単純な探索
単純な探索は複雑にもなり得ますが、再帰や分岐などの特殊な技術を使用しません。
レシピ・トイ・グラフに戻り、グラフを拡大してレビュー担当者や評価を含めましょう。次のスクリプトを読み込んで、
reviewer頂点とrecipe-reviewerエッジを追加します。以前にgenerateRecipe.groovyスクリプトを実行しており、このスクリプトの読み込み前にレシピの頂点が存在している必要があります。// Generates review vertices and edges for Recipe Toy Graph
// :load /tmp/generateReviews.groovy
// reviewer vertices
johnDoe = graph.addVertex(label, 'reviewer', 'name','John Doe')
johnSmith = graph.addVertex(label, 'reviewer', 'name', 'John Smith')
janeDoe = graph.addVertex(label, 'reviewer', 'name','Jane Doe')
sharonSmith = graph.addVertex(label, 'reviewer', 'name','Sharon Smith')
betsyJones = graph.addVertex(label, 'reviewer', 'name','Betsy Jones')
beefBourguignon = g.V().has('recipe', 'name','Beef Bourguignon').tryNext().orElseGet {graph.addVertex(label, 'recipe', 'name', 'Beef Bourguignon')}
spicyMeatLoaf = g.V().has('recipe', 'name','Spicy Meatloaf').tryNext().orElseGet {graph.addVertex(label, 'recipe', 'name', 'Spicy Meatloaf')}
carrotSoup = g.V().has('recipe', 'name','Carrot Soup').tryNext().orElseGet {graph.addVertex(label, 'recipe', 'name', 'Carrot Soup')}
// reviewer - recipe edges
johnDoe.addEdge('rated', beefBourguignon, 'timestamp', '2014-01-01T05:15:00.00Z', 'stars', 5, 'comment', 'Pretty tasty!')
johnSmith.addEdge('rated', beefBourguignon, 'timestamp', '2014-01-23T00:00:00.00Z', 'stars', 4)
janeDoe.addEdge('rated', beefBourguignon, 'timestamp', '2014-02-01T00:00:00.00Z', 'stars', 5, 'comment', 'Yummy!')
sharonSmith.addEdge('rated', beefBourguignon, 'timestamp', '2015-01-01T00:00:00.00Z', 'stars', 3, 'comment', 'It was okay.')
johnDoe.addEdge('rated', spicyMeatLoaf, 'timestamp', '2015-12-31T10:56:00.00Z', 'stars', 4, 'comment', 'Really spicy - be careful!')
sharonSmith.addEdge('rated', spicyMeatLoaf, 'timestamp', '2014-07-23T00:30:00.00Z', 'stars', 3, 'comment', 'Too spicy for me. Use less garlic.')
janeDoe.addEdge('rated', carrotSoup, 'timestamp', '2015-12-30T01:20:00.00Z', 'stars', 5, 'comment', 'Loved this soup! Yummy vegetarian!')
gremlin> :load /tmp/generateReviews.groovy以前入力したレシピのクエリーを実行し、結果をレシピ変数に割り当てます。次に変数を使用して、reviewer-recipeエッジを作成します。これらのクエリーではtryNext()とorElseGet()という2つのApache Tinkerpopメソッドを利用します。詳細については、「Apache Tinkerpop Java API」を参照してください。
レシピの評価の確認
reviewerラベルを含む頂点の数をカウントして、頂点が作成されているかどうかを確認します。gremlin> g.V().hasLabel('reviewer').count()
==>5valuesを使用してすべてのレビュー担当者をリストします。// Get the names of all the reviewers
gremlin> g.V().hasLabel('reviewer').values('name')
==>John Smith
==>Sharon Smith
==>Betsy Jones
==>Jane Doe
==>John Doeレビュー担当者が作成されていることを確認することは有効ですが、クエリーに回答する探索を作成することの方が重要です。たとえば、John Doeはレシピについてどのようなことを述べているでしょうか。
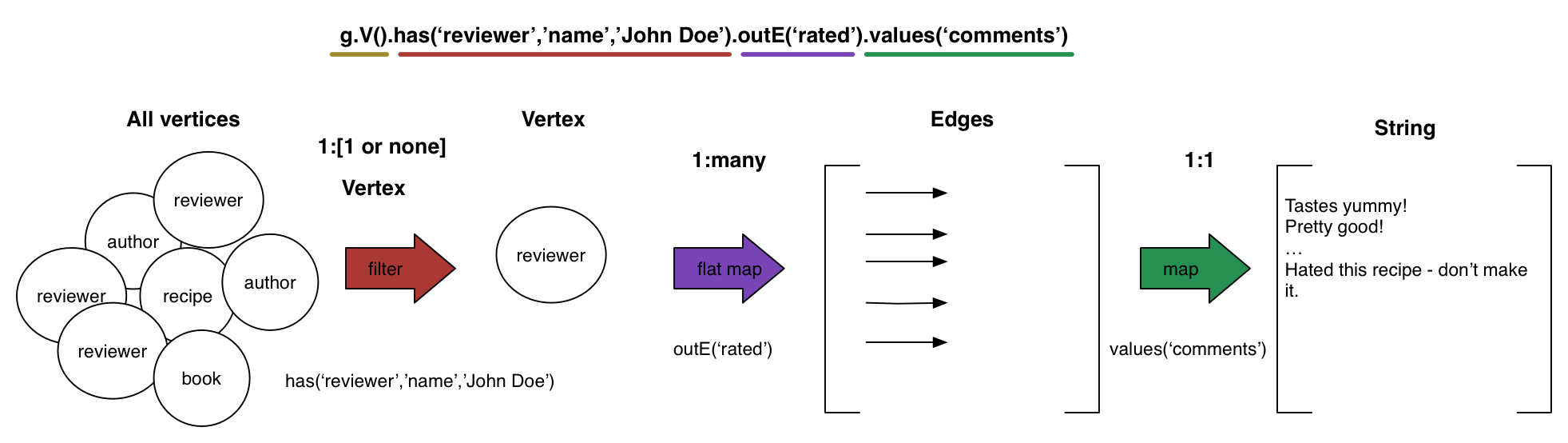
John Doeのname値を持つ頂点ラベルをreviewerとして識別するクエリーを使用します。
g.V().has('reviewer', 'name','John Doe').outE('rated').values('comment')outE('rated')を使用して、John Doeが評価したレシピをすべて検索すると、commentsプロパティの値を取得できます。==>Pretty tasty!
==>Really spicy - be careful!John Doeが評価したレシピがわかると便利なため、別の探索を使用できます。
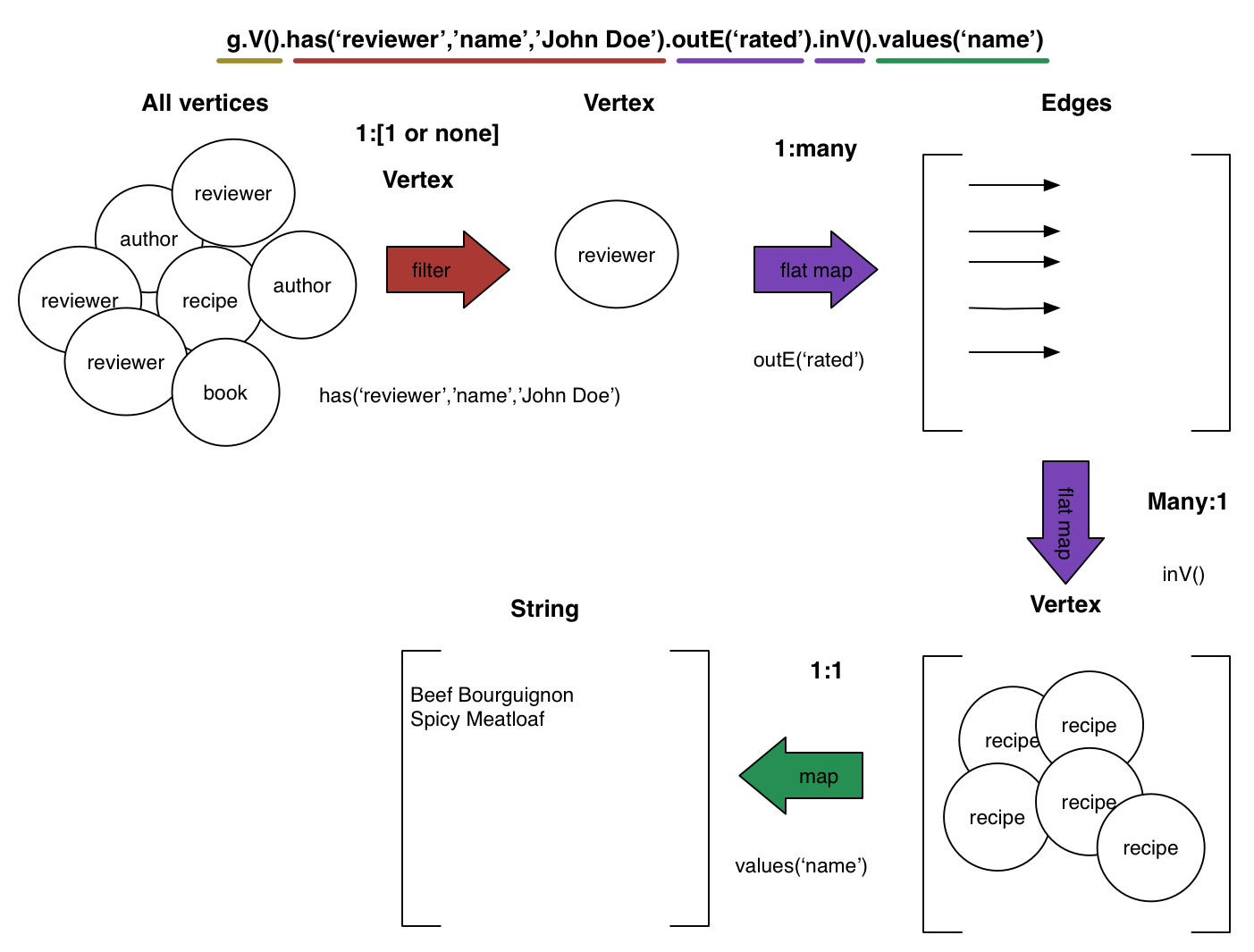
g.V().has('reviewer', 'name','John Doe').outE('rated').inV().values('name')==>Beef Bourguignon
==>Spicy Meatloaf3つを超える星が付けられたレシピのレビューをすべて見つけることは、妥当な疑問です。
gt(3)、つまりgreater than 3を使用した探索を使用して、stars値を絞り込みます。gremlin> g.E().hasLabel('rated').has('stars', gt(3)).valueMap()
==>[stars:4, timestamp:2014-01-23T00:00:00Z]
==>[comment:Loved this soup! Yummy vegetarian!, stars:5, timestamp:2015-12-30T00:00:00Z]
==>[comment:Yummy!, stars:5, timestamp:2014-02-01T00:00:00Z]
==>[comment:Pretty tasty!, stars:5, timestamp:2014-01-01T00:00:00Z]
==>[comment:Really spicy - be careful!, stars:4, timestamp:2015-12-31T00:00:00Z]ratedのラベルが付けられている各エッジを検索し、star評価が4または5のエッジのみを出力するようにエッジを絞り込みます。ただし、この探索では最初の疑問への回答は出力されません。探索を変更して、inV()を使用して入力頂点を取得し、values('name')を使用して名前別にそれらの入力頂点をリストする必要があります。gremlin> g.E().hasLabel('rated').has('stars', gt(3)).inV().values('name')
==>Beef Bourguignon
==>Spicy Meatloaf
==>Beef Bourguignon
==>Carrot Soup
==>Beef BourguignonBeef Bourguignonが3回評価されていることを示しています。ただし、リスト内のレシピのタイトルが重複しているだけで、レビュー担当者の情報は把握していません。前回のクエリーに戻り、さらに最近のレビューを見てみましょう。さらに探索ステップを追加して、
timestampで絞り込むと、レビュー日が2015年1月1日以降で星が4および5の評価をgte(4)、つまりgreater than or equal to 4を使用して検索できます。
gremlin> g.E().hasLabel('rated').has('stars',gte(4)).has('timestamp', gte(Instant.parse('2015-01-01T00:00:00.00Z'))).valueMap()
==>[comment:Loved this soup! Yummy vegetarian!, timestamp:2015-12-30T00:00:00Z, stars:5]
==>[comment:Really spicy - be careful!, timestamp:2015-12-31T00:00:00Z, stars:4]inV().values('name')を前回のクエリーに追加した場合は、2015年の始め以降の星が4~5個のレビューを検索するように結果が調整されます。統計関数を使用して評価を操作すると、興味深い回答が得られます。たとえば、すべてのレシピ評価の平均値はいくつでしょうか。
gremlin> g.E().hasLabel('rated').values('stars').mean()
==>4.142857142857143より多くのレビューを書いているレビュー担当者は、さらに広範なレビューを書いているかもしれません。1人のレビュー担当者が書いたレビューの最大数を検索します。
gremlin> g.V().hasLabel('reviewer').map(outE('rated').count()).max()
==>2outE('rated')を使用して外向きエッジをすべてマップしてカウントし、max()を使用して最高値のカウントを判断します。調査可能なもう1つの計測値は各レビュー担当者の平均評価です。この探索クエリーでは、いくつかのApache TinkerPop探索ステップを使用します。
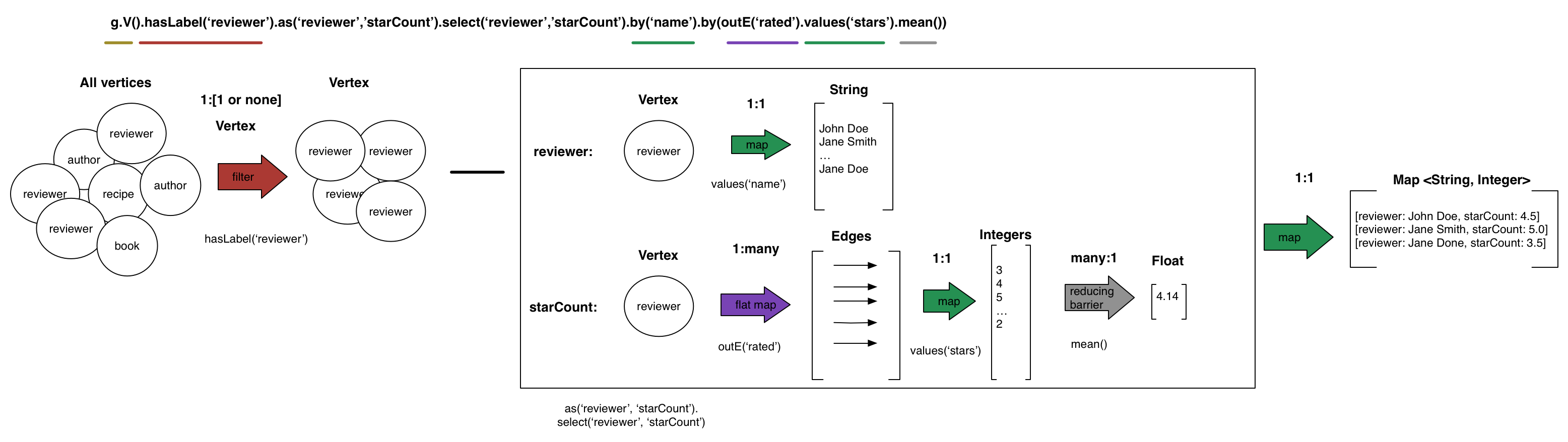
as()ステップでは、レビュー担当者ごとに、リストとなる2つの項目である、レビュー担当者の名前とstarsの平均値に対する表示ラベルを表示できます。これらの表示ラベル、reviewerおよびstarCountは次に、それぞれの値を取得するselect()ステップで使用されます。まず、by('name')を使用してレビュー担当者の名前を取得し、by(outE('rated').values('stars').mean()を使用してstarCountを取得します。select()ステップは、各reviewer頂点を確認してから、関連付けられているstarCount値を探索によって検出します。gremlin> g.V().hasLabel('reviewer').as('reviewer','starCount').
select('reviewer','starCount').
by('name').
by(outE('rated').values('stars').mean())
==>[reviewer:Jane Doe, starCount:5.0]
==>[reviewer:Betsy Jones, starCount:NaN]
==>[reviewer:John Doe, starCount:4.5]
==>[reviewer:John Smith, starCount:4.0]
==>[reviewer:Sharon Smith, starCount:3.0]starCountにはNaN(メンバーではない)が示されています。この結果は、Jane Doeは少なくとも1つのレシピを非常に気に入っていますが、Sharon Smithは気に入らなかったことを明確に示しています。結果を
starCount、つまり星の平均評価で並べ替えると、最高の評価者と最低の評価者を発見できます。ここでは、探索ステップorder().by(select('starCount').decr()はselect('starCount')ステップの出力を使用して、表示を降順に並べ替えています。gremlin> g.V().hasLabel('reviewer').as('reviewer','starCount').
select('reviewer','starCount').
by('name').
by(outE('rated').values('stars').mean()).
order().by(select('starCount'), decr)
==>[reviewer:Betsy Jones, starCount:NaN]
==>[reviewer:Jane Doe, starCount:5.0]
==>[reviewer:John Doe, starCount:4.5]
==>[reviewer:John Smith, starCount:4.0]
==>[reviewer:Sharon Smith, starCount:3.0]limit(1)を探索に追加すると、Betsyがリストに含まれていない場合の、より高い評価者であるJane Doeを取得できます。NaNを0値に変更するために、巧妙な探索ステップ
coalesce()が使用されています。gremlin> g.V().hasLabel('reviewer').as('reviewer','starCount').
select('reviewer','starCount').
by('name').
by(coalesce(outE('rated').values('stars'),constant(0)).mean()).
order().by(select('starCount'), decr)
==>[reviewer:Jane Doe, starCount:5.0]
==>[reviewer:John Doe, starCount:4.5]
==>[reviewer:John Smith, starCount:4.0]
==>[reviewer:Sharon Smith, starCount:3.0]
==>[reviewer:Betsy Jones, starCount:0.0]starCountは真の値である0.0になったことに注目してください。各レビュー担当者がレシピに付けた星の評価を確認します。
g.V().hasLabel('reviewer').as('reviewer','rating').out().as('recipe').
select('reviewer','rating','recipe').
by('name').
by(outE('rated').values('stars')).
by(values('name'))as('reviewer','rating')を使用してreviewer頂点からレビュー担当者と評価にラベルが付けられた後、ステップ・モジュレータas('recipe')を使用してレシピ名が探索され、名付けられていることに注目してください。出力リストの最初の2つの項目がreviewer頂点から取得され始め、3番目の項目は隣接するrecipe頂点から取得されます。==>{reviewer=John Doe, rating=5, recipe=Beef Bourguignon}
==>{reviewer=John Doe, rating=5, recipe=Spicy Meatloaf}
==>{reviewer=John Smith, rating=4, recipe=Beef Bourguignon}
==>{reviewer=Jane Doe, rating=5, recipe=Beef Bourguignon}
==>{reviewer=Jane Doe, rating=5, recipe=Carrot Soup}
==>{reviewer=Sharon Smith, rating=3, recipe=Beef Bourguignon}
==>{reviewer=Sharon Smith, rating=3, recipe=Spicy Meatloaf}一般的に、レビューにおける最も興味深い統計は、特定のレシピを何人の人が評価し、その特定のレシピの平均評価は何であるかに関する質問への回答です。今回のグラフ探索はrecipe頂点から始まり、レシピ名を取得し、
inE('rated').count()を使用して内向きエッジをカウントすることでレビューの数を取得し、inE('rated').values('stars').mean()を使用して内向きエッジの平均値を取得します。以前に示したcoalesce()ステップを使用すると、meanRatingのすべてのNaN値をゼロに変更できます。g.V().hasLabel('recipe').as('recipe','numberOfReviews','meanRating').
select('recipe','numberOfReviews','meanRating').
by('name').
by(inE('rated').count()).
by(inE('rated').values('stars').mean())==>{recipe=Beef Bourguignon, numberOfReviews=4, meanRating=4.25}
==>{recipe=Wild Mushroom Stroganoff, numberOfReviews=0, meanRating=NaN}
==>{recipe=Spicy Meatloaf, numberOfReviews=2, meanRating=3.5}
==>{recipe=Rataouille, numberOfReviews=0, meanRating=NaN}
==>{recipe=Salade Nicoise, numberOfReviews=0, meanRating=NaN}
==>{recipe=Roast Pork Loin, numberOfReviews=0, meanRating=NaN}
==>{recipe=Oysters Rockefeller, numberOfReviews=0, meanRating=NaN}
==>{recipe=Carrot Soup, numberOfReviews=1, meanRating=5.0}レシピの検索
レシピの一般的なクエリーに、特定の材料を含むレシピの検索があります。
g.V().hasLabel('recipe').out().has('name','beef').in().hasLabel('recipe').values('name')==>Beef Bourguignong.V().hasLabel('recipe').out().has('name',within('beef','carrots')).in().hasLabel('recipe').values('name')==>Beef Bourguignon ==>Carrot Soup
特定のレシピのすべての材料の検索は、一般的なクエリーです。
g.V().match(
__.as('a').hasLabel('ingredient'),
__.as('a').in('includes').has('name','Beef Bourguignon')).
select('a').by('name')match()ステップを使用して、牛肉の赤ワイン煮を作るために使用する材料に一致するものを検索します。探索は、すべての頂点をフィルター処理して材料を検索することから始まり、次にin('includes')を使用してincludesのエッジに沿ってレシピの頂点を探索します。またこのクエリーではGroovyダブル・アンダースコア変数を一致メソッドのプライベート変数として使用します。結果:==>tomato paste
==>beef
==>onion
==>mashed garlic
==>butterinside()は地理空間検索に最も一般的に使用されますが、このメソッドを使用して、特定の値の範囲に収まる任意の項目を検索できます。一例として、1960~1970年の間に発行された本の検索があります。g.V().has('book', 'year', inside(1960,1970)).valueMap()==>{ISBN=[0-394-40135-2], year=[1968], name=[The French Chef Cookbook]}
==>{year=[1961], name=[The Art of French Cooking, Vol. 1]}出力のグループ化
group()探索ステップを使用して、グラフ探索からの出力をグループ化します。たとえば、すべての頂点をラベルによってグループ化された名前順に表示します。g.V().group().by(label).by('name')==>[meal:[JuliaDinner, Saturday Feast, EverydayDinner], ingredient:[olive oil, chicken broth,
eggplant, pork sausage, green bell pepper, yellow onion, celery, hard-boiled egg, shallots,
zucchini, butter, green beans, mashed garlic, onion, mushrooms, bacon, parsley, oyster,
tomato, thyme, pork loin, tuna, tomato paste, ground beef, red wine, fennel, Pernod,
chervil, egg noodles, carrots, beef], author:[Louisette Bertholie, Kelsie Kerr,
Alice Waters, Julia Child, Emeril Lagasse, Simone Beck, Patricia Curtan, Patricia Simon,
James Beard, Fritz Streiff], book:[Simca's Cuisine: 100 Classic French Recipes for Every
Occasion, The French Chef Cookbook, The Art of Simple Food: Notes, Lessons, and Recipes
from a Delicious Revolution, The Art of French Cooking, Vol. 1], recipe:[Wild Mushroom
Stroganoff, Roast Pork Loin, Spicy Meatloaf, Rataouille, Beef Bourguignon, Oysters
Rockefeller, Salade Nicoise, Carrot Soup], reviewer:[Sharon Smith, John Smith, Jane Doe,
Betsy Jones, John Doe]]もう1つの例には、年ごとにすべての本をグループ化し、本が発行された年と本のタイトルのリストを表示する場合があります。
g.V().hasLabel('book').group().by('year').by('name')==>{1968=[The French Chef Cookbook, The French Chef Cookbook],
1972=[Simca's Cuisine: 100 Classic French Recipes for Every Occasion, Simca's Cuisine: 100
Classic French Recipes for Every Occasion], 2007=[The Art of Simple Food: Notes, Lessons,
and Recipes from a Delicious Revolution, The Art of Simple Food: Notes, Lessons, and Recipes
from a Delicious Revolution], 1961=[The Art of French Cooking, Vol. 1, The Art of French
Cooking, Vol. 1]}local()を使用した処理のグループ化
グラフ探索内の特定のステップに対してローカルで処理を行うことが重要なことがよくあります。次の2つの例では
limit()コマンドを使用して、local()がクエリーを入力するストリーム全体からクエリーの一部に処理を変更する方法を示します。まず、2人の作者と、これらの作者が本を出版した年を検索します。g.V().hasLabel('author').as('author').out().properties('year').as('year').
select('author','year').
by('name').
by().
limit(2)==>{author=Julia Child, year=vp[year->1961]}
==>{author=Julia Child, year=vp[year->1968]}local()を使用してこのクエリーを変更し、グラフ内の各作者が出版した最初の2冊の本を検索します。g.V().hasLabel('author').as('author').
local(out().properties('year').as('year').limit(2)).
select('author','year').
by('name').
by()==>{author=Julia Child, year=vp[year->1961]}
==>{author=Julia Child, year=vp[year->1968]}
==>{author=Simone Beck, year=vp[year->1961]}
==>{author=Simone Beck, year=vp[year->1972]}
==>{author=Louisette Bertholie, year=vp[year->1961]}
==>{author=Patricia Simon, year=vp[year->1972]}
==>{author=Alice Waters, year=vp[year->2007]}
==>{author=Patricia Curtan, year=vp[year->2007]}
==>{author=Kelsie Kerr, year=vp[year->2007]}
==>{author=Fritz Streiff, year=vp[year->2007]}local()にはグラフ探索内のグラフのサブセクションを処理し、さらに処理を続行する前に結果を返すためのアプリケーションが多く存在します。