How are write requests accomplished?
The write consistency level determines how many replica nodes must respond with a success acknowledgment in order for the write to be considered successful
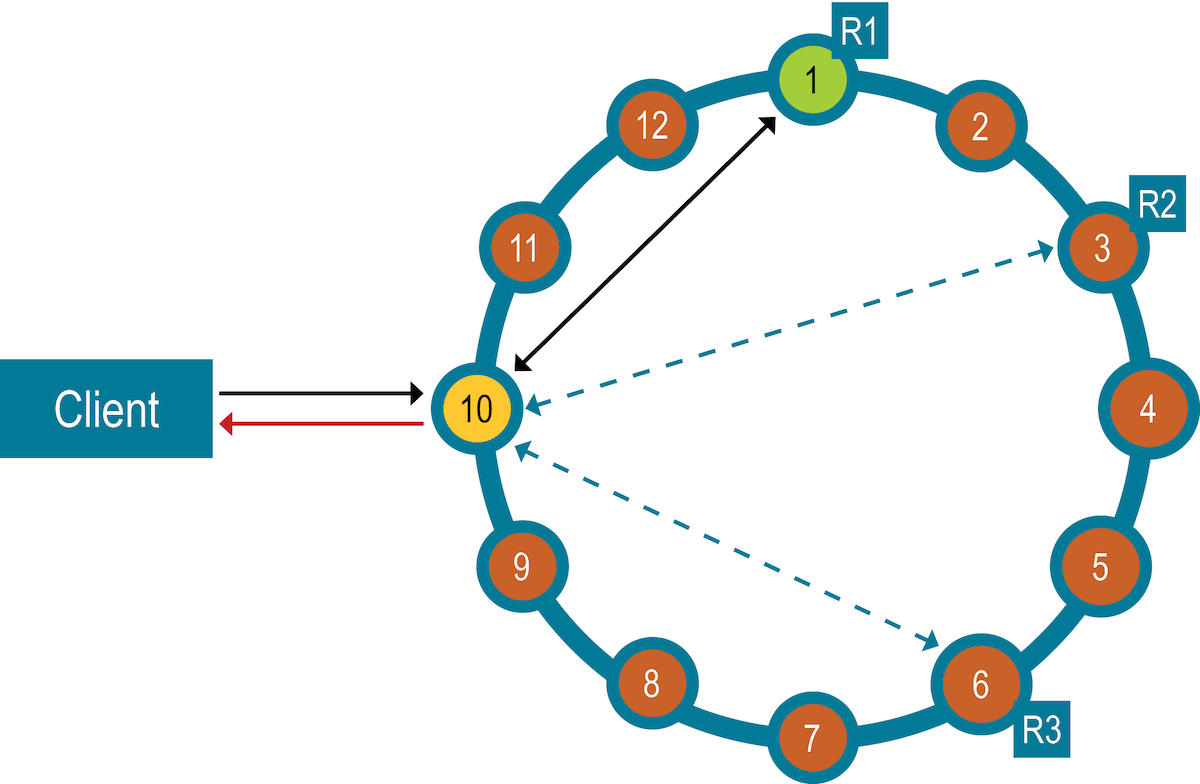
The coordinator node sends a write request to all replicas that own the row being written. As long as all replica nodes are available, they will get the write regardless of the consistency level specified by the client. The write consistency level determines how many replica nodes must respond with a success acknowledgment for the write to be considered successful. Success means data was written to the commit log and the memtable.
The coordinator node forwards the write to replicas of that row. After the coordinator node receives write acknowledgements from the number of nodes specified by the consistency level, the coordinator responds to the client.
- If the coordinator cannot write to enough replicas to meet the requested consistency
level, it throws an
Unavailableexception and does not perform any writes. - If there are enough replicas available but the required writes do not finish within the
timeout window, the coordinator throws a
Timeoutexception.
For example, in a single-datacenter, 10-node cluster with a replication factor of 3, an
incoming write will go to all three nodes that own the requested row. If the write consistency
level specified by the client is ONE, the first node to complete the write
responds back to the coordinator, which then proxies the success message back to the client. A
consistency level of ONE means it is possible that two of the three replicas
can miss the write if they are down when the request is made. If a replica misses a write, the
row is made consistent later using one of the built-in repair
mechanisms: hinted handoff, read repair, or anti-entropy node repair.