Data modeling
Introduction to data modeling.
This section describes some basic data modeling concepts.
- Data modeling identifies the tables that store the data. You create your data model and tables using CQL.
- Data modeling in DataStax Distribution of Apache Cassandra™ (DDAC) is based on queries. Define your application queries first and then use the queries to design the database tables.
- Cassandra and relational databases model data relationships differently:
- In a relational database, you define the relationships between tables using foreign keys and then write queries to refer from one table to another.
- In Cassandra, there are no foreign keys. Instead, relationships between tables are typically managed by the application, not the database server.
- Cassandra and relational databases use different data normalization:
- Relational databases use a normalized data model, which removes as much data duplication as possible.
- Data in Cassandra is often retrieved using one query for each table. Data can be repeated
among tables, a process known as denormalization. This enables high performance.
For example, in a relational database, a user entity and an address entity each have a table, and a foreign key defines the relationship between a user and their address. In Cassandra, the user and their address are stored in one table.
- Cassandra uses a partitioned row store with tunable data consistency:
- Consistency refers to how up-to-date and synchronized all replicas of a row are.
- Tunable consistency means that you specify the required consistency for the read and write operations.
- Some data requires high consistency. For example, an update to a user password requires high consistency, but an update to a user profile picture might require low consistency.
- High consistency operations have a greater performance penalty.
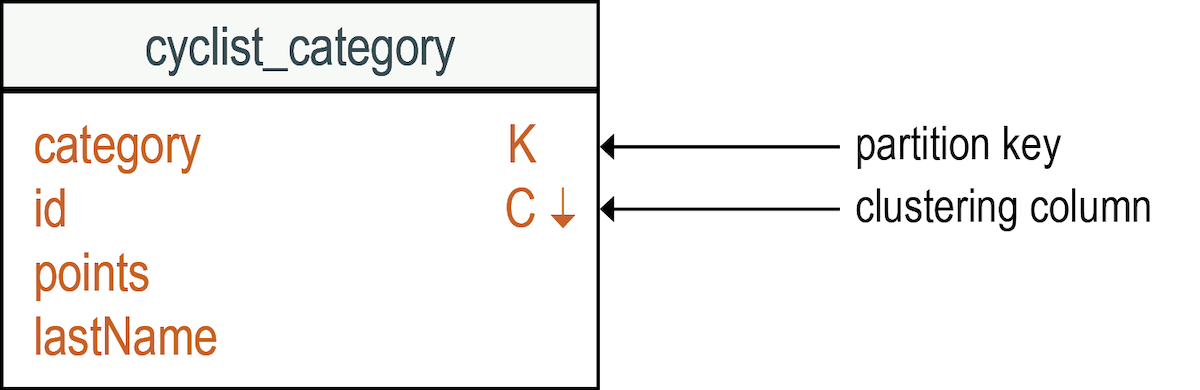
- Rows are organized into tables:
- A row is uniquely identified by a primary key. In Cassandra, a primary key has a partition key and one or more optional clustering columns.
- A partition key can contain one or more columns. The partition key determines which node stores the data.
- Clustering columns set the row sorting order in the partition. The order can be ascending or descending.
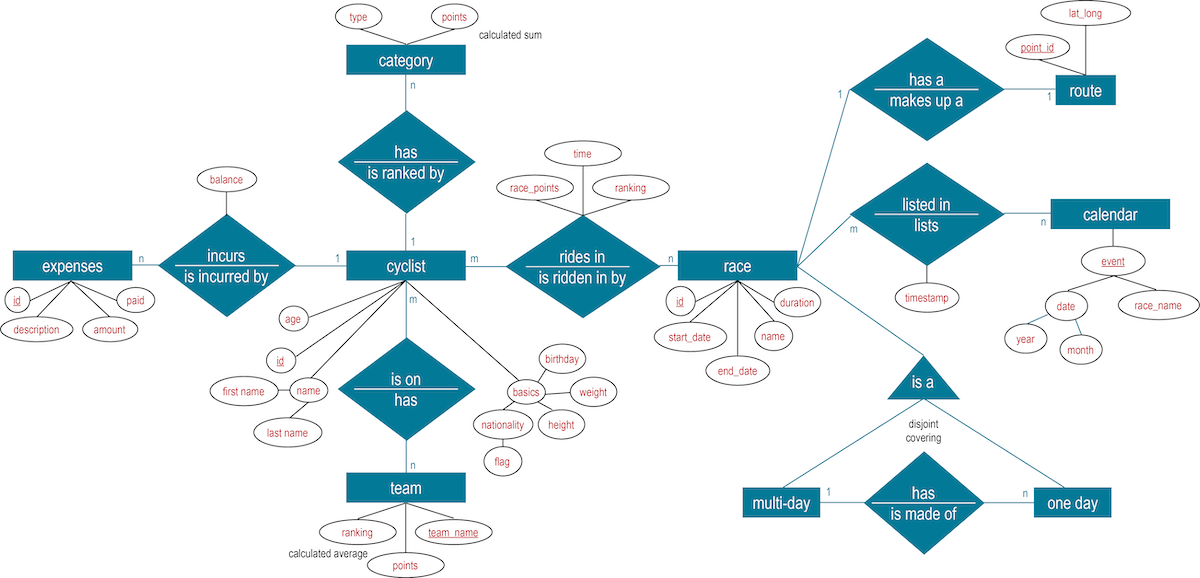
This quickstart and the CQL documentation use a data model that stores details about cyclists and cycling races:
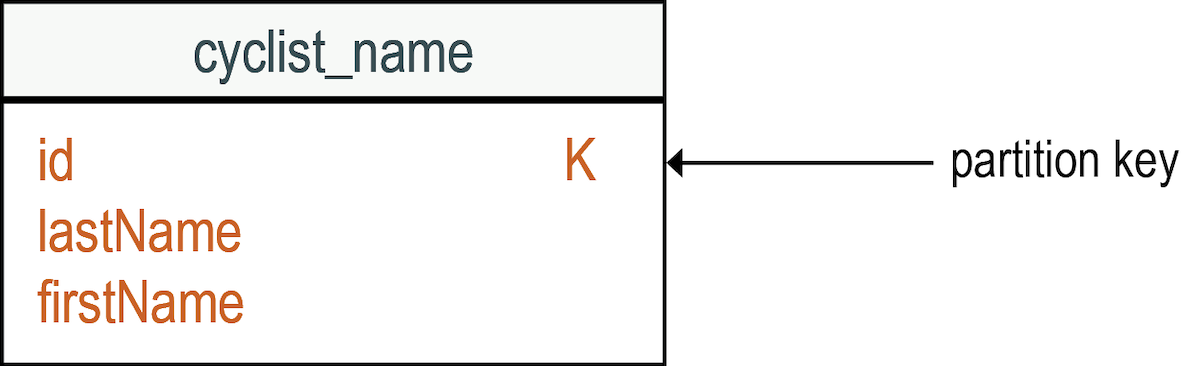
As mentioned earlier, queries are used to design the database tables. For example, you can run
a query that returns a list of cyclists, including each cyclist's unique id
identifier, firstname, and lastname. The id
column is the table's partition key (K). This diagram shows the logical model for the cyclist
details: