Compound keys and clustering
A compound primary key includes the partition key, which determines which node stores the data, and includes one or more additional columns for determining per-partition clustering.
A compound primary key includes the partition key, which determines on which node data is stored, and one or more additional columns that determine clustering. Cassandra uses the first column name in the primary key definition as the partition key. For example, in the playlists table, id is the partition key. The remaining column, or columns that are not partition keys in the primary key definition are the clustering columns. In the case of the playlists table, the song_order is the clustering column. The data for each partition is clustered by the remaining column or columns of the primary key definition. On a physical node, when rows for a partition key are stored in order based on the clustering columns, retrieval of rows is very efficient. For example, because the id in the playlists table is the partition key, all the songs for a playlist are clustered in the order of the remaining song_order column.
Insertion, update, and deletion operations on rows sharing the same partition key for a table are performed atomically and in isolation. See About transactions and concurrency control.
You can query a single sequential set of data on disk to get the songs for a playlist.
SELECT * FROM playlists WHERE id = 62c36092-82a1-3a00-93d1-46196ee77204 ORDER BY song_order DESC LIMIT 50;
The output looks something like this:
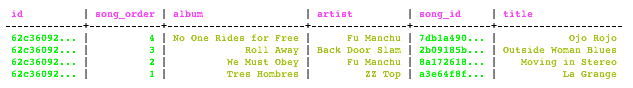
Cassandra stores data on a node by partition key. If you have too much data in a partition and want to spread the data over multiple nodes, use a composite partition key.