グラフ・インデックスの作成
グラフのインデックスの作成。
nameで示すように、複数の頂点ラベルで使用できます。グラフ探索は、「インデックスの使用」で示すように、頂点ラベルおよびプロパティ・キーの両方が指定された場合はインデックスのみを使用します。グラフ内のすべての頂点ラベルにまたがるインデックスは、DSE Graphでサポートされていません。手順
-
セカンダリ・インデックスを作成します。
schema.vertexLabel('recipe').index('byRecipe').secondary().by('name').add()インデックスの頂点ラベルおよびプロパティ・キーを、
vertexLabel()ステップおよびby()ステップでそれぞれ識別します。index()ステップでインデックスに名前を付けます。secondary()ステップは、インデックスをセカンダリ・インデックスとして識別します。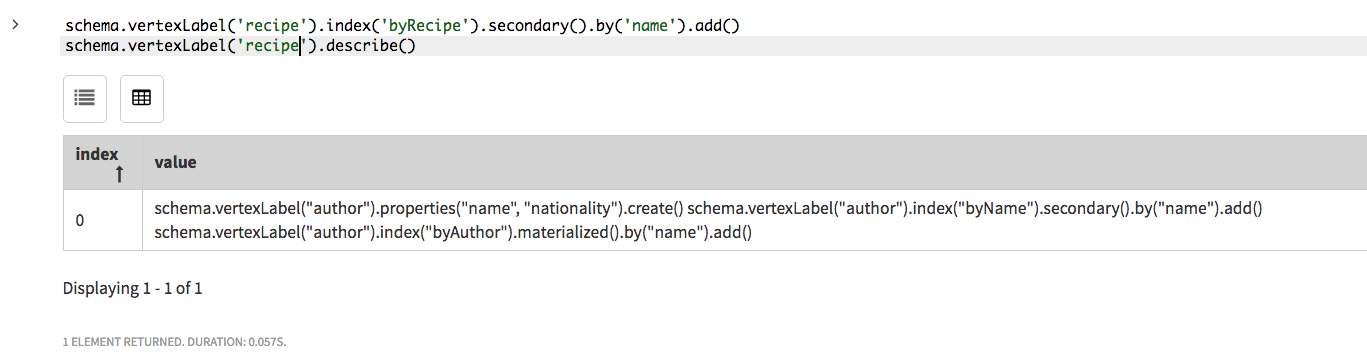
-
マテリアライズド・ビュー・インデックスを作成します。
schema.vertexLabel('author').index('byAuthor').materialized().by('name').add()インデックスの頂点ラベルおよびプロパティ・キーを、
vertexLabel()ステップおよびby()ステップでそれぞれ識別します。index()ステップでインデックスに名前を付けます。materialized()ステップは、インデックスをマテリアライズド・ビュー・インデックスとして識別します。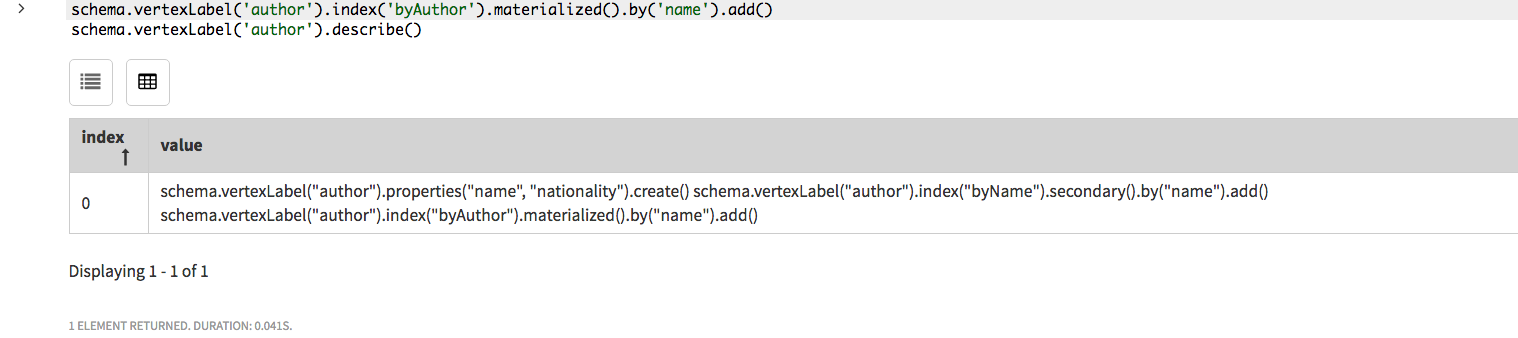
-
検索インデックスを作成します。この検索インデックスには1つのプロパティ・キーがインデックス指定されています。複数のプロパティ・キーがインデックス指定されている場合は、追加の
by()ステップを連結します。schema.vertexLabel('recipe').index('search').search().by('instructions').asText().add()インデックスの頂点ラベルおよびプロパティ・キーを、
vertexLabel()ステップおよびby()ステップでそれぞれ識別します。index()ステップでインデックスsearchに名前を付けます。使用できるのは、この命名規則のみです。search()ステップは、インデックスを検索インデックスとして識別します。このインデックスは、全文インデックスを使用して検索されます。注: 頂点ラベルごとに作成できる検索インデックスは1つだけです。 -
検索インデックスは文字列インデックス・オプションも指定できます。次の例では、文字列インデックスを識別します。
schema.vertexLabel('recipe').index('search').search().by('instructions').asString().add()asString()も、使用可能な検索インデックス・オプションです。 -
さらに一般的には、検索インデックスは複数のカラムを指定します。
schema.vertexLabel('recipe').index('search').search().by('instructions').asText().by('name').asString().add()DSE 5.1以降では、トークン化(TextField)形式と非トークン化(StrField)形式の両方でテキスト検索インデックスがデフォルトで作成されます。つまり、作成されたすべてのテキスト頂点プロパティでどのテキスト述語(token、tokenPrefix、tokenRegex、eq、neq、regex、prefix)でも使用できます。実際的には、asString()メソッドを使用して検索インデックスを作成する必要があるのは、在庫カテゴリ(食卓用金物、靴、衣服)など、トークン化とテキスト解析が絶対に役に立たない場合だけです。複数の文章から成る長い記述など、トークン化されたテキストの検索には、asText()メソッドが役に立ちます。クエリー最適化ツールは、使用されているテキスト述語に基づいて、解析済みインデックスと未解析インデックスのどちらを使用するかを選択します。注: DSE 5.1より前では、テキスト・プロパティ・データの検索インデックスは、asString()として指定されていない場合にデフォルトでasText()に設定されていました。 -
検索インデックスでは、テキスト以外のデータ型も含めることもできます。
schema.vertexLabel('recipe').index('search').search().by('year').by('name').asString().add()テキスト以外のデータ型はスキーマから推測され、DSE Searchはこれに相当するSolrデータ型を使用します。この例では、yearでは整数としてインデックスが作成されます。注意:Decimalデータ型ではSolrDecimalStrFieldとしてインデックスが作成されます。Int、Long、FloatまたはDoubleを使用し、Solrデータ型がソート・クエリーおよび範囲クエリーに使用されていることを確認します。 -
地理空間データの検索インデックスを作成します。
schema.propertyKey("coordinates").Point().single().create() schema.propertyKey("name").Text().single().create() schema.vertexLabel("place").properties("coordinates", "name").create() schema.vertexLabel("place").index("search").search().by("name").asText().by("coordinates").add()この例では、プロパティcoordinatesは経度と緯度を定義するポイントを表します。検索インデックスには、妥当な
asText()またはasString()メソッドを持たないcoordinatesが含まれます。追加情報については、「地理空間スキーマ」を参照してください。 -
タイムスタンプ・データの検索インデックスを作成します。
schema. propertyKey('review_ts).Timestamp().create() schema.propertyKey('name').Text().create() schema.vertexLabel('rating').properties('name', 'review_ts').create() schema.vertexLabel('rating').index('search').search().by('name','review_ts').add()
-
エッジ・インデックスを作成します。エッジ・インデックスは、特定の頂点ラベルに対する頂点中心インデックスです。たとえば、次の例では、レビュー担当者が評価するものをインデックス作成します。
schema.vertexLabel('reviewer').index('ratedByStars').outE(rated).by('stars').add()インデックスの頂点ラベルおよびプロパティ・キーを、
vertexLabel()ステップおよびby()ステップでそれぞれ識別します。index()ステップでインデックスに名前を付けます。outE()ステップは、エッジの方向を定義するために使用されます。 -
内向きエッジと外向きエッジの両方のインデックスを作成するエッジ・インデックスを作成します。
schema.vertexLabel('reviewer').index('ratedByStars').bothE(rated).by('stars').add()インデックスの頂点ラベルおよびプロパティ・キーを、
vertexLabel()ステップおよびby()ステップでそれぞれ識別します。index()ステップでインデックスに名前を付けます。bothE()ステップは、エッジの方向を定義するために使用されます。
-
プロパティ・インデックスを作成します。プロパティ・インデックスは、特定の頂点ラベルに対する頂点中心インデックスです。
schema().vertexLabel('author').index('byLocation').property('country').by('livedIn').add()インデックスの頂点ラベルおよびプロパティ・キーを、
vertexLabel()ステップおよびproperty()ステップでそれぞれ識別します。index()ステップでインデックスに名前を付けます。by()ステップは、プロパティのメタプロパティを定義するために使用されます。。
-
インデックス作成を確認します。
schema.describe()
-
頂点ラベルを指定し、
describe()ステップを使用すると、インデックスに関する詳細情報が表示されます。インデックスの作成に使用できるスキーマが表示されます。schema().vertexLabel('author').describe()==>schema.vertexLabel("author").properties("name", "gender", "nationality").create() schema.vertexLabel("author").index("byName").secondary().by("name").add() schema.vertexLabel("author").index("byAuthor").materialized().by("name").add() -
すべての
vertexIndexをフィルターするスキーマ探索を使用すると、すべてのインデックスに関する情報が表示されます。schema.traversal().V().hasLabel('vertexIndex').valueMap()==>{name=[byName], type=[Secondary]} ==>{unique=[false], name=[byIngredient], type=[Materialized]} ==>{unique=[false], name=[byReviewer], type=[Materialized]} ==>{unique=[false], name=[byRecipe], type=[Materialized]} ==>{unique=[false], name=[byMeal], type=[Materialized]} -
すべての
vertexIndexをフィルターするスキーマ探索を使用し、インデックス数のカウントを取得します。schema.traversal().V().hasLabel('vertexIndex').count()==>5