How is data written?
Understand how the DataStax Enterprise database writes and stores data.
The DataStax Enterprise database processes data at several stages on the write path, starting with the immediate logging of a write and ending in with a write of data to disk:
- Logging data in the commit log
- Writing data to the memtable
- Flushing data from the memtable
- Storing data on disk in SSTables
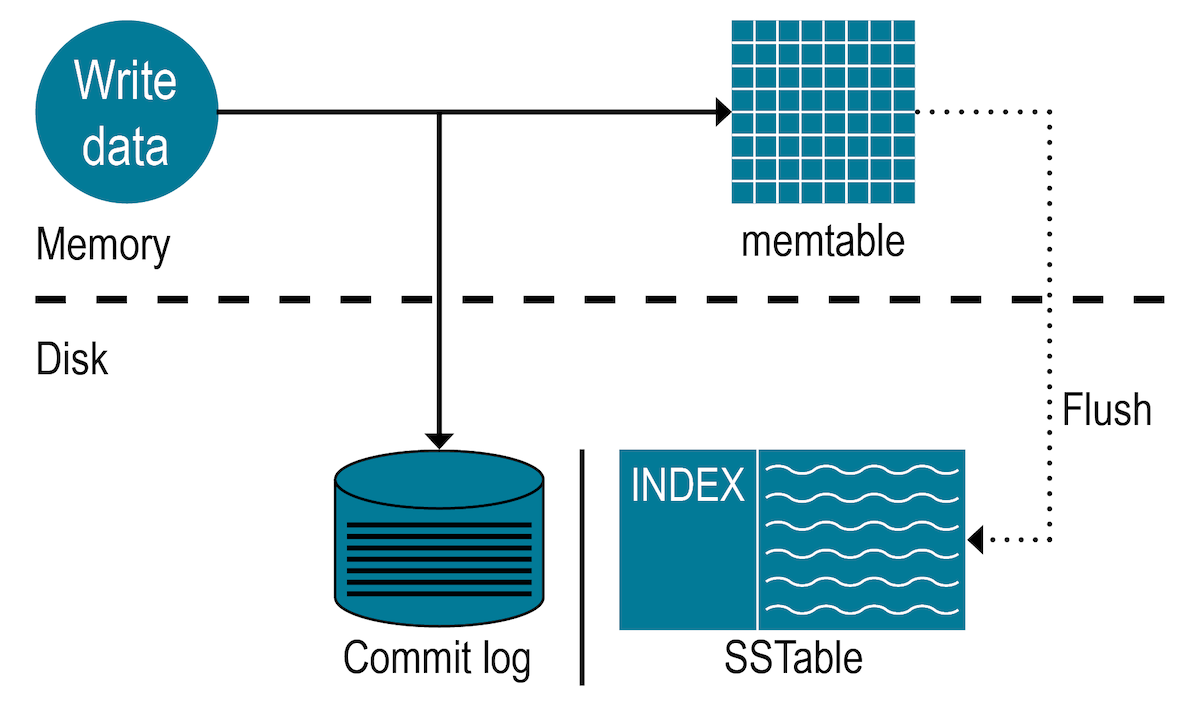
Logging writes and memtable storage
When a write occurs, the database stores the data in a memory structure called memtable. To provide configurable
durability, the database also appends writes to the commit log on disk. When is set to sync, the commit
log receives every write made to a node. These durable writes survive permanently even if
power fails on a node. The memtable is a write-back cache of data partitions that the
database looks up by key. The memtable stores write operations in sorted order until
reaching a configurable limit, and then is flushed.
Flushing data from the memtable
To flush data from the memtable, the database writes data to disk in the memtable-sorted order. A partition index is also created on the disk that maps the tokens to a location on disk.
When the memtable content exceeds the configurable threshold, or the commitlog space exceeds the , the memtable is put in a queue that is flushed to disk. If the data to be flushed exceeds the (which is automatically calculated), the database blocks writes until the next flush succeeds.
You can manually flush a table using nodetool flush or nodetool drain (flushes memtables without listening for connections to other nodes). To reduce the commit log replay time, DataStax recommends flushing the memtable before you restart the nodes. If a node stops working, replaying the commit log restores the writes to the memtable that were there before the node stopped.
Purging commit log segments
The database uses the commit log to rebuild memtables during startup to recover after a crash. During normal operation the commit log is divided into segments. Writes are recorded in order and new segments are created when the current segment reaches the . The database purges commit log segments only after all the data in a segment has been flushed to disk from the memtable. If the commit log directory reaches the maximum size (), the oldest segments are purged and the corresponding tables are flushed to disk.
- Table A has extremely high throughput
- Table B has very low throughput
All the commit log segments contain writes for both table A and table B, as well as system tables. Table A's memtable fills up rapidly and gets flushed frequently; while table B's memtable fills up slowly and is rarely flushed. When the commit log reaches the maximum size, it forces Table B's memtable to flush and then purges the segments.
Table B is flushed into large chunks instead of hundreds of tiny SSTables. If the commit log space and memtable space are equal, Table B's memtable would flush every time Table A is flushed, despite being much smaller. To summarize, if there is more than one table, it makes sense to have a larger space for commit log segments.
Storing data on disk in SSTables
Memtables and SSTables are maintained per table. The commit log is shared among tables. SSTables are immutable, not written to again after the memtable is flushed. Consequently, a partition is typically stored across multiple SSTable files. A number of other SSTable structures exist to assist read operations.
SSTable names and versions
SSTables are files stored on disk. The data files are stored in a data directory that varies with installation. For each keyspace, a directory within the data directory stores each table.
bti:
data/cycling/cyclist_expenses-e4f31e122bc511e8891b23da85222d3d/aa-1-bti-Data.dbcyclingis the keyspace name which distinguishes the keyspace for streaming or bulk loading data.cyclist_expensesis the table name which is followed by a dash and a hexadecimal string (-e4f31e122bc511e8891b23da85222d3d) the unique identifier of the table.aais the SSTable version andbtiis the format. Use this information to determine the DSE version the SSTable is compatible with, see DataStax Enterprise, Apache Cassandra, CQL, and SSTable compatibility.
The database creates a subdirectory for each table, which can be referenced to a chosen physical drive or data volume through a symbolic link (symlink). To improve performance, this capability allows you to move very active tables to faster media, such as SSDs, and also divides tables across all attached storage devices for better I/O balance at the storage layer.
For each SSTable, the database creates the following structures:
- Compression Information (CompressionInfo.db)
- A file holding information about uncompressed data length, chunk offsets, and other compression information
- Data (Data.db)
- The SSTable data
- Digest (Digest.crc32, Digest.adler32, or Digest.sha1)
- A file holding adler32 checksum of the data file
- Bloom filter (Filter.db)
- A structure stored in memory that checks if row data exists in the memtable before accessing SSTables on disk
- Partition index (Partitions.db)
- An index of the partitions keys with pointer to the partition-level in the row index (Row.db) or data file.
- Row index (Row.db)
- Contains the row indices for all partitions in the SSTable.
- Statistics (Statistics.db)
- Statistical metadata about the content of the SSTable
- CRC (CRC.db)
- A file holding the CRC32 for chunks in an a uncompressed file.
- SSTable Table of Contents (TOC.txt)
- A file that stores the list of all components for the SSTable TOC
- Secondary Index (SI_.*.db)
- Built-in secondary index. Multiple SIs may exist per SSTable