データはどのように書き込まれるか
DataStax Enterpriseデータベースがどのようにデータの書き込みと格納を行っているか理解する。
DataStax Enterpriseデータベースは、書き込みの即時ロギングから始まり、ディスクへのデータの書き込みが終わるまで、書き込みパスの複数の段階でデータを処理します。
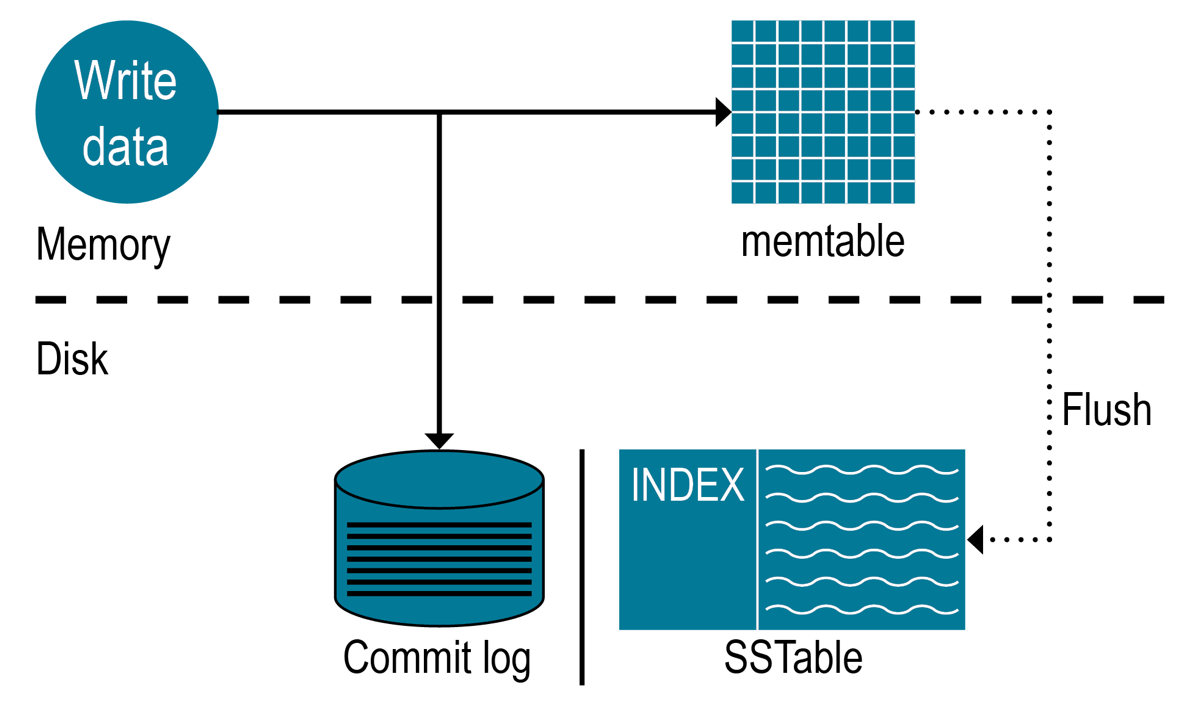
- コミット・ログへのデータのログ記録
- memtableへのデータの書き込み
- memtableからのデータのフラッシュ
- ディスク上のSSTableへのデータの格納
書き込みのログ記録とmemtableへの保存
書き込みが発生すると、データベースはmemtableと呼ばれるメモリー構造にデータを格納し、構成可能な永続性を確保します。さらに、ディスクのコミット・ログに追加書き込みします。このコミット・ログは、ノードへのすべての書き込みを受け取ります。そしてこれらの永続性のある書き込みは、ノードで電源喪失があっても恒久的に存続します。memtableは、データベースがキーで検索するデータ・パーティションのライトバック・キャッシュです。memtableは構成可能な制限に達するまでソートされた順序で書き込みを格納し、その後でフラッシュされます。
memtableからのデータのフラッシュ
データをフラッシュするために、データベースはmemtableのソート順にデータをディスクに書き込みます。トークンをディスク上の場所にマップするパーティション・インデックスがディスク上に作成されます。
memtableの内容が構成可能なしきい値を超えるか、commitlog領域がcommitlog_total_space_in_mbを超えると、memtableは、ディスクにフラッシュされるキューに置かれます。cassandra.yamlファイルでmemtable_heap_space_in_mb設定またはmemtable_offheap_space_in_mb設定を構成できます。フラッシュ対象データがmemtable_cleanup_thresholdを超えると、データベースは次のフラッシュが成功するまで書き込みをブロックします。
nodetool flushまたはnodetool drainを使用すると、手動でテーブルをフラッシュできます(他のノードへの接続をリッスンせずにmemtableをフラッシュします)。コミット・ログのリプレイ時間を短縮するために、DataStaxでは、ノードを再起動する前にmemtableをフラッシュすることを推奨しています。ノードが停止した場合、コミット・ログをリプレイすると、停止前にそこにあった書き込みがmemtableに復元されます。
コミット・ログ・セグメントのパージ
データベースは、コミット・ログを使用してmemtableを再構築します。コミット・ログは、セグメントに分かれています。書き込みは順番に記録され、現在のセグメントがcommitlog_segment_size_in_mbに達すると、新しいセグメントが作成されます。データベースは、セグメント内のすべてのデータがmemtableからディスクにフラッシュされた後にのみ、コミット・ログ・セグメントをパージします。コミット・ログ・ディレクトリーが最大サイズ(commitlog_total_space_in_mb)に達すると、最も古いセグメントがパージされ、対応するテーブルがディスクにフラッシュされます。
- スループットが非常に高いテーブルA
- スループットが非常に低いテーブルB
すべてのコミット・ログ・セグメントには、システム・テーブルのほか、テーブルAとBの両方の書き込みが含まれています。テーブルAのmemtableはすぐに満杯になり、頻繁にフラッシュされます。一方、テーブルBのmemtableは満杯になるまで時間がかかり、フラッシュされることはほとんどありません。コミット・ログが最大サイズに達すると、テーブルBのmemtableが強制的にフラッシュされ、セグメントがパージされます。
テーブルBは、何百もの小さなSSTableではなく、大きなチャンクにフラッシュされます。commitlog領域とmemtable領域が等しい場合は、テーブルAがフラッシュされるたびに、小さくはなりますが、テーブルBのmemtableがフラッシュされます。要約すると、複数のテーブルがある場合は、commitlogセグメント用に大きな領域を確保した方がよいでしょう。
ディスク上のSSTableへのデータの格納
memtableとSSTableは、テーブルごとに維持されます。コミット・ログはテーブル間で共有されます。SSTableは不変であり、memtableがフラッシュされた後に再度書き込まれることはありません。この結果、パーティションは通常、複数のSSTableファイルにわたって格納されます。読み取り操作を支援するために他の多くのSSTable構造が存在します。
SSTableの名前とバージョン
SSTableとはディスクに格納されたファイルです。データ・ファイルはデータ・ディレクトリーに格納されますが、インストール時に場所が変わります。キー・スペースごとに、データ・ディレクトリー内のディレクトリーに各テーブルが格納されます。たとえば、/data/ks1/cf1-5be396077b811e3a3ab9dc4b9ac088d/la-1-big-Data.dbはデータ・ファイルを表しています。ks1は、ストリーミングまたは一括読み込みデータのキースペースを区別するキースペース名を表します。この例の16進数文字列、5be396077b811e3a3ab9dc4b9ac088dは、テーブル名に追加され、一意のテーブルIDを表します。
データベースではテーブルごとにサブディレクトリーが作成されるため、選択した物理ドライブやデータ・ボリュームに対してテーブルのsymlinkを作成することができます。パフォーマンスを向上させる場合は、この機能を使用することで、非常にアクティブなテーブルをSSDのような高速メディアに移動したり、接続されているすべてのストレージ・デバイスでテーブルを分配して、ストレージ層のI/Oバランスを改善したりすることが可能になります。
データベースは、SSTableごとに以下の構造体を作成します。
- データ(Data.db)
- SSTableデータ
- プライマリ・インデックス(Index.db)
- データ・ファイル内の位置へのポインターを持つ行キーのインデックス
- ブルーム・フィルター(Filter.db)
- ディスク上のSSTableにアクセスする前にmemtableに行データが存在するかどうかを確認する、メモリーに格納された構造
- 圧縮情報(CompressionInfo.db)
- 圧縮されていないデータの長さ、チャンク・オフセット、およびその他の圧縮に関する情報を保持するファイル
- 統計(Statistics.db)
- SSTableの内容についての統計メタデータ
- ダイジェスト(Digest.crc32、Digest.adler32、Digest.sha1)
- データ・ファイルのadler32チェックサムを保持するファイル
- CRC(CRC.db)
- 非圧縮ファイル内のチャンク用のCRC32を保持するファイル
- SSTableインデックス・サマリー(SUMMARY.db)
- メモリーに格納されたパーティション・インデックスのサンプル。
- SSTableの目次(TOC.txt)
- SSTable TOCのすべてのコンポーネントのリストを格納するファイル
- セカンダリ・インデックス(SI_.*.db)
- 組み込みセカンダリ・インデックス。SSTableごとに複数のSIが存在する可能性があります。
|
パッケージ・インストールInstaller-Servicesインストール |
/etc/dse/cassandra/cassandra.yaml |
|
tarボール・インストールInstaller-No Servicesインストール |
installation_location/resources/cassandra/conf/cassandra.yaml |