データはどのようにして読み取られるか
DataStax Enterpriseが、読み取り要求を満たすために、アクティブなmemtableと複数の可能性があるSSTableの結果を組み合わせる方法。
DataStax Enterpriseデータベースは、読み取り要求を満たすために、アクティブなmemtableと複数の可能性があるSSTableの結果を組み合わせる必要があります。
- memtableをチェックします
- 行キャッシュが有効な場合は、それをチェックします
- ブルーム・フィルターをチェックします
- パーティション・キー・キャッシュが有効な場合は、それをチェックします
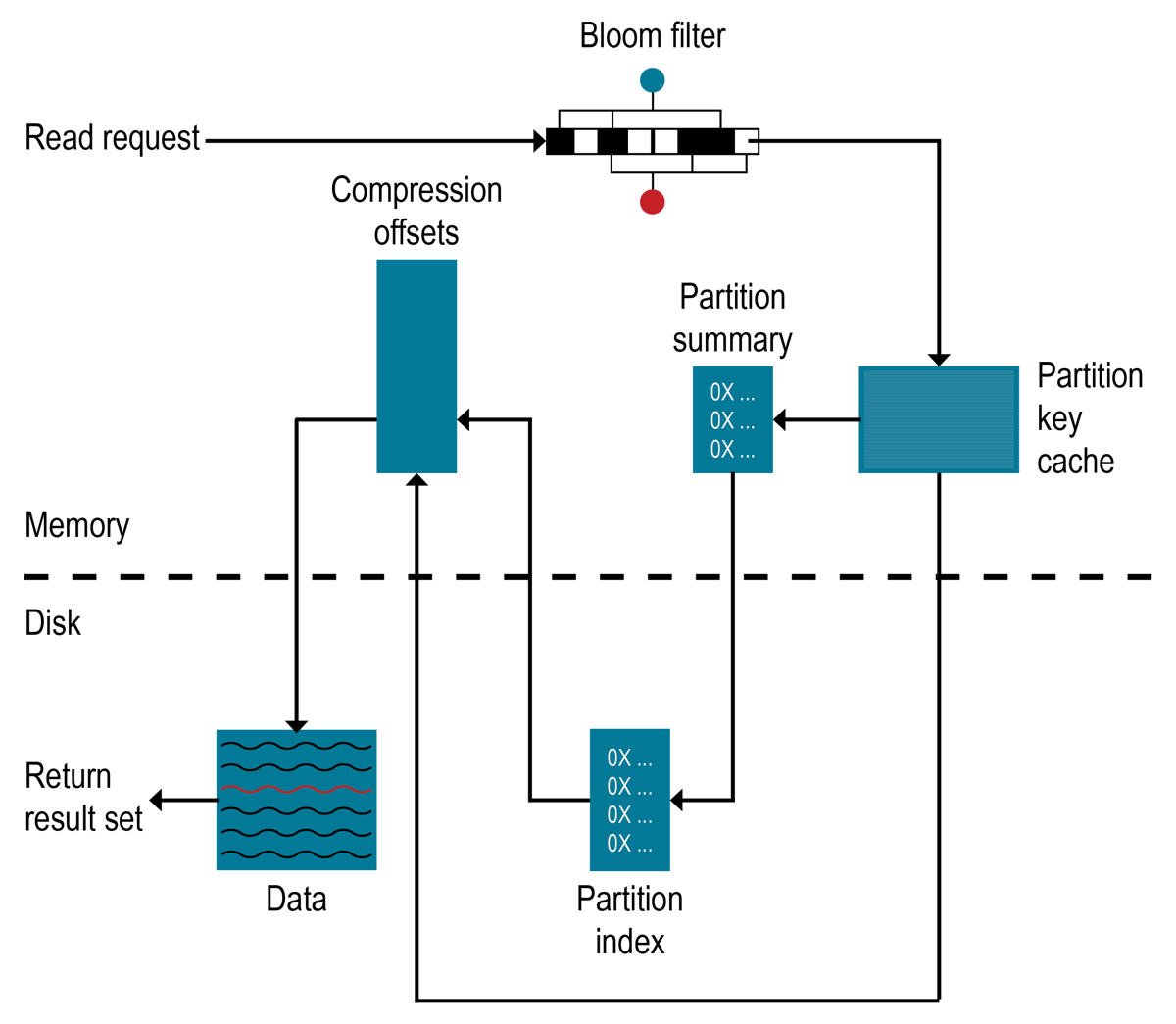
- パーティション・キー・キャッシュ内でパーティション・キーが見つかった場合は、圧縮オフセット・マップに直接移動します。見つからなかった場合は、パーティション・サマリーをチェックします
パーティション・サマリーがチェックされると、パーティション・インデックスがアクセスされます
- 圧縮オフセット・マップを使用して、ディスク上のデータを見つけます
- ディスク上のSSTableからデータをフェッチします
memtable
memtableに希望するパーティション・データが含まれている場合は、そのデータが読み取られ、SSTableからのデータとマージされます。SSTableデータは、以下の手順に示すようにアクセスされます。
行キャッシュ
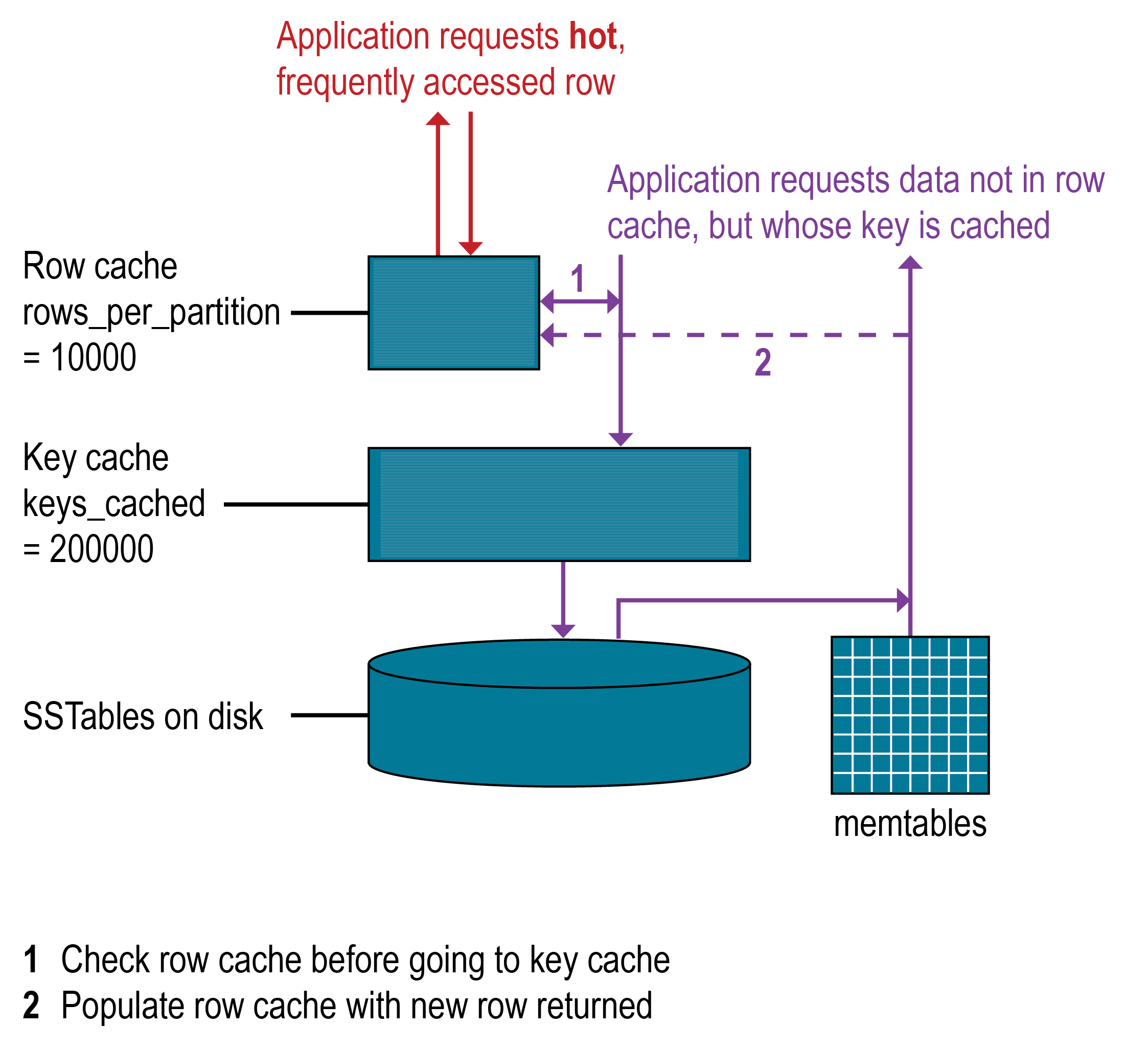
どのようなデータベースでも、最も需要があるデータがメモリーに入っているときに読み取りが最速になります。負荷の95%を読み取り操作が占めるような読み取りが非常に多い操作は、行キャッシュによってある程度改善されますが、OSのページ・キャッシュはパフォーマンスの向上に最適です。書き込みが多い操作に行キャッシュを使用することはできません。行キャッシュが有効な場合は、ディスク上のSSTableに格納されているパーティション・データのサブセットがメモリーに格納されます。DataStax Enterprise 5.0以降では、行キャッシュは、JVMのガーベージ・コレクション圧力を軽減する実装方法を使用して、完全なオフヒープ・メモリーに格納されます。行キャッシュに格納されたサブセットは、指定された時間、構成可能なメモリー量を使用します。行キャッシュは、満杯になると、LRU(least-recently-used)排除方式に従ってメモリーを再要求します。
行キャッシュのサイズは、格納する行の数として構成できます。格納する行数を構成すると、「最後の10項目」のクエリーの読み取りが非常に速くなるため便利です。行キャッシュが有効な場合は、希望するパーティション・データが行キャッシュから読み取られ、そのデータを探すディスクへの2回のシークが節約される可能性があります。行キャッシュに格納される行は、アクセス頻度の多い行で、アクセスされたときにSSTableから行キャッシュにマージされて保存されます。格納後は、そのデータが後続のクエリーに利用されます。行キャッシュはライトスルーではありません。その行に対する書き込み要求があった場合、その行のキャッシュは無効にされて、読み取りが行われるまで、再度キャッシュされることはありません。同様に、パーティションが更新されると、そのパーティション全体がキャッシュから排除されます。希望するパーティション・データが行キャッシュで見つからない場合は、ブルーム・フィルターがチェックされます。
ブルーム・フィルター
最初にDataStax Enterpriseデータベースは、ブルーム・フィルターをチェックして、要求されたパーティション・データが存在する可能性があるSSTableを見つけます。ブルーム・フィルターは、オフヒープ・メモリー内に格納されています。各SSTableはブルーム・フィルターに関連付けられています。ブルーム・フィルターによって、SSTableが特定のパーティション・データを含まないようにすることができます。また、ブルーム・フィルターは、パーティション・データがSSTableに格納されている可能性を見つけることもできます。これによって、キーのプールが狭められ、パーティション・キーの検索プロセスが高速になります。ただし、ブルーム・フィルターは確率的な機能であるため、結果が偽陽性になり可能性があります。ブルーム・フィルターによって識別されたすべてのSSTableにデータが存在するわけではありません。ブルーム・フィルターでSSTableが見つからない場合、データベースはパーティション・キー・キャッシュをチェックします。
ブルーム・フィルターは、10億のパーティションごとに約1~2ギガバイト(GB)まで拡大します。極端な例では、行ごとに1つのパーティションがある場合があるため、1台のマシンがそのようなエントリーを優に10億個持つこともあります。パフォーマンスを向上させるためにメモリーを使っても構わないのであれば、ブルーム・フィルターを調整することができます。
パーティション・キー・キャッシュ
パーティション・キー・キャッシュは、有効な場合、パーティション・インデックスのキャッシュをオフヒープ・メモリーに格納します。キー・キャッシュは小さな構成可能なメモリー量を使用し、「ヒット」するたびに読み取り操作時の1回のシークが節約されます。キー・キャッシュ内でパーティション・キーが見つかると、圧縮オフセット・マップに直接移動して、データが存在する、ディスク上の圧縮ブロックを見つけることができます。パーティション・キー・キャッシュは、一度ウォームアップされるとより良く機能し、コールド・スタートの読み取りと比べてパフォーマンスが非常に向上する可能性があります。ウォームアップしている場合、キー・キャッシュは、キャッシュに格納されているキーをまだパージしていません。ノード上でメモリーが非常に制限されている場合は、キー・キャッシュに保存されるパーティション・キーの数も制限される可能性があります。キー・キャッシュでパーティション・キーが見つからなかった場合は、パーティション・サマリーが検索されます。
パーティション・キー・キャッシュのサイズは、キー・キャッシュに格納するパーティション・キーの数として構成できます。
パーティション・サマリー
パーティション・サマリーは、パーティション・インデックスのサンプリングを格納するオフヒープ・インメモリー構造です。パーティション・インデックスにはすべてのパーティション・キーが含まれていますが、パーティション・サマリーではX個のキーごとに1つのキーがサンプリングされ、各X番目のキーの場所がインデックス・ファイルにマップされます。たとえば、パーティション・サマリーが20個のキーごとにサンプリングするように設定されている場合、SSTableファイルの開始として最初のキーの場所と、20番目のキーおよびそのファイル内の場所がファイルに格納され、その後同様に続きます。パーティション・キーの場所は大雑把なため、パーティション・サマリーでは、パーティション・データの場所を見つけるためのスキャンが短かくなります。可能性があるパーティション・キーの値の範囲が見つかると、パーティション・インデックスが検索されます。
パーティション・サマリーの細分性を上げると、使用するメモリーの量が増えるので、サンプル頻度を構成することによってパフォーマンスとメモリー量のトレードオフを図ることができます。サンプル頻度は、テーブル定義のindex intervalプロパティを使用して変更します。固定量のメモリーを構成するには、index_summary_capacity_in_mbプロパティを使用します。デフォルトはヒープ・サイズの5%です。
パーティション・インデックス
パーティション・インデックスはディスク上に存在し、オフセットにマップされたすべてのパーティション・キーのインデックスを格納しています。パーティション・キーの範囲についてパーティション・サマリーがチェックされた場合、検索はパーティション・インデックスに移動し、希望するパーティション・キーの場所をシークします。移動した範囲全体にわたって1回のシークとカラムのシーケンシャルな読み取りが実行されます。パーティション・インデックスでは、見つけた情報を使用して圧縮オフセット・マップに移動し、データが存在するディスク上の圧縮ブロックを見つけます。パーティション・インデックスを検索しなければならない場合は、希望するデータを見つけるためにディスクを2回シークする必要があります。
圧縮オフセット・マップ
圧縮オフセット・マップは、圧縮状態でテラバイト(TB)ごとに1~3ギガバイト(GB)まで拡大します。データを圧縮するほど、圧縮ブロックの数が増え、圧縮オフセット・テーブルが大きくなります。圧縮オフセット・マップの参照によりCPUリソースが使用されますが、圧縮はデフォルトで有効になっています。圧縮を有効にしておくと、ページ・キャッシュの効率が上がり、通常はそれだけの価値があります。