and then is flushed.
Flushing data from the memtable
To flush the data, Cassandra writes the data to disk, in the memtable-sorted order.. A partition index is also created on the disk that maps the tokens to a location on disk. When the memtable content exceeds the configurable threshold or the commitlog space exceeds the commitlog_total_space_in_mb, the memtable is put in a queue that is flushed to disk. The queue can be configured with the memtable_heap_space_in_mb or memtable_offheap_space_in_mb setting in the cassandra.yaml file. If the data to be flushed exceeds the memtable_cleanup_threshold, Cassandra blocks writes until the next flush succeeds. You can manually flush a table using nodetool flushor nodetool drain (flushes memtables without listening for connections to other nodes). To reduce the commit log replay time, the recommended best practice is to flush the memtable before you restart the nodes. If a node stops working, replaying the commit log restores to the memtable the writes that were there before it stopped.
Data in the commit log is purged after its corresponding data in the memtable is flushed to an SSTable on disk.
Storing data on disk in SSTables
Memtables and SSTables are maintained per table. The commit log is shared among tables. SSTables are immutable, not written to again after the memtable is flushed. Consequently, a partition is typically stored across multiple SSTable files. A number of other SSTable structures exist to assist read operations:
For each SSTable, Cassandra creates these structures:
- Data (Data.db)
- The SSTable data
- Primary Index (Index.db)
- Index of the row keys with pointers to their positions in the data file
- Bloom filter (Filter.db)
- A structure stored in memory that checks if row data exists in the memtable before accessing SSTables on disk
- Compression Information (CompressionInfo.db)
- A file holding information about uncompressed data length, chunk offsets and other compression information
- Statistics (Statistics.db)
- Statistical metadata about the content of the SSTable
- Digest (Digest.crc32, Digest.adler32, Digest.sha1)
- A file holding adler32 checksum of the data file
- CRC (CRC.db)
- A file holding the CRC32 for chunks in an a uncompressed file.
- SSTable Index Summary (SUMMARY.db)
- A sample of the partition index stored in memory
- SSTable Table of Contents (TOC.txt)
- A file that stores the list of all components for the SSTable TOC
- Secondary Index (SI_.*.db)
- Built-in secondary index. Multiple SIs may exist per SSTable
The SSTables are files stored on disk. The naming convention for SSTable files has changed with Cassandra 2.2 and later to shorten the file path. The data files are stored in a data directory that varies with installation. For each keyspace, a directory within the data directory stores each table. For example, /data/data/ks1/cf1-5be396077b811e3a3ab9dc4b9ac088d/la-1-big-Data.db represents a data file. ks1 represents the keyspace name to distinguish the keyspace for streaming or bulk loading data. A hexadecimal string, 5be396077b811e3a3ab9dc4b9ac088d in this example, is appended to table names to represent unique table IDs.
Cassandra creates a subdirectory for each table, which allows you to symlink a table to a chosen physical drive or data volume. This provides the capability to move very active tables to faster media, such as SSDs for better performance, and also divides tables across all attached storage devices for better I/O balance at the storage layer.