How is data maintained?
Cassandra processes data at several stages on the write path. Compaction to maintain healthy SSTables is the last step in the write path process.
Cassandra maintains data on disk by consolidating SSTables. SSTables are immutable and accumulate on disk and must periodically be merged using compaction.
Compaction
Periodic compaction is essential to a healthy Cassandra database because Cassandra does not insert/update in place. As inserts/updates occur, instead of overwriting the rows, Cassandra writes a new timestamped version of the inserted or updated data in another SSTable. Cassandra also does not delete in place because SSTables are immutable. Instead, Cassandra marks data to be deleted using a tombstone. Tombstones exist for a configured time period defined by the gc_grace_seconds value set on the table.
Over time, many versions of a row might exist in different SSTables. Each version has a different set of columns stored. As SSTables accumulate, more and more SSTables must be read in order to retrieve an entire row of data.
Compaction merges the data in each SSTable by partition key, selecting the latest data for storage based on its timestamp. Because rows are sorted by partition key within each SSTable, the merge process does not use random I/O and is performant. After evicting tombstones and removing deleted data, columns, and rows, the compaction process consolidates SSTables into a new single SSTable file. The old SSTable files are deleted as soon as any pending reads finish using the files.
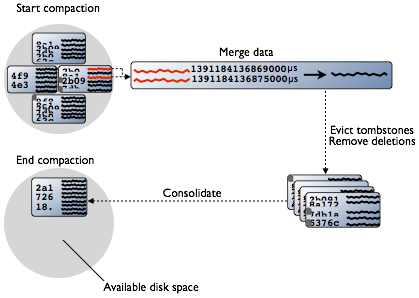
During compaction, there is a temporary spike in disk space usage and disk I/O because the old and new SSTables co-exist. Disk space occupied by old SSTables becomes available for reuse when the new SSTable is ready. Cassandra 2.1 and later improves read performance after compaction because of incremental replacement of compacted SSTables. Instead of waiting for the entire compaction to finish and then throwing away the old SSTable, Cassandra can read data directly from the new SSTable even before it finishes writing.
As data is written to the new SSTable and reads are directed to it, the corresponding data in the old SSTables is no longer accessed and is evicted from the page cache. Thus begins an incremental process of caching the new SSTable, while directing reads away from the old one, thus avoiding the dramatic cache miss. Cassandra provides predictable high performance even under heavy load.
Types of compaction
Different compaction strategies have strengths and weaknesses. Understanding how each type works is vital to making the right choice for your application workload. SizeTieredCompactionStrategy (STCS) is recommended for write-intensive workloads. LeveledCompactionStrategy (LCS) is recommended for read-intensive workloads. DateTieredCompactionStrategy (DTCS) is recommended for time series data and expiring TTL data.
- SizeTieredCompactionStrategy (STCS)
-
Recommended for write-intensive workloads.
Pros: Compacts write-intensive workload very well.
Cons: Might hold onto stale data too long. Amount of memory needed increases over time.
The SizeTieredCompactionStrategy (STCS) initiates compaction when a set number (default is 4) of similar-sized SSTables have accumulated. Compaction merges the SSTables to create one larger SSTable. As larger SSTables accumulate, the same process occurs, merging the larger SSTables into an even larger SSTable. At any given time, several SSTables of varying sizes are present. While this strategy works quite well to compact a write-intensive workload, when reads are needed, several SSTables still must be retrieved to find all the data for a row. There is no guarantee that a row's data will be restricted to a small number of SSTables. Also, predicting the eviction of deleted data is uneven, because SSTable size is the trigger for compaction, and SSTables might not grow quickly enough to merge and evict old data. As the largest SSTables grow in size, the amount of memory needed for compaction to hold both the new and old SSTables simultaneously can outstrip a typical amount of RAM on a node.
- LeveledCompactionStrategy (LCS)
-
Recommended for read-intensive workloads.
Pros: Memory requirements are simple to predict. Read operations more predictable in latency. Stale data is evicted more frequently.
Cons: Much higher I/O utilization that can impact operation latency.
The LeveledCompactionStrategy (LCS) is intended to alleviate some of the read operation issues with the SizeTieredCompactionStrategy (STCS). As SSTables reach a certain small fixed size (default is 5MB), they are written into the first level, L0, and also merged into the first level, L1. In each level starting with L1, all SSTables are guaranteed to have non-overlapping data. Because no data is overlapping, the LeveledCompactionStrategy sometimes splits SSTables as well as merging them, to keep the files similarly sized. Each level is 10X the size of the last level, so level L1 has 10X as many SSTables as L0, and level L2 has 100X. Level L2 will start filling when L1 has been filled. Because a level contains no overlapping data, a read can be accomplished quite efficiently with very few SSTables retrieved. For many read operations, only one or two SSTables will be read. In fact, 90% of all reads will be satisfied from reading one SSTable. The worst case is one SSTable per level must be read. Less memory will be required for compacting using this strategy, with 10X the fixed size of the SSTable required. Obsolete data will be evicted more often, so deleted data will occupy a much smaller portion of the SSTables on disk. However, the compaction operations for the LeveledCompactionStrategy (LCS) take place more often and place more I/O burden on the node. For write-intensive workloads, the payoff using this strategy is generally not worth the performance loss to I/O operations. In Cassandra 2.2 and later, performance improvements have been implemented that bypass compaction operations when bootstrapping a new node using LCS into a cluster. The original data is directly moved to the correct level because there is no existing data, so no partition overlap per level is present. For more information, see Apache Cassandra 2.2 - Bootstrapping Performance Improvements for Leveled Compaction.
- DateTieredCompactionStrategy (DTCS)
-
Recommended for time series and expiring TTL workloads.
Pros: Specifically designed for time series data.
Cons: Out of order data injections can cause errors. Read repair must be turned off for DTCS.
The DateTieredCompactionStrategy (DTCS) acts similarly to STCS, but instead of compacting based on SSTable size, DTCS compacts based on SSTable age. Making the time window configurable ensures that new and old data will not be mixed in merged SSTables. In fact, using Time-To-Live (TTL) timestamps, DateTieredCompactionStrategy (DTCS) often ejects whole SSTables for old data that has expired. This strategy often results in similar-sized SSTables, too, if time series data is ingested at a steady rate. SSTables are merged when a certain minimum threshold of number of SSTables is reached within a configurable time interval. SSTables will still be merged into larger tables, like in size tiered compaction, if the required number of SSTables falls within the time interval. However, SSTables are not compacted after reaching a configurable age, reducing the number of times data will be rewritten. SSTables compacted using this strategy can be read, especially for queries that ask for the "last hour's worth of data", very efficiently. One issue that can cause difficulty with this strategy is out-of-order writing, where a timestamped record is written for a past timestamp, for example. Read repairs can inject an out-of-order timestamping, so turn off read repairs when using the DateTieredCompactionStrategy. For more information about compaction strategies, see When to Use Leveled Compaction and Leveled Compaction in Apache Cassandra. For DateTieredCompactionStrategy, see DateTieredCompactionStrategy: Notes from the Field, Date-Tiered Compaction in Cassandra or DateTieredCompactionStrategy: Compaction for Time Series Data.
Starting compaction
- SizeTieredCompactionStrategy
For write-intensive workloads
- LeveledCompactionStrategy
For read-intensive workloads
- DateTieredCompactionStrategy
For time series data and expiring (TTL) data
You can manually start compaction using the nodetool compact command.