Data Modeling Concepts
How data modeling should be approached for Apache Cassandra. A music service example is used throughout the CQL document.
Data modeling is a process that involves identifying the entities, or items to be stored, and the relationships between entities. In addition, data modeling involves the identification of the patterns of data access and the queries that will be performed. These two ideas inform the organization and structure of how storing the data, and the design and creation of the database's tables. In some cases, indexing the data improves the performance, so judicious choices about secondary indexing must be considered.
Data modeling in Cassandra uses a query-driven approach, in which specific queries are the key to organizing the data. Cassandra's database design is based on the requirement for fast reads and writes, so the better the schema design, the faster data is written and retrieved. Queries are the result of selecting data from a table; schema is the definition of how data in the table is arranged.
Apache Cassandra™'s data model is a partitioned row store with tunable consistency. Rows are organized into tables; the first component of a table's primary key is the partition key; within a partition, rows are clustered by the remaining columns of the key. Other columns can be indexed separately from the primary key. Because Cassandra is a distributed database, efficiency is gained for reads and writes when data is grouped together on nodes by partition. The fewer partitions that must be queried to get an answer to a question, the faster the response. Tuning the consistency level is another factor in latency, but is not part of the data modeling process.
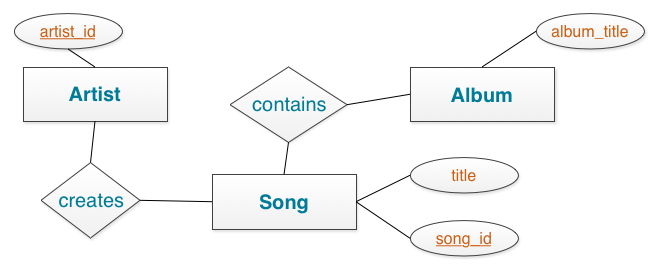
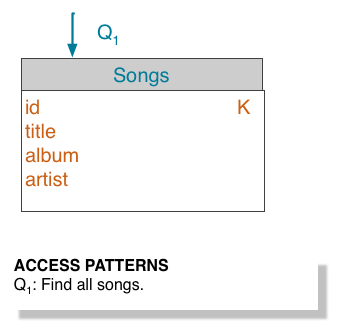

Notice that the key to designing the table is not the relationship of the table to other tables, as it is in relational database modeling. Data in Cassandra is often arranged as one query per table, and data is repeated amongst many tables, a process known as denormalization. The relationship of the entities is important, because the order in which data is stored in Cassandra can greatly affect the ease and speed of data retrieval.