Creating a materialized view
Create materialized views with the CREATE MATERIALIZED VIEW command.
Materialized views are suited for high cardinality data. The data in a materialized view is arranged serially based on the view's primary key. Materialized views cause hotspots when low cardinality data is inserted.
Secondary indexes are suited for low cardinality data. Queries of high cardinality columns on secondary indexes require Cassandra to access all nodes in a cluster, causing high read latency.
- Include all of the source table's primary keys in the materialized view's primary key.
- Only one new column can be added to the materialized view's primary key. Static columns are not allowed.
- Exclude rows with null values in the materialized view primary key column.
You can create a materialized view with its own WHERE conditions and its own properties.
Materialized view example
CREATE TABLE cyclist_mv (cid UUID PRIMARY KEY, name text, age int, birthday date, country text);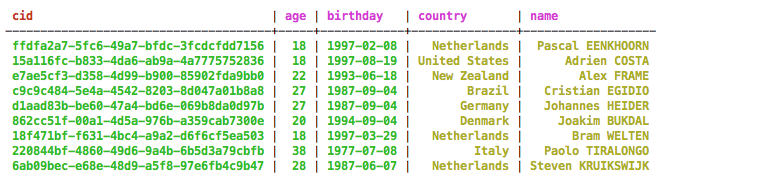
cyclist_mv table can be the basis of a materialized view that uses
age in the primary
key.CREATE MATERIALIZED VIEW cyclist_by_age
AS SELECT age, birthday, name, country
FROM cyclist_mv
WHERE age IS NOT NULL AND cid IS NOT NULL
PRIMARY KEY (age, cid);CREATE MATERIALIZED VIEW statement has several features:- The
AS SELECTphrase identifies the columns copied from the base table to the materialized view. - The
FROMphrase identifies the source table from which Cassandra will copy the data. - The
WHEREclause must include all primary key columns with theIS NOT NULLphrase so that only rows with data for all the primary key columns are copied to the materialized view. - As with any table, the materialized view must specify the primary key columns. Because
cyclist_mv, the source table, uses cid as its primary key, cid must be present in the materialized view's primary key.Note: In this materialized view, age is used as the primary key and cid is a clustering column. In Cassandra3.0 and earlier, clustering columns have a maximum size of 64 KB.
SELECT age, name, birthday FROM cyclist_by_age WHERE age = 18;
CREATE MATERIALIZED VIEW cyclist_by_birthday
AS SELECT age, birthday, name, country
FROM cyclist_mv
WHERE birthday IS NOT NULL AND cid IS NOT NULL
PRIMARY KEY (birthday, cid);
CREATE MATERIALIZED VIEW cyclist_by_country
AS SELECT age, birthday, name, country
FROM cyclist_mv
WHERE country IS NOT NULL AND cid IS NOT NULL
PRIMARY KEY (country, cid);SELECT age, name, birthday FROM cyclist_by_country WHERE country = 'Netherlands';
SELECT age, name, birthday FROM cyclist_by_birthday WHERE birthday = '1987-09-04';
When another INSERT is executed on cyclist_mv, Cassandra updates the source
table and both of these materialized views. When data is deleted from
cyclist_mv, Cassandra deletes the same data from any related materialized
views.
Cassandra can only write data directly to source tables, not to materialized views. Cassandra updates a materialized view asynchronously after inserting data into the source table, so the update of materialized view is delayed. Cassandra performs a read repair to a materialized view only after updating the source table.