SELECT
Retrieve data from a Cassandra table.
Retrieve data from a Cassandra table.
Synopsis
SELECT select_expression FROM keyspace_name.table_name WHERE relation AND relation ... ORDER BY ( clustering_column ( ASC | DESC )...) LIMIT n ALLOW FILTERING
select expression is:
selection_list | COUNT ( * | 1 )
selection_list is:
selector, selector, ... | ( COUNT ( * | 1 ) )
selector is:
column name | ( WRITETIME (column_name) ) | ( TTL (column_name) ) | (function (selector , selector, ...) )
function is a timeuuid function, a token function, or a blob conversion function.
relation is:
primary_key op term | primary_key IN ( term, ( term ... ) ) | TOKEN (parition_key, ...) op ( term )
op is = | < | > | <= | > | =
A semicolon that terminates CQL statements is not included in the synopsis. |
Description
A SELECT statement reads one or more records from a Cassandra table. The input to the SELECT statement is the select expression. The output of the select statement depends on the select expression:
| Select Expression | Output |
|---|---|
| Column of list of columns | Rows having a key value and collection of columns |
| COUNT aggregate function | One row with a column that has the value of the number of rows in the resultset |
| WRITETIME function | The date/time that a write to a column occurred |
| TTL function | The remaining time-to-live for a column |
Specifying columns
The SELECT expression determines which columns, if any, appear in the result. Using the asterisk specifies selection of all columns:
SELECT * from users;
Counting returned rows
A SELECT expression using COUNT(*) returns the number of rows that matched the query. Alternatively, you can use COUNT(1) to get the same result.
Count the number of rows in the users table:
SELECT COUNT(*) FROM users;
Specifying rows returned using LIMIT
Using the LIMIT option, you can specify that the query limit the number of rows returned.
SELECT COUNT(*) FROM big_table LIMIT 50000; SELECT COUNT(*) FROM big_table LIMIT 200000;
The output of these statements if you had 105,291 rows in the database would be: 50000 and 105291
Specifying the table using FROM
The FROM clause specifies the table to query. Optionally, specify a keyspace for the table followed by a period, (.), then the table name. If a keyspace is not specified, the current keyspace is used.
For example, count the number of rows in the Migrations table in the system keyspace:
SELECT COUNT(*) FROM system.Migrations;
Filtering data using WHERE
The WHERE clause specifies which rows to query. The WHERE clause is composed of conditions on the columns that are part of the primary key or are indexed. Use of the primary key in the WHERE clause tells Cassandra to race to the specific node that has the data. Using the equals conditional operators (= or IN) is unrestricted. The term on the left of the operator must be the name of the column, and the term on the right must be the column value to filter on. There are restrictions on other conditional operators.
Cassandra supports these conditional operators: =, >, >=, <, or <=, but not all in certain situations.
- A filter based on a non-equals condition on a partition key is supported only if the partitioner is an ordered one.
- WHERE clauses can include a greater-than and less-than comparisons, but for a given partition key, the conditions on the clustering column are restricted to the filters that allow Cassandra to select a contiguous ordering of rows.
For example:
CREATE TABLE ruling_stewards ( steward_name text, king text, reign_start int, event text, PRIMARY KEY (steward_name, king, reign_start) );
This query constructs a filter that selects data about stewards whose reign started by 2450 and ended before 2500. If king were not a component of the primary key, you would need to create an index on king to use this query:
SELECT * FROM ruling_stewards WHERE king = 'Brego' AND reign_start >= 2450 AND reign_start < 2500 ALLOW FILTERING;
The output is:
steward_name | king | reign_start | event
--------------+-------+-------------+--------------------
Boromir | Brego | 2477 | Attacks continue
Cirion | Brego | 2489 | Defeat of Balchoth
To allow Cassandra to select a contiguous ordering of rows, you need to include the king component of the primary key in the filter using an equality condition. The ALLOW FILTERING clause is also required.
Using the IN filter condition
Use IN, an equals condition operator, in the WHERE clause to specify multiple possible values for a column. For example, select two columns, Name and Occupation, from three rows having employee ids (primary key) 199, 200, or 207:
SELECT Name, Occupation FROM People WHERE empID IN (199, 200, 207);
Format values for the IN conditional test as a comma-separated list. The list can consist of a range of column values.
When not to use IN
The recommendations about when not to use an index apply to using IN in the WHERE clause. Under most conditions, using IN in the WHERE clause is not recommended. Using IN can degrade performance because usually many nodes must be queried. For example, in a single, local data center cluster with 30 nodes, a replication factor of 3, and a consistency level of LOCAL_QUORUM, a single key query goes out to two nodes, but if the query uses the IN condition, the number of nodes being queried are most likely even higher, up to 20 nodes depending on where the keys fall in the token range.
ALLOW FILTERING clause
When you attempt a potentially expensive query, such as searching a range of rows, this prompt appears:
Bad Request: Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING.
To run the query, use the ALLOW FILTERING clause. Imposing a limit using the LIMIT n clause is recommended to reduce memory used. For example:
SELECT * FROM ruling_stewards WHERE king = 'none' AND reign_start >= 1500 AND reign_start < 3000 LIMIT 10 ALLOW FILTERING;
Critically, LIMIT doesn't protect you from the worst liabilities. For instance, what if there are no entries with no king? Then you have to scan the entire list no matter what LIMIT is.
ALLOW FILTERING will probably become less strict as we collect more statistics on our data. For example, if we knew that 90% of entries have no king we would know that finding 10 such entries should be relatively inexpensive.
Paging through unordered results
The TOKEN function can be used with a condition operator on the partition key column to query. The query selects rows based on the token of their partition key rather than on their value. The token of a key depends on the partitioner in use. The RandomPartitioner and Murmur3Partitioner do not yield a meaningful order.
For example, assuming you have this table defined, the following query shows how to use the TOKEN function:
CREATE TABLE periods (
period_name text,
event_name text,
event_date timestamp,
weak_race text,
strong_race text,
PRIMARY KEY (period_name, event_name, event_date)
);
SELECT * FROM periods
WHERE TOKEN(period_name) > TOKEN('Third Age')
AND TOKEN(period_name) < TOKEN('Fourth Age');
Querying compound primary keys and sorting results
ORDER BY clauses can select a single column only. That column has to be the second column in a compound PRIMARY KEY. This also applies to tables with more than two column components in the primary key. Ordering can be done in ascending or descending order, default ascending, and specified with the ASC or DESC keywords.
For example, set up the playlists table, which uses a compound primary key, insert the example data, and use this query to get information about a particular playlist, ordered by song_order. As of Cassandra 1.2, you do not need to include the ORDER BY column in the select expression.
SELECT * FROM playlists WHERE id = 62c36092-82a1-3a00-93d1-46196ee77204 ORDER BY song_order DESC LIMIT 50;
Output is:
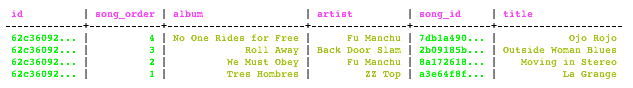
Or, create an index on playlist artists, and use this query to get titles of Fu Manchu songs on the playlist:
CREATE INDEX ON playlists(artist) SELECT title FROM playlists WHERE artist = 'Fu Manchu';
Output is:
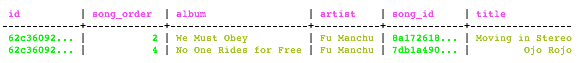
Querying a collection set, list, or map
When you query a table containing a collection, Cassandra retrieves the collection in its entirety.
To return the set of email belonging to frodo, for example:
SELECT user_id, emails FROM users WHERE user_id = 'frodo';
Retrieving the date/time a write occurred
Using WRITETIME followed by the name of a column in parentheses returns date/time in microseconds that the column was written to the database.
Retrieve the date/time that a write occurred to the first_name column of the user whose last name is Jones:
SELECT WRITETIME (first_name) FROM users WHERE last_name = 'Jones';
writetime(first_name) ----------------------- 1353010594789000
The writetime output in microseconds converts to November 15, 2012 at 12:16:34 GMT-8