Comparing DSE Graph and relational databases
Graph databases and relational databases can both store data, but the storage method, scalability, and indexing techniques that each uses is very different.
DSE Graph is a good choice for data and queries that are highly complex. Graph databases and relational databases can both store data. Both database types can be queried to retrieve filtered results. However, the storage methods, scalability, and indexing techniques that each database type uses is very different.
DSE Graph is recommended for the following use cases:
- Fraud detection
- Recommendation engines
- IT network and device management
- Inventory management
- Master data management
Storage
Both relational databases and DSE Graph store data in tables. In a relational database, a key is defined to retrieve data, and a foreign key is required to link tables that share a relationship. Data is normalized, which means that the data is stored so that no duplication occurs. To write complex queries, several tables must be accessed to join and retrieve data.
DSE Graph stores data in the DSE database tables, and the relationship between data is embedded in the model. Data storage in a graph database can be compared to a pre-joined relational database, with built-in data relationships, so foreign keys are unnecessary. Data is retrieved by traversing the graph, so time-consuming and error-prone JOIN operations are not required.
Scaling
An added bonus for graph databases is the ability to scale database distribution. A graph database query starts with a particular vertex and filters the graph based on the query requirements. Because the retrieval generally involves filtering subset(s) of the entire graph, the graph can be partitioned. The query can run in parallel for some steps of the traversal, operating on either a single or small number of nodes in the DataStax Enterprise (DSE) cluster. Because of interconnected tables, successful queries require accessing many tables in a relational databases. Joining data is costly, which makes relational databases hard to scale out and distribute.
Indexing
Indexing techniques between graph databases and relational databases are distinct and can affect performance markedly. Consider the query for looking up all buyers that purchased an Xbox One. In a relational database, three tables would be accessed to answer the query:
- Each buyer in the
buyerstable - The item being queried in the
itemstable - The buyer and item in the
buyers-itemstable, created through a JOIN operation

In contrast, a graph database requires only one index lookup for the item, and then traverses the graph to each buyer vertex to complete the query.
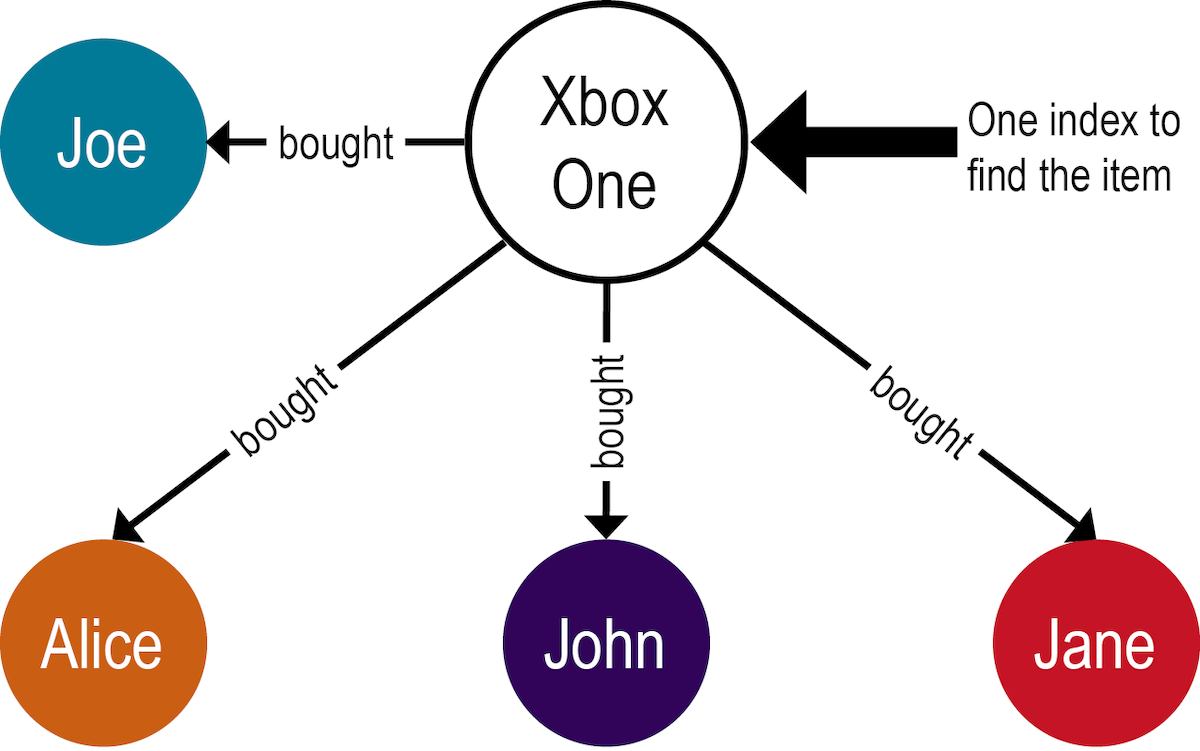
The graph database query will run in near-constant time. The relational database query, if a balanced tree (B-tree) index is assumed, runs in O(log N) time, where N is the number of records in the table for each foreign key that must be referenced. Even a one-deep query will greatly impact performance; if a query goes to a more deeply nested depth, the performance gap will further increase.
Writing complex queries in DSE Graph is much simpler than in relational databases using SQL. Consider the query required for a recommendation engine about products: the SQL query on the left is vastly more complex than the Gremlin query on the right.
Although many developers are familiar with SQL, this example illustrates the difficulty of writing a complex query, even for experts. By contrast, Gremlin query can intuitively be read from left to right, and each step follows from the previous step.
