Graph data modeling example
Details of a larger data model creation.
- vertex vs property
- vertex property vs edge property
- meta-property use
- multi-property use
- edge directionality
- edge uniqueness (single edge vs multiple edges)
- indexes - why use them and which ones
Vertex, edge or property?
In general, if an entity is a thing, it will be a vertex. If it describes an action on a thing, it's an edge. Lastly, if it is a qualifier of a thing, it is a property.
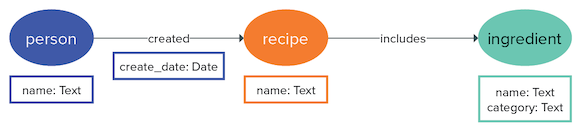
For instance, what is a possible additional type of vertex besides person and recipe in the
food data model? Recipes use ingredients, so ingredient vertices will be
required. Recipes are generally published in cookbooks, so book vertices will
also be added.
What are some edges that will connect these vertices? Each ingredient is
included_in a recipe, and each recipe is likely included_in
at least one book.
And finally, all of these vertices and edges have properties. An ingredient will have a
name and id, a book will have a
publish_date, an edge included_in can identify the amount of
an ingredient used in a recipe. A recipe can be included_in many books, creating multiple edges
between vertices.
Keep in mind that property keys like name can be reused for several vertices
or edges. Keeping the schema small has advantages in DSE Graph, so using a generic property key
like name instead of a specific key like ingredient_name is
advantageous.
Vertex vs property

category property. But could
category be a vertex with an edge connecting an ingredient with several
categories? Generally, vertex properties are easily queried. So are edges between vertices. What
is the deciding factor in which option to use? One key data model feature you want to avoid is a
super-node, a single vertex containing billions of connections to other vertices. With
ingredients, there is unlikely to be billions of ingredients in any category, unless the
category is absurdly broad, like hot_food. Another deciding factor can be to
contemplate if the category vertex would have any property of its own. Perhaps a category is a
member of another category, branching out from a broad category to more sub-categories. In this
case, however, it seems that category has no definite requirements, so creating it either as a
property or a vertex is reasonable.Vertex property vs edge property
Vertex properties can be searched more readily, as most graph traversals start with a specific
set of vertices based on property key:value pairs. For instance, if I want to find all the
cookbook authors in France, I can search all the vertices with the vertex label
person who have lived in the country of France. Graph
traversals that find particular relationships between vertices must have a starting point at a
set of vertices; consequently, edge properties are secondary factors in a query. Edge labels can
narrow down the edges traversed, so a query can find all the cookbook authors in France who
know Julia Child, but the query begins with person vertices
or a specific person vertex such as Julia Child. And edge property for the
know edges can give us additional information, such as when Julia Child met an
author who lives in France, but starting the search to see who Julia Child met in 1955 would not
be performant.
amount is the right choice: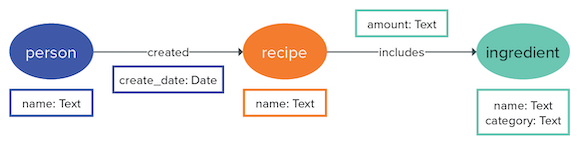
Meta-property use
Meta-properties are useful when a property has properties of its own, and creating that property as a vertex is not appropriate. Oftentimes, a meta-property is designed for storing permissions for a property or starting and ending dates for a property. Many data models do not use meta-properties at all.
Multi-property use
Multi-properties, or properties that can have multiple values, can be useful for storing
similar information. For instance, a nickname property can store all the
nicknames that a person might have, or a email property can store all the
various email addresses a person owns. Consider how related information is before using a
multi-property in your data model design.
Edge directionality
Edge directionality can play a role in the performance of queries. If your queries generally want to find the ingredients included_in a recipe, rather than what recipes use a specific ingredient, then initially designing the edge in the more common direction will simplify graph queries. Queries in the opposite direction are not impossible, but to make queries more readable, keep highest likelihood in mind.
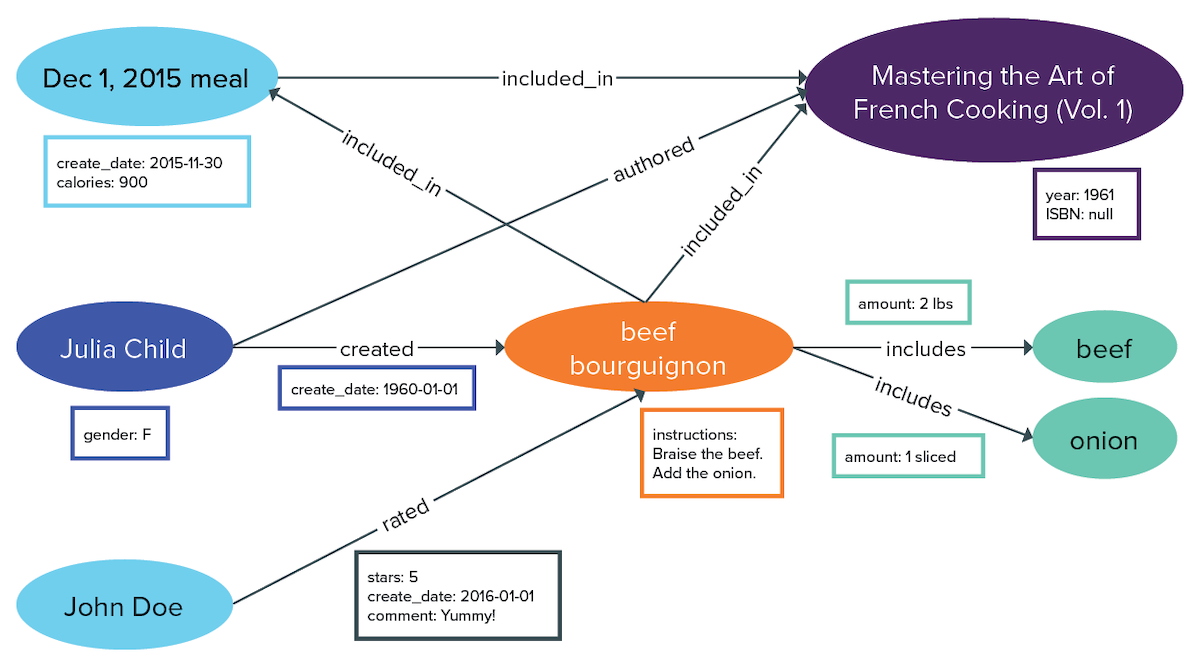
Edge uniqueness
Edge uniqueness is guaranteed by an auto-generrated edge id, but if the ids are not examined,
multiple edges can appear to be either identical or in conflict. Consider if recipes are
reviewed by a person. If a person, say John Doe, reviews the same recipe more
than once, he may assign a different star rating each time. Or he may rate it
with the same star rating each time. What if five edges exist between John Doe and beef
bourguignon, with the same star rating? How do we know that each review is unique? And do you
want to allow five identical reviews to exist? A number of modeling techniques can be used to
make the intent of the data model clearer. For instance, the reviewed edge
could be defined in the schema as single, allowing only one edge to exist
between a given pair of vertices. Although valid, this option seems more suited to an edge
born_in between a person and a birth city. Another design might add another
edge property review_date that would make clear that two different reviews were
made at different times. But what if the design wants to allow multiple edges identical or even
non-identical between a given pair of vertices? In DSE Graph, the default schema for edge labels
will suffice - but beware of intended consequences.
Indexes
Indexes play a significant role in making DSE Graph queries performant. Graph queries that must traverse the entire graph to find information will have poor performance, which explains why full-scan queries are disallowed in production environments. Two aspects of querying a graph can be improved with indexing: the initial vertex or vertices from which to start a traversal, and the narrowing of the edges and vertices to traverse from this starting point. DSE Graph implements two types of indexes, global indexes and vertex-centric indexes (VCIs) to address these different aspects of query processing. Global indexes are used to find the starting point for a query and involve finding a matching vertex property value. Vertex-centric indexes are used to narrow down the scope of a query after a starting point is defined.
Global indexing overview
g.V(['~label':'person', 'personId':1])g.V().has('person', 'name', 'Julia Child')name is not part of the vertex id, an index is required to match the search
conditions with the correct vertex, and that index is a global index.Global indexing in DSE Graph can be accomplished with one of three DSE indexing methods: a materialized view (MV), a search index, or a secondary index.
selectivity = ( cardinality / number of rows ) * 100%Search indexes are used when textual, numeric or geospatial indexing are required and rely on DSE Search. Since graph data is stored in DSE database tables, one search core is available per vertex label. For each vertex label that will be indexed with search, all properties must be added to a single search index named search. Because search is implemented with DSE Search, all data types can be indexed. For two indexing options, full text and string, the property key must be defined, as different indexing results. Full text indexing performs tokenization and secondary processing such as case normalization. Full text indexing is useful for queries where partial match of text is required, and lends itself to regular expressing (regEx) searching. String indexing is useful for queries where an exact string is sought and no tokenization is required, similar to Solr faceting. This type of index is best for low selectivity, but lends itself to fuzzy matching for both tokenized and non-tokenized indexing.
Secondary indexing in DSE Graph follows the same rule of thumb as DSE secondary indexing. This type of index is meant for lower cardinality values, or alternatively, for low selectivity values. The number of values for indexing should number in the tens to hundreds at most; for instance, searching by country is a good candidate for secondary indexing. In addition, only equality conditions can be used to match values, and no ordering or range queries on values can be used. If more complex value matching is required, search indexes are the superior choice.
| Index type | Use |
|---|---|
| Materialized view | Most efficient index for high cardinality, high selectivity vertex properties and equality predicates. |
| Secondary index | Efficient index for low cardinality, low selectivity vertex properties and equality predicates. |
| Search index |
Efficient and versatile index for vertex properties with a wide range of cardinality and selectivity. A search index supports a variety of predicates:
|
Composite index keys are not currently supported in DSE Graph.
Vertex-centric indexing (VCI) overview
g.V().has('person', 'name', 'Julia Child').outE('created').has('create_date', gt(1960-01-01)) g.V().has('person', 'name', 'Fritz Streiff').properties('country').has('start_year', order().by(decr))Vertex-centric indexing in DSE Graph is accomplished with materialized views (MVs) for both edge and property indexes, and have the same properties as described above for global indexes.
Indexing best practices
The most important fact to remember is that a search index is the only choice for indexing two
or more properties that define the starting point for a query. Multiple materialized view or
secondary indexes cannot be used for global indexing. For instance, g.V().has('person',
'gender', 'F').has('person', 'country', 'France') will only use one index, not both,
if the indexes are materialized view or secondary indexes. If a search index is defined, both
properties,country and gender, are used. Once the starting
point is defined, a vertex-centric index can be used to narrow the query.
More than one index can be created on the same property, such as creating both a materialized
view (MV) index and a search index on the property amount. The DSE Graph query
optimizer automatically uses the appropriate index when processing a query; designation of an
index type to use is not a feature. The order of preference that DSE Graph uses is MV index >
secondary index > DSE Search index to ensure best performance. However, choosing the optimal
type of index is key to good performance. For instance, it is important to understand the
limitations of materialized views, and base the number of MV indexes on that understanding. See
. Different index types may be created on different properties as
appropriate, based on the selectivity. In general, secondary indexes in DSE Graph are limited in
usefulness, for the same reasons that constrict their general use in DSE. Materialized view
indexing should be the first choice, unless textual search is required and a search index is
selected.
If a search index is created, be aware that building the index can take time, and that until the index is available, queries that depend on the index can fail. Applications that create schema, immediately followed by data insertion that require search indexes will likely experience errors. Also, queries that use search indexes should be run on DSE Search-enabled nodes in the cluster. Search indexes also require extra resources. Each index allocates a minimum of 256MB of memory by default, and each index will require two physical cores. For a typical 32GB node, 16 search indexes would be a reasonable number to create.
tokenRegex will display case insensitivity in queries, whether
a search index is used or not.Textual search indexes are by default indexed in both tokenized
(TextField) and non-tokenized (StrField) forms. This means that all textual
predicates (token, tokenPrefix, tokenRegex, eq, neq, regex, prefix) will be usable
with all textual vertex properties indexed. Practically, search indexes should be
created using the asString() method only in cases where there is
absolutely no use for tokenization and text analysis, such as for inventory
categories (silverware, shoes, clothing). The asText() method is
used if searching tokenized text, such as long multi-sentence descriptions. The
query optimizer will choose whether to use analyzed or non-analyzed indexing based
on the textual predicate used.
It is possible to modify search index schema to change search characteristics. Although DSE Graph will not overwrite these out-of-band changes, it is recommended that you do not add or remove fields in this manner - only DSE Graph commands should be used. The general use of this feature is mainly to change the behavior of a search, such as adding case sensitivity to a type of search.
Complexity
The data model is the first step in creating a graph. Using the data model, a schema can be created that defines how DSE Graph will store the data.