データ・モデリングの概念の詳細
データ・モデリングの概念の詳細。
グラフ・データ・モデルは、複雑な関係をカバーするように拡張できます。サブグラフを考慮すれば、グラフ全体をよりよくダイジェストすることができます。レシピ・データ・モデルは、新しいデータ層を含むように変更することができます。
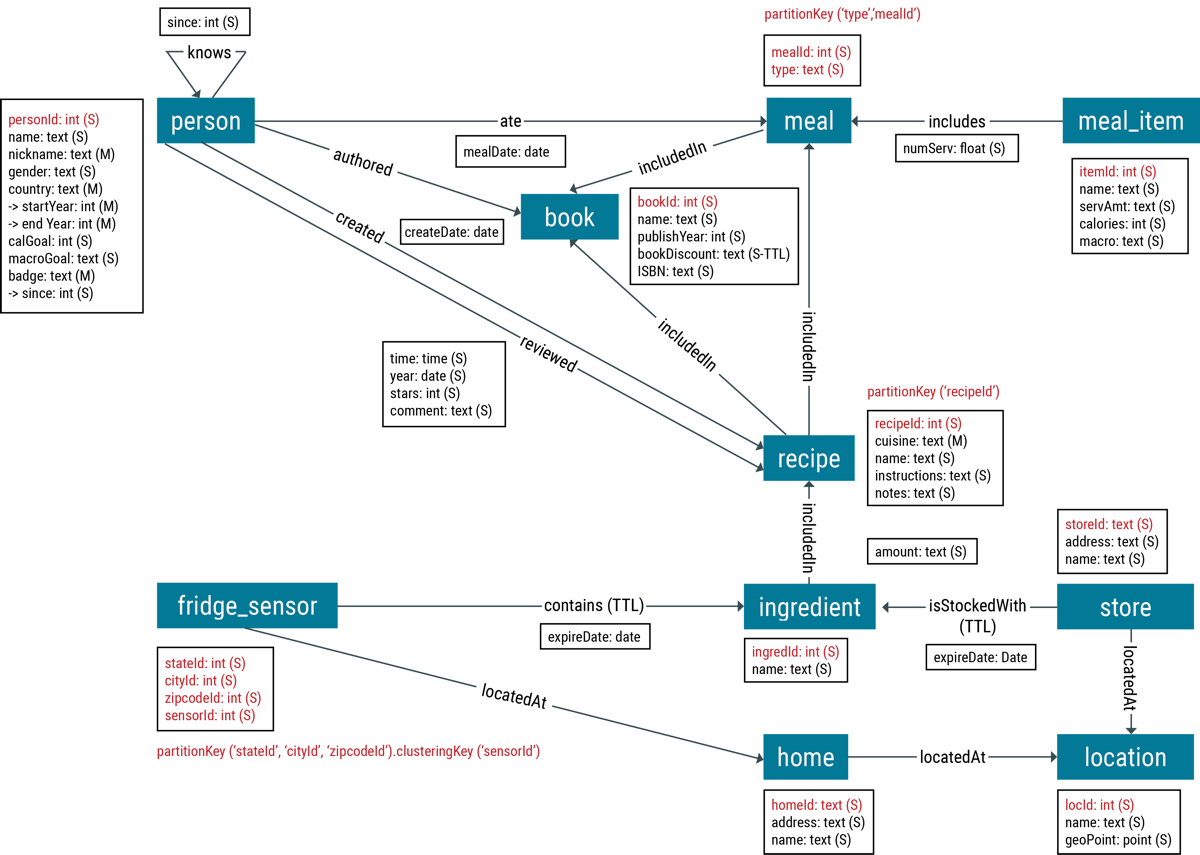
- category
- 野菜、果物、パスタ、肉
- nutritional value
- ビタミン、タンパク質、炭水化物、脂肪の割合(%)
- calories
- kcalの数値

食材のプロパティ値を選択することは簡単に思えるかもしれませんが、考慮すべき点がたくさんあります。たとえば、categoryを見てみましょう。食材の記述に使用されるカテゴリーの数に応じて、頂点ラベルまたはcategoryのプロパティを作成した方が利点があります。頂点はグラフ探索の開始点にはなりますが、頂点のプロパティにはなりません。「どの食材が乳製品ですか?」と質問するには、乳製品に分類されたすべての食材を見つけるために、dairy頂点での開始点には、食材につき1つのエッジ・ホップが必要です。
ただし、食材に乳製品が多すぎる場合、スーパー・ノードや、非常に多くのエッジが付いたホットスポットのノードによって、乳製品の食材を探しているクエリーの処理が遅くなる可能性があります。プロパティのインデックス作成を使用すると、食材カテゴリーを頂点ラベルではなくプロパティとしてより良くモデリングできます。
栄養素は、ビタミンC、ビタミンD、カルシウム、ナトリウムなどの一定数の項目です。nutrientの頂点ラベルを作成し、食材と栄養素との間のエッジにパーセンテージで重み付けをすると、グラフに別の次元が追加されます。

1つの食材だけの結果になる関係を見てみましょう。

そして、数千の食材はもちろんのこと、わずか100個の食材で作成されたグラフを想像してみてください。栄養素の頂点ラベルと栄養素の頂点プロパティのどちらを作成した方が良いか調べてみましょう。

食材のプロパティを使って構築されたアプリケーションの可能性を考えてみてください。冷蔵庫の中を見て、マッシュルームと牛肉があることがわかったら、ビーフ・ストロガノフなどの調理レシピを検索するためにグラフ・データベースにクエリーします。冷蔵庫の食品にタグが付いていれば、冷蔵庫に保存されている材料を指定して、今晩の夕食は何がいいか教えてくれます。