検索インデックスの使用
グラフ探索用検索インデックスの使用。
DSE GraphではDSE Searchインデックスを利用して、プロパティごとに頂点を効率的にフィルター処理し、クエリーのレイテンシーを削減します。DSE Searchでは変更されたApache Solrを使用して、検索インデックスを作成します。Graphの検索インデックスは、テキスト形式、数値、および地理空間データを使用して作成できます。
検索述語を含む探索クエリーは、検索インデックスが存在するかどうかにかかわらず完了できることを覚えておくことが重要です。ただし、フル・グラフ・スキャンは検索インデックスなしで行われ、グラフが大きくなるにつれてパフォーマンスが大きく低下します。これは、実稼働環境では許容できないソリューションです。データを挿入してグラフのクエリーを実行する前の、スキーマの作成中に検索インデックスを作成します。検索インデックスは、DSE SearchがDSE Graphとともに起動されている場合にのみ作成されます。検索インデックスを使用する場合、クエリーはクラスター内のDSE Searchノードで実行する必要があります。
一般的に、探索ステップには頂点ラベルが関与し、プロパティ・キーと特定のプロパティ値を含めることができます。探索では、g.V()に続くステップは、通常はインデックスを探索するステップになります。中間探索V()ステップが呼び出された場合は、インデックスを使用した追加のステップを利用して、探索される頂点のリストを絞り込むことができます。
asString()メソッドを使用して検索インデックスを作成する必要があるのは、在庫カテゴリ(食卓用金物、靴、衣服)など、トークン化とテキスト解析が絶対に役に立たない場合だけです。複数の文章から成る長い記述など、トークン化されたテキストの検索には、asText()メソッドが役に立ちます。クエリー最適化ツールは、使用されているテキスト述語に基づいて、解析済みインデックスと未解析インデックスのどちらを使用するかを選択します。asString()として指定されていない場合にデフォルトでasText()に設定されていました。asText()を使用して定義されているか、定義されていない(デフォルト)プロパティ・キー・インデックスでは、検索に次のオプションを使用できます。asString()を使用して定義されているプロパティ・キー・インデックスでは、検索に次のオプションを使用できます。asText()で作成したプロパティ・キー・インデックスとともにeq()検索を使用することはできません。これらのインデックスにはトークン化されたデータが含まれているため、テキストの完全一致検索には適していないためです。fuzzyとtokenFuzzyの2つの述語はそれぞれTextFieldsおよびStrFieldsとともに使用できます。一方、phraseはTextFieldsのみと使用できます。手順
-
頂点ラベル
recipeに対する「インデックスの作成」に含まれている検索インデックス例は、以下のすべての例で使用されます。schema.vertexLabel('recipe').index('search').search(). by('instructions').asText(). by('name').asString().add()この検索インデックスではDSE Searchを使用して、トークン化を使用したフルテキストとして
instructionsのインデックスを作成し、文字列としてnameのインデックスを作成します。DSE 5.1以降では、非トークン化データとしてインデックスを作成するプロパテのみがasString()を指定する必要があります。トークン化されたデータとしてのみインデックスを作成する必要のあるプロパティが存在する場合は、asText()を指定します。
-
探索クエリーでは、トークン検索を使用して、手順内に
Sauteの単語を含むすべてのレシピの名前を検索します。token()メソッドを、指定された単語とともに使用します。g.V().has('recipe','instructions', token('Saute')).values('name')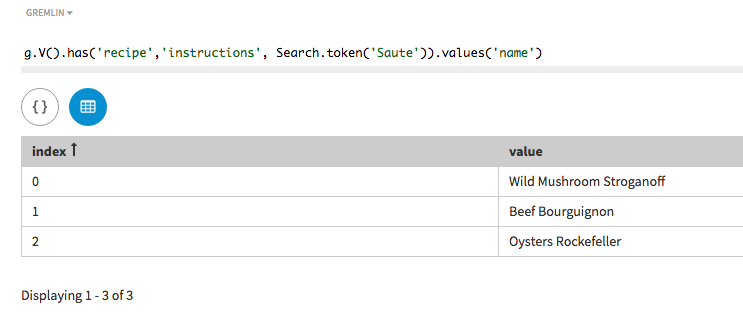

-
探索クエリーでは、トークン・プレフィックス検索を使用して、手順内に
Seaのプレフィックスを含む単語が含まれているすべてのレシピの名前をリストします。tokenPrefix()メソッドを、指定されたプレフィックス(一連の英数字)とともに使用します。g.V().hasLabel('recipe').has('instructions', tokenPrefix('Sea')).values('name','instructions')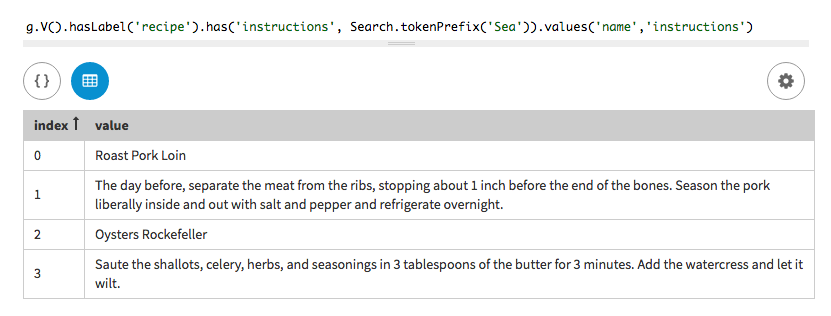
2つのレシピが返されます。1つは手順にSeasonという単語を含み、もう1つはseasoningsという単語を含んでいます。
tokenPrefix()によるインデックスの作成では大文字と小文字は区別されません。
-
探索クエリーでは、トークンの正規表現(regex)検索を使用して、指定された正規表現を含む単語が含まれたすべてのレシピを検索します。
.*sea*in.*regexは、手順内の任意の数の任意の文字の間にseaの文字があり、その後にinの文字に続いてさらに任意の数の任意の文字があるレシピを検索し、そのレシピ名をリストします。tokenRegex()メソッドを、指定されたregexとともに使用します。g.V().hasLabel('recipe').has('instructions', tokenRegex('.*sea.*in.*')).values('name','instructions')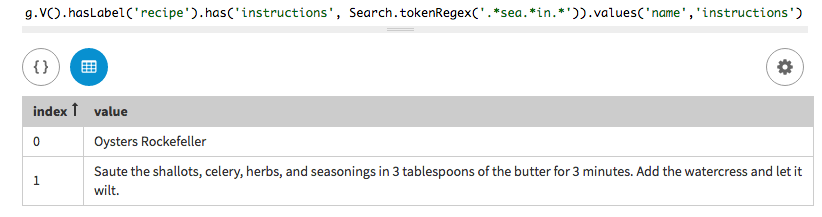
このクエリーでは、Oysters Rockefellerのレシピのみが返されています。Roast Pork Loinのレシピ内のSeasonの単語は正規表現の要件を満たしていないためです。
-
探索クエリーでは、トークン以外の検索を使用して、レシピ名に
Carrot Soupを含むすべてのレシピをリストします。この検索では大文字と小文字が区別されるため、carrot soupと指定した場合には頂点は見つからないことに注意してください。eq()メソッドを、指定される名前とともに使用します。g.V().hasLabel('recipe').has('name', eq('Carrot Soup')).values('name')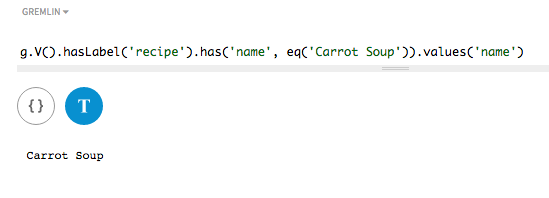
リストされている作者のフルネームに対して一致が見つかっています。
neq()は指定された文字列に一致しないすべての文字列を検索するためにも使用できます。 -
探索クエリーでは、トークン以外の検索を使用して、レシピ名に
Carrotを含むすべてのレシピをリストします。eq()メソッドを、指定される名前とともに使用します。g.V().hasLabel('recipe').has('name', eq('Carrot')).valueMap()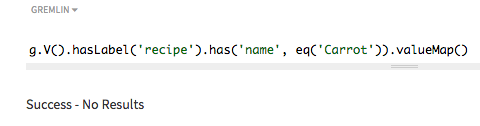
部分名のみが指定されたため、一致は見つかりません。
asString()のインデックスでは、文字列が一致する必要があります。
-
探索クエリーでは、トークン以外の検索を使用して、
Rの文字で始まる名前を持つすべての作者を検索します。prefix()メソッドを、指定される文字列とともに使用します。g.V().hasLabel('recipe').has('name', prefix('R')).values('name')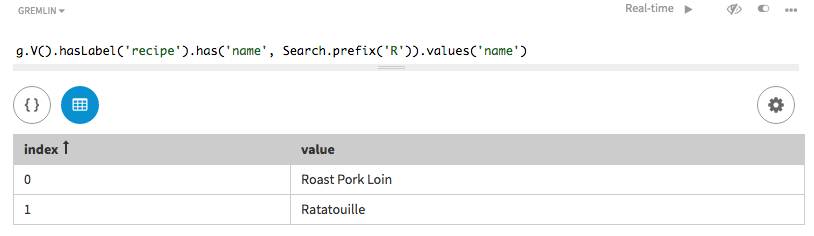
Rで始まる各作者名に対して一致が見つかっています。ただし、検索インデックス内でasString()を使用してレシピ名が指定されている必要があります。
-
探索クエリーでは、トークン以外の検索を使用して、指定された正規表現を含む名前を持つすべてのレシピを検索します。
regex()メソッドを、指定されるregexとともに使用します。g.V().hasLabel('recipe').has('name', regex('.*ee.*')).values('name')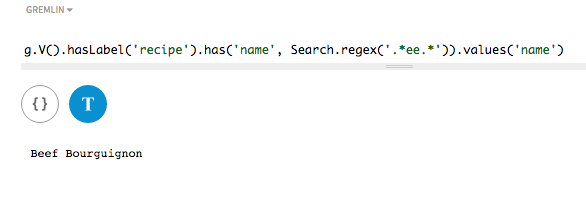
任意の数の任意の文字に挟まれたeeを含むすべての文字列を検索するために、
.*ee.*regexを含む各作者名の一致が見つかります。ただし、レシピ名が検索インデックス内でasString()を使用して指定されている必要があります。
-
phrase()述語が、TextFieldsとして指定されているプロパティとともに使用されます。レシピ名に含まれているWild Mushroom Stroganoffと完全に一致する語句を検索します。g.V().hasLabel('recipe').has('name', phrase('Wild Mushroom Stroganoff',0))0は、結果が完全に一致する語句でなければならないことを示します。
正しいレシピの頂点が返されます。v[{~label=recipe, community_id=2123369856, member_id=0}] -
phrase()述語は近接検索に使用して、トークン化されたテキスト内で特定の距離内にある単語を含む語句を検出できます。g.V().hasLabel('recipe').has('name', phrase('Wild Stroganoff',1))1の値は、互いに1つの単語を隔てた単語のみをレシピ名に含む結果のみを検索する必要があることを示します。この例でのバリエーションは、Mushroomの単語の追加です。
正しいレシピの頂点が返されます。v[{~label=recipe, community_id=2123369856, member_id=0}]g.V().hasLabel('recipe').has('name', phrase('Wild Mushroom',1))の一致によっても正しい頂点が返されますが、g.V().hasLabel('recipe').has('name', phrase('Mushroom Wild',1))では正しい頂点は返されません。
-
fuzzy()述語では、最適な文字列アライメント距離の計算を使用して、StrFieldsとして指定されているプロパティを照合します。スペルミスなど、単語内で使用されている文字のバリエーションに対してこの述語の焦点が当てられます。指定されている編集距離は、文字の置き換えの数を意味します。1回の文字の置き換えが、1回の編集に数えられます。James Beardに完全に一致する作者名を検索します。g.V().hasLabel('author').has('name', fuzzy('James Beard', 0)).values('name')0は、結果が完全に一致しなければならないことを示します。James Beard -
fuzzy()述語の最後の値を変更すると、スペルミスが見つかります。g.V().hasLabel('author').has('name', fuzzy('James Beard', 1)).values('name')1は、最高で1つの編集距離を持つ結果が一致に含められることを示します。
Jmaes Beardというスペルミスを含む作者の頂点が存在する場合、ここに示すクエリーでは両方の頂点が検出されます。1の値は、文字aおよびmの単一の置き換えにより、このスペルミスを検出します。James Beard, Jmaes Beard -
スペルミスの検索では、正しいスペルのほか、スペルミスのある名前も検索されることに注意してください。
g.V().hasLabel('author').has('name', fuzzy('Jmase Beard', 2)).values('name')2は、最高で2回の置き換えが行われる結果が一致に含められることを示します。
Jmaes Beardというスペルミスを含む作者の頂点が存在する場合、ここに示すクエリーでは両方の頂点が検出されます。2の値は、Jmaes Beard内のeとsの文字の単一の置き換えがなされるスペルミスと、Jmase BeardからJames Beardへの2番目の文字の置き換えが行われた正しいスペルの名前の両方が現出されます。James Beard, Jmaes Beard注意: 3以上の編集距離を指定すると、一致する単語が多すぎて役に立つ結果が得られません。結果の検索インデックスは大きすぎて、効果的にクエリーをフィルター処理できません。
-
tokenFuzzy()述語はfuzzy()と似ていますが、分析されたテキスト形式データ(TextFields)内の個々のトークン全体のバリエーションを検索します。Wildの単語を含むレシピ名を検索します。1文字のスペルミスを含む単語も検索されます。g.V().hasLabel('recipe').has('name', tokenFuzzy('Wlid',1)).values('name')1は、1文字のスペルミス(1回の置き換え)が許容されることを示します。Wild Beef Stroganoff
-
頂点ラベル
authorに対し、「インデックスの作成」での検索インデックス例のような2番目の検索インデックスを作成します。schema.vertexLabel('author').index('search').search(). by('name').asString(). by('nickname').ifNotExists().add()この検索インデックスではDSE Searchを使用して、トークン化を使用したフルテキストとしての
nicknameのインデックスと、文字列としてのnameのインデックスを作成します。 -
この探索クエリーは、作者の検索インデックスとレシピの検索インデックスを使用してクエリーを実行できる中間探索
V()を示しています。最初のインデックスではtokenRegex()を使用して、Braiseの単語で始まるレシピの手順を検索します。このクエリーの一部には、後でクエリーで使用するために、rのラベルが付けられています。次に、Jの文字で始まる作者名に対して作者の検索インデックスが検索され、外向きエッジを通じて頂点に探索されます。頂点では、クエリーの最初の部分がwhere(eq('r'))により検出されます。g.V().has('recipe', 'instructions', tokenRegex('Braise.*')).as('r'). V().has('author', 'name', prefix('J')).out().where(eq('r')).values('name')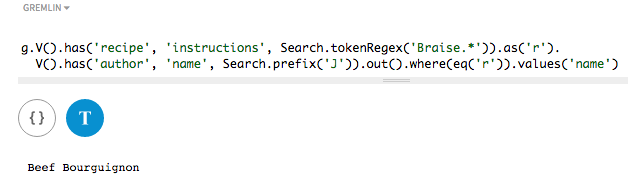
このクエリー探索では、
Julia Childの作者によるBeef Bourguignonのレシピが検索され、検索インデックスで使用できる複雑な用途が示されています。
-
地理空間検索は、地理空間関係を検出するために使用されます。このような検索を可能にするために、検索インデックスが使用されます。まず、検索インデックスを作成する必要があります。
schema.vertexLabel('FridgeSensor').index('search').search(). by('location').ifNotExists().add() -
サンプル・データを使用すると、検索結果について理解しやすくなります。冷蔵庫のセンサーに対して2つの頂点を入力します。
graph.addVertex(label, 'FridgeSensor', 'name', 'jones1', 'city_id', 100, 'sensor_id', '60bcae02-f6e5-11e5-9ce9-5e5517507c66', 'location', Geo.point(-118.359770, 34.171221)) graph.addVertex(label, 'FridgeSensor', 'name', 'smith1', 'city_id', 100, 'sensor_id', '61deada0-3bb2-4d6d-a606-a44d963f03b5', 'location', Geo.point(-115.655068, 35.163427))センサーには名前が付けられ、
Pointのデータ型の場所とともに、都市IDとセンサーIDが付けられます。 -
クエリーでは、記述された
Distanceポリゴン内の要件を満たすすべてのセンサーを検索できます。このポリゴンは、中心が(-110, 30)の円で、20度の半径を持つものとしてGeo.inside()メソッドで指定されます。Distance d = Geo.point(-110,30),20, Geo.Unit.DEGREES) g.V().hasLabel('FridgeSensor').has('location', Geo.inside(d)).values('name')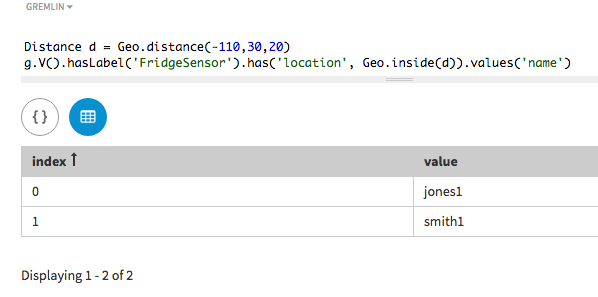
-
検索インデックスは、テキスト形式以外の値に対しても使用できます。
この例は、整数のプロパティageによる検索インデックスを含んでいます。クエリーを実行するデータは以下のとおりです。schema.propertyKey('name').Text().create() schema.propertyKey('age').Int().create() schema.vertexLabel('person').properties('name','age').create() schema.vertexLabel('person').index('search').search().by('name').by('age').add()
クエリー自体は以下のとおりです。graph.addVertex(label, 'person','name','Julia','age',56) graph.addVertex(label, 'person','name','Emeril','age',48) graph.addVertex(label, 'person','name','Simone','age',50) graph.addVertex(label, 'person','name','James','age',52)
50歳を超えるすべての人を検索します。g.V().has('person','age', gt(50)).values()==>Julia ==>56 ==>James ==>52 -
上記の検索をソートするには、さらにメソッドを追加します。
g.V().hasLabel("person").has("age", gt(50)).order().by("age", incr).values()以下を取得します。==>James ==>52 ==>Julia ==>56