ヒンテッド・ハンドオフ:書き込みパス中のリペア
ヒンテッド・ハンドオフ、書き込みパス中のリペアの説明。
データの書き込み中、ノードが応答しないことがあります。応答しない理由として、ハードウェアの問題、ネットワークの問題、またはガーベージ・コレクション(GC)の一時停止が長い時間発生したノードの過負荷が挙げられます。本来の設計上、ヒンテッド・ハンドオフにより、DataStax Enterprise(DSE)は処理能力の低下した状態でクラスターが動作していても、同じ数の書き込みを引き続き実行できます。
障害検知機能によってノードが停止しているとマークされると、ヒンテッド・ハンドオフがcassandra.yamlファイルで有効になっていれば、取りこぼしのあった書き込みは一定期間、コーディネーター・ノードによって格納されます。DataStax 5.0以降では、リプレイを改善するために、ヒントはローカルのhintsディレクトリーに格納されます。ヒントは、ダウンしているノードのターゲットID、データの時間UUIDであるヒントID、DataStax Enterpriseバージョンおよびデータ自体をBLOBとして特定するメッセージIDで構成されます。ヒントは10秒ごとにディスクにフラッシュされるため、ヒントの陳腐化が軽減されます。ノードがオンラインに復旧した情報をゴシップが得ると、コーディネーターは残っているヒントをそれぞれリプレイして、新しく返されたノードにデータを書き込み、その後ヒント・ファイルを削除します。ノードがmax_hint_window_in_ms(デフォルトでは3時間)より長くダウンしている場合、コーディネーターは、新しいヒントの書き込みを停止します。
また、コーディネーターは、障害検知機能がゴシップを通じて検知するには短すぎた停止時間の間にタイムアウトになった書き込みに対応するヒントがあるかどうかを10分間隔で確認します。レプリカ・ノードが過負荷になるか使用できなくなり、障害検知機能によって当該ノードがダウンしているというマークが付けられていなければ、write_request_timeout_in_msによってトリガーされたタイムアウト(デフォルトは10秒)の後、そのノードへの書き込みのほとんど、またはすべてが失敗することが予想されます。コーディネーターはTimeOutException例外を返し、書き込みは失敗しますが、ヒントは保管されます。いくつかのノードが同時に停止した場合、コーディネーターへのメモリーの負荷が過剰になる可能性があります。コーディネーターは現在書き込み中のヒントの数を追跡し、この数が増えすぎると、書き込みを拒否し、OverloadedException例外をスローします。
書き込み要求の整合性レベルは、ヒントが書き込まれるかどうかに影響し、その後、書き込み要求が失敗するかどうかにも影響します。2つのノード、AとBで構成されるクラスターがあり、レプリケーション係数が1である場合は、各行が1つのノードのみに格納されているとします。整合性レベルを1として行KがノードAに書き込まれる前に、コーディネーターであるノードAがダウンしたとします。この場合は、指定した整合性レベルを満たすことができないだけでなく、ノードAはコーディネーターであるためヒントを格納できません。ノードBはコーディネーターであるためヒントを格納していないため、データを受け取っていません。そのため、ノードBはデータを書き込むことができません。コーディネーターは、クライアントによって指定された整合性レベルを満たすことができない場合、稼働はしていてもヒントを作成しようとしないレプリカの数をチェックします。ヒンテッド・ハンドオフ障害が発生し、UnavailableException例外を返します。書き込み要求は失敗し、ヒントは書き込まれません。
一般的に、書き込み要求の失敗を回避するには、クラスター内に十分な数のノードを確保し、レプリケーション係数を十分な値にすることが推奨されます。たとえば、A、B、Cの3つのノードから構成され、レプリケーション係数が2のクラスターがあるとします。行Kをコーディネーター(この場合は、ノードA)に書き込むと、ノードCがダウンしている場合でも、ONEまたはQUORUMの整合性レベルを満たすことができます。その理由は何でしょうか。AとBの両方のノードがデータを受け取るため、整合性レベルの要件が満たされます。ヒントはノードCに格納され、ノードCが稼働すると書き込まれます。その間に、コーディネーターは、書き込みが成功したことを確認できます。
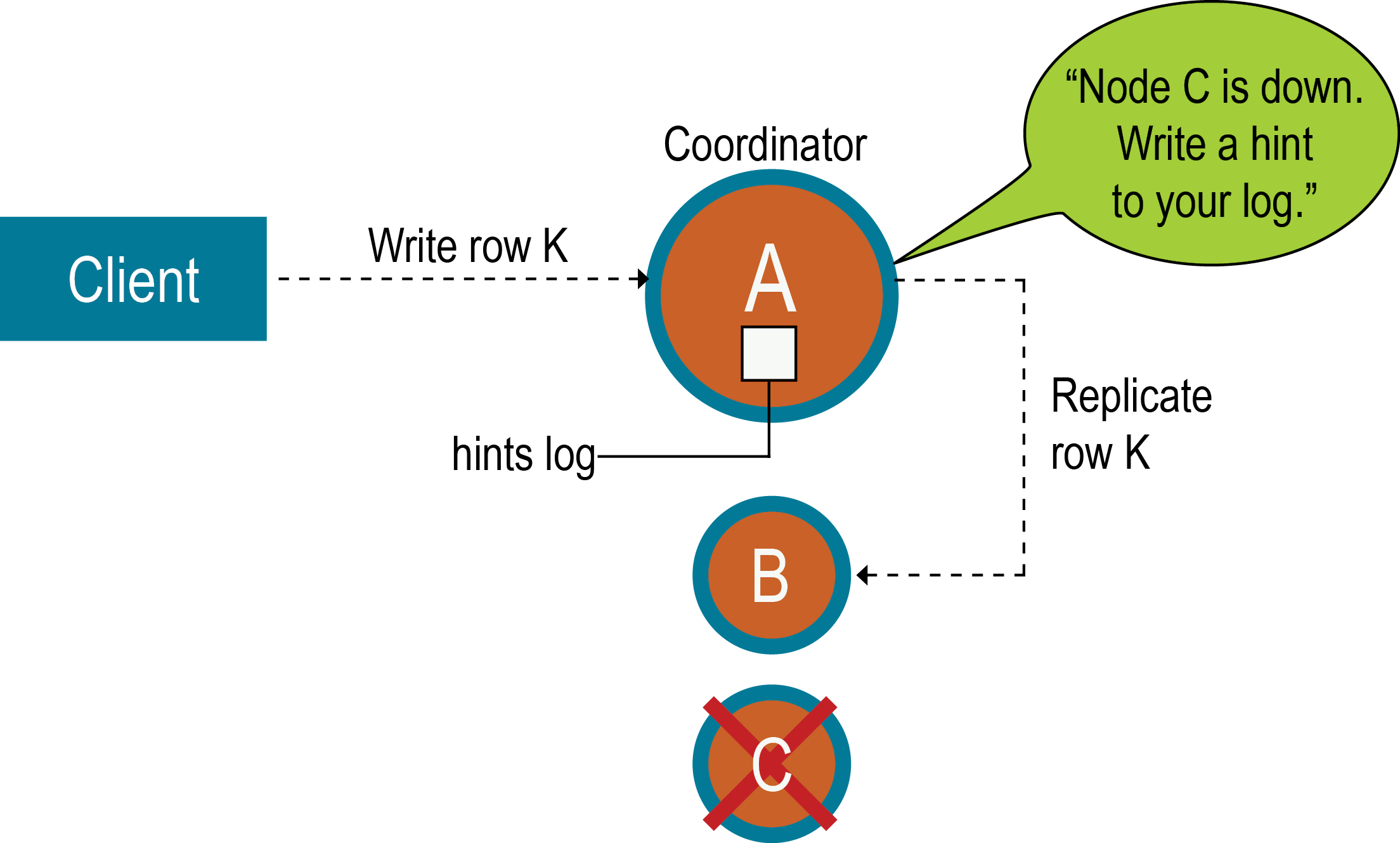
通常のレプリカがすべてダウンしており、整合性レベルONEを満たすことができない場合、DataStax Enterpriseに書き込みが受け入れられる必要があるアプリケーションのために、データベースに整合性レベルANYが用意されています。ANYでは、書き込みの永続性が確保され、該当するレプリカ対象が使用可能になってヒントのリプレイを受け取ったときに読み取り可能になることが保証されます。
どのノードもコーディネーターになることができるため、停止したノードは未配信のヒントを格納している場合があります。また、停止したノード上にあるデータも、長い間ダウン時間が続くと、陳腐化します。長期にわたってノードがダウンしていた場合は、手動リペアを実行してください。
- どのデータが欠落しているかをクラスターの残りの部分に正確に伝えるための履歴データが失われる。
- 障害が発生したノードがコーディネーションを行った要求に基づくリプレイされていないヒントが失われる。
ノードの使用を廃止にするか、nodetool removenodeコマンドを使用してクラスターからノードを取り除くと、データベースは、存在しなくなったノードを対象とするヒントを自動的に削除し、削除されたテーブルのヒントを削除します。
ヒント・ストレージに関する詳しい説明については、「Cassandra 3.0の新機能:ヒントのストレージと配信の改善」ブログを参照してください。基本的な情報については、「最新のヒンテッド・ハンドオフ」ブログを参照してください。
|
パッケージ・インストールInstaller-Servicesインストール |
/etc/dse/cassandra/cassandra.yaml |
|
tarボール・インストールInstaller-No Servicesインストール |
installation_location/resources/cassandra/conf/cassandra.yaml |