DSE Graph leverages DSE Search indexes to efficiently filter vertices by properties, and reducing query
latency. DSE Search uses a modified Apache
Solr to create the search indexes. Graph search indexes can be created
using textual, numeric and geospatial data.
It is important to note that traversal queries with search predicates can be
completed whether a search index exists or not. However, full graph scans will occur
without a search index and performance will degrade severely as the graph grows, an
unacceptable solution in a production environment. Create search indexes during
schema creation before inserting data and querying the graph. Search indexes will
only be created if DSE Search is started in conjunction with DSE Graph. If search
indexes are used, the queries must be run on DSE Search nodes in the cluster.
In general, the traversal step will involve a vertex label and can include a property
key and a particular property value. In a traversal, the step following
g.V() is generally the step in which an index will be
consulted. If a mid-traversal V() step is called, then an
additional indexed step can be consulted to narrow the list of vertices that will be
traversed.
Textual search indexes are by default indexed in both tokenized
(TextField) and non-tokenized (StrField) forms. This means that all textual
predicates (token, tokenPrefix, tokenRegex, eq, neq, regex, prefix) will be usable
with all textual vertex properties indexed. Practically, search indexes should be
created using the asString() method only in cases where there is
absolutely no use for tokenization and text analysis, such as for inventory
categories (silverware, shoes, clothing). The asText() method is
used if searching tokenized text, such as long multi-sentence descriptions. The
query optimizer will choose whether to use analyzed or non-analyzed indexing based
on the textual predicate used.
Property key indexes defined with asText() or undefined (since this
is the default) can use the following options for search:
Note: The eq() search cannot be used with property key indexes
created with asText()because they contain tokenized data and
are therefore not suitable for exact text matches.
In addition, in DSE 5.1 and later, fuzzy search predicates have been added:
This search index uses DSE Search to index instructions as
full text using tokenization, and name as a string. Note
that, as of DSE 5.1, only those properties that specifically should be
indexed as non-tokenized data must specify asString(). If
there are proporties that specifically should be indexed only as tokenized
data, specify asText().
Search using token() methods on full
text
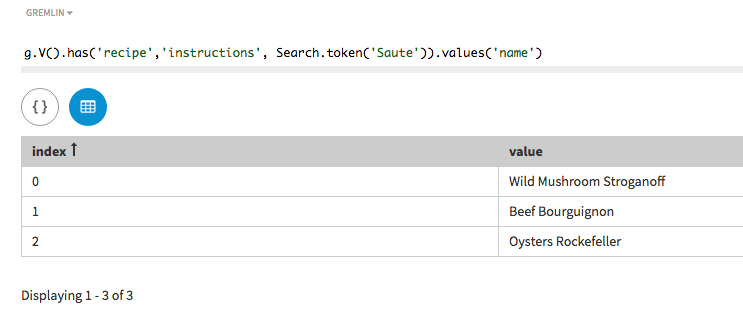
In a traversal query, use a token search to find list the names of all recipes
that have the word Saute in the instructions. The method
token() is used with a supplied word.
Why does this search find these three recipes? Because the instructions
for each meet the search requirements:
Search using tokenPrefix() methods on full
text
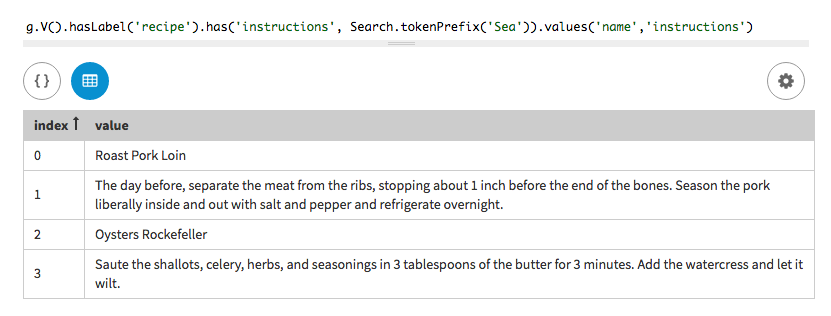
In a traversal query, use a token prefix search to list the names of all
recipes that have a word that includes a prefix of Sea in the
instructions. The method tokenPrefix() is used with a supplied
prefix (a set of alphanumeric characters).
Two recipes are returned, one with the word Season in the
instructions, and one with the word seasonings in the instructions.
Case is insensitive in tokenPrefix() indexing.
Search using tokenRegex() methods on full
text
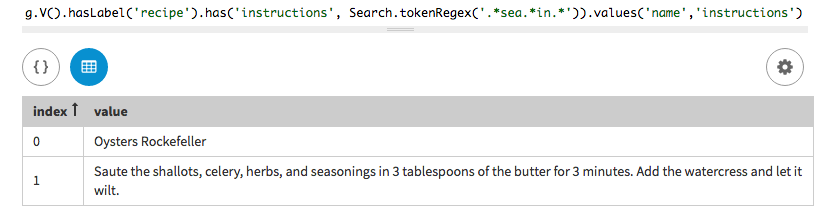
In a traversal query, use a token regular expression (regex) search to find all
recipes that have a word that includes the regular expression specified. The
regex, .*sea*in.*, looks for the letters sea preceded by
any number of other characters and followed by any number of other characters
until the letters in are found and also followed by any number of other
characters in the instructions and list the recipe names. The method
tokenRegex() is used with a supplied regex.
Note that in this query, only the Oysters Rockefeller recipe is returned
because the word Season in the Roast Pork Loin recipe does not meet
the requirements for the regular expression.
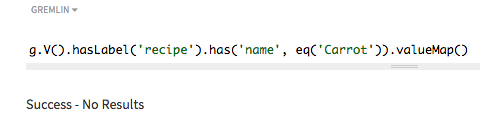
Search using eq() on non-token methods on
strings
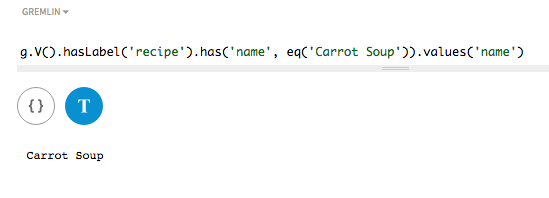
In a traversal query, use a non-token search to list all recipes that have
Carrot Soup in the recipe name. Note that this search is
case-sensitive, so using carrot soup would not find a vertex.
The method eq() is used with a supplied name.
No match is found, because only a partial name was specified. For
asString() indexes, the string must match.
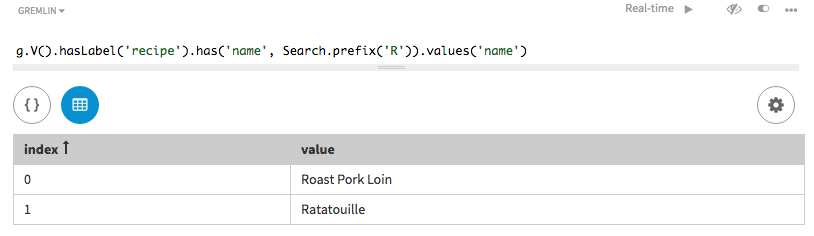
Search using prefix() on non-token methods on
strings
In a traversal query, use a non-token search to find all authors that have a
name beginning with the letter R. The method
prefix() is used with a supplied string.
Matches are found for each author name that begins with R,
provided the recipe name was designated with asString() in
the search index.
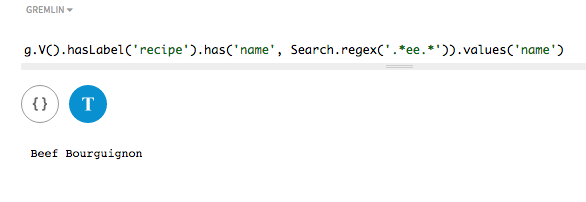
Search using regex() on non-token methods on
strings
In a traversal query, use a non-token search to find all recipes that have a
name that includes a specified regular expression. The method
regex() is used with a supplied regex.
Matches are found for each author name that include the regex
.*ee.* to find all strings that include ee
preceded and followed by any number of other characters, provided the recipe
name was designated with asString() in the search
index.
Search using phrase()
The phrase() predicate is used with properties designated as
TextFields.
Find the exact phrase Wild Mushroom Stroganoff in a recipe
name:
The phrase() predicate can be used for proximity searches, to discover
phrases that have terms that are within a certain distance of one another in the
tokenized text.
The value of 1 designates that the result must only have words
in the recipe name that are one term away from one another. In this example, the
variation is the addition of the word Mushroom.
The vertex for the correct recipe is returned. A match for
g.V().hasLabel('recipe').has('name', phrase('Wild
Mushroom',1)) will also return the correct vertex, but
g.V().hasLabel('recipe').has('name', phrase('Mushroom
Wild',1))will not.
Search using fuzzy()
The fuzzy() predicate uses optimal string alignment distance
calculations to match properties designated as StrFields. Variations
in the letters used in words, such as misspellings, are the focus of this
predicate. The edit distance specified refers to the number of transpositions of
letters, with a single transposition of letters constituting one edit.
Find the exact name of James Beard in an author
name:
The 1 designates that the result matches with an edit distance
of at most one.
James Beard, Jmaes Beard
If an author vertex
exists with the misspelling Jmaes Beard, the query shown will find both
vertices. The value of 1 finds this misspelling because of the single
transposition of the letters a and m.
Note that searching for a misspelling will find the records with the correct
spelling, as well as the misspelled name
The 2 designates that the result must match with at most two
transpositions.
James Beard, Jmaes Beard
If an author vertex
exists with the misspelling Jmaes Beard, the query shown will find both
vertices. The value of 2 finds both the misspelling because of the single
transposition of letters, e and s in Jmaes Beard, as well
as the correct spelling with a second transposition of letters from Jmase
Beard to James Beard .
CAUTION: Specifying an edit
distance of 3 or greater matches too many terms for useful results. The
resulting search index will be too large to efficiently filter
queries.
Search using tokenFuzzy()
The tokenFuzzy() predicate similar to
fuzzy(), but searches for variation across individual tokens in
analyzed textual data (TextFields).
Find the recipe name that includes the word Wild while searching for
the word with a one-letter
misspelling:
This search index will use DSE Search to index nickname as
full text using tokenization, and name as a string.
This traversal query demonstrates a mid-traversal V() that
allows a search index for author as well as a search index for recipe to be used
to execute the query. The first index uses a tokenRegex() to
find recipe instructions that start with the word Braise; this part of
the query is labeled as r for use later in the query. Then the search
index for author is searched for an author name that starts with the letter
J, and traversed through an outgoing edge to a vertex where the
search found in the first part of the query is found with
where(eq('r')).
This query traversal finds the recipe Beef Bourguignon
authored by Julia Child, and illustrates some of the
complexity that can be successfully used with search indexes.
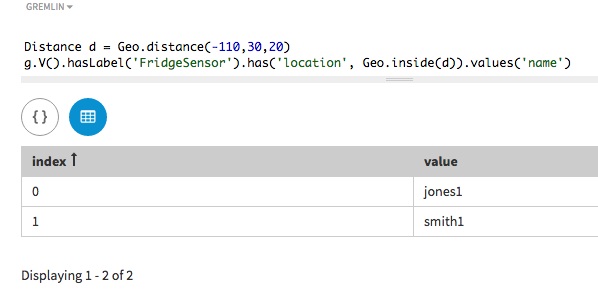
Search using geospatial values
Geospatial search is used to discover geospatial relationships. Search indexes
are used to make such searches possible. First, a search index must be
created.
The sensors are named and given a city ID and sensor ID in addition to the
location with data type Point.
A query can find all sensors that meet the requirement of being inside the
described polygon Distance that is designated as a circle with
a center at (-110, 30) and a radius of 20 degrees with the method
Geo.inside().
Distance d = Geo.point(-110,30),20, Geo.Unit.DEGREES)
g.V().hasLabel('FridgeSensor').has('location', Geo.inside(d)).values('name')