DSE Graphとリレーショナル・データベースの類似点と相違点
DSE Graphとリレーショナル・データベースの主な機能の比較。
DSE Graphとリレーショナル・データベースの主な機能の比較。
データ・ストレージ
グラフ・データベースとリレーショナル・データベースは両方ともデータを格納できます。両方のタイプのデータベースをクエリーすることができるので、フィルターされた結果を格納済みのデータから取得できます。データの格納方法とクエリー方法は全く異なります。
リレーショナル・データベース管理システム(RDBMS)ではデータをテーブルに格納します。データの取得用にキーが定義されます。2つの異なるテーブルのデータ間に関係がある場合、そのテーブルをリンクするために外部キーが定義されます。データは正規化されます。つまり、データは重複が生じないように格納されます。リレーショナル・データベースの複雑なクエリーを作成するには、複数のテーブルにアクセスし、取得したデータを結合する必要があります。
グラフ・データベースもデータをテーブルに格納します。DSE GraphはデータをDSEデータベース・テーブルに格納します。グラフ・データベースでは、データ間の関係がデータ・モデルに埋め込まれています。グラフ・データベースのデータ・ストレージは、組み込みのデータ関係を使用する、事前に結合されたRDBMSに例えることができます。構造化クエリー言語(SQL)で時間がかかりエラーが発生しやすい結合を作成するのではなく、グラフを探索してデータを取得します。
スケーリング
グラフ・データベースの追加の利点は、データベースの分散をスケールアウトできることです。グラフ・データベース・クエリーでは、特定の頂点から開始し、クエリー要件に基づいてグラフをフィルタリングします。一般に、取得にはグラフ全体のサブセットのフィルタリングが伴うため、グラフを分割することができます。クエリーは、DSEクラスター内の単一または少数のノードのいずれかで、探索の一部のステップと並行して操作できます。リレーショナル・データベースは、テーブルの相関性と、クエリーを成功させるために多数のテーブルにアクセスしてデータを結合する必要があるため、スケールアウトして分散することは困難です。
インデックスの作成
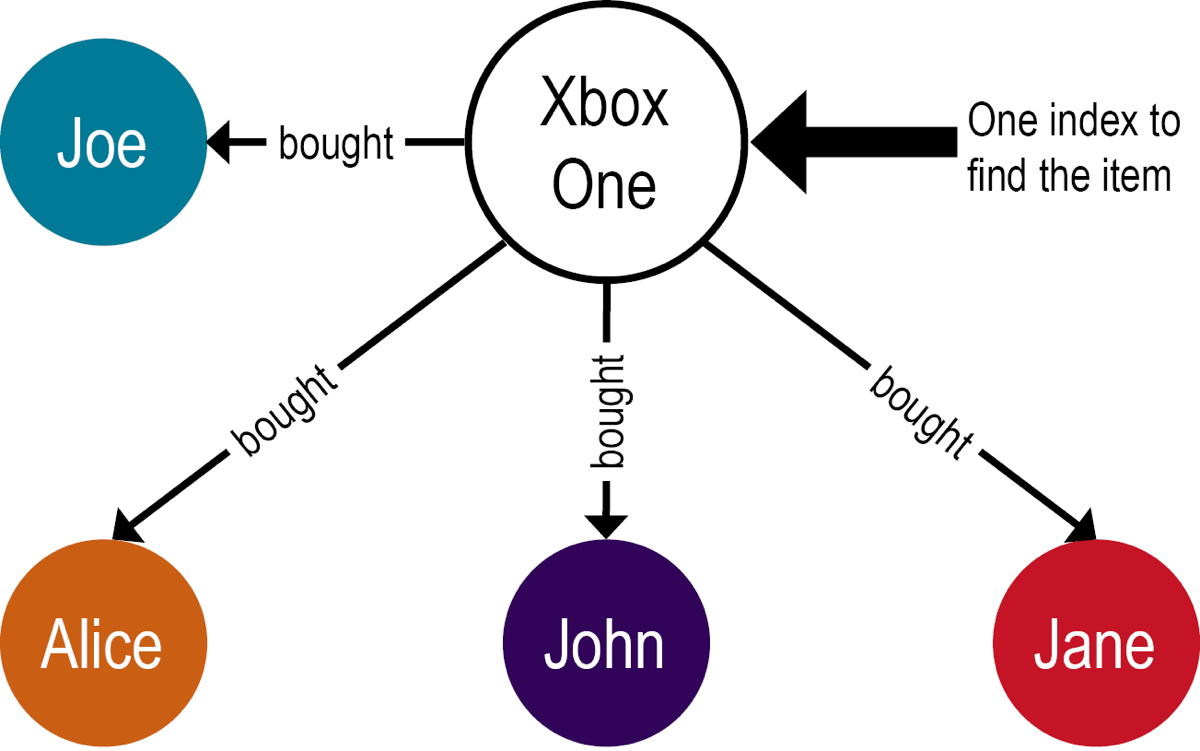
グラフ・データベースとリレーショナル・データベースとの間のインデックス作成手法は大きく異なるため、パフォーマンスに著しく影響する可能性があります。その相違点を例で示します。XBox Oneを購入したすべての購入者を検索するクエリーを考えてみましょう。リレーショナル・データベースでは、そのクエリーに答えるために、3つのテーブルにアクセスします。

- 購入者テーブルの各購入者
- アイテム・テーブルでクエリーされているアイテム
- 購入者-アイテムの結合テーブルの購入者とアイテム
対照的に、グラフ・データベースでは、必要となるアイテムのインデックス検索は1つだけで、次にグラフを各購入者の頂点に移動してクエリーを完了します。
グラフ・データベース・クエリーは、一定時間に近い状態で実行されます。リレーショナル・データベース・クエリーは、B-treeインデックスが想定されている場合、O(log2 N)時間で実行されます。ここでNは、参照する必要のある各外部キーに対するテーブル内のレコード数です。1層クエリーであっても、これはパフォーマンスに大きな違いをもたらします。クエリーがより深くネストされると、パフォーマンスのギャップは大きくなります。
DSE GraphとSQLベースのデータベースを比較する際に考慮すべきもう1つの要素は、複雑なクエリーを記述する容易さです。製品に関する推奨エンジンに必要なクエリーを検討すれば、Gremlin言語の直感的な性質は明白です。

多くの開発者がSQLに精通していますが、この例は、クエリーの複雑さが専門家にとっても扱いにくいものになり得ることを示しています。対照的に、Gremlinのクエリーは左から右に読み込むことができ、各ステップは前のステップから引き継がれます。