Running a DSE configuration job using LCM
Run a configuration job that pushes DSE configuration profile updates at the cluster, datacenter, or node level in Lifecycle Manager.
Lifecycle Manager runs jobs concurrently for different clusters; however, jobs for the same cluster execute sequentially and remain in the pending state while other jobs are currently running.
The job does not progress to the next node until the
current node successfully restarts (that is, the node is responding on the
native_transport_port). By default, the job stops prematurely
if a job fails for a single node, to avoid propagating a faulty configuration to an
entire cluster. Jobs that are already running on nodes are allowed to finish, but
the job does not continue running on any remaining nodes for that job. Doing so
prevents any potential configuration problems from bringing down multiple nodes, or
even the entire cluster. If required, override this default behavior with the
Continue on error option, which attempts to continue
running the job on all nodes regardless of failure.
Prerequisites
- Create all SSH credentials and define repositories.
- Define configuration profiles.
- Build the cluster topology model or import an existing model.
- Check the clock drift rule in the Best Practice Service to ensure clocks are in sync before proceeding. Clock drift can interfere with LCM generating TLS certificates.
- Run an installation job for the initial
installation of DSE. Note: If importing a cluster topology into LCM, run an install job after the import. A configuration job fails if an install job has not preceded the configuration job.
Procedure
- Click Clusters in the Lifecycle Manager navigation menu.
- Select the cluster, datacenter, or node to run a configuration for.
-
Click the ellipsis icon and select Configure.
The Run Configuration Job dialog displays.
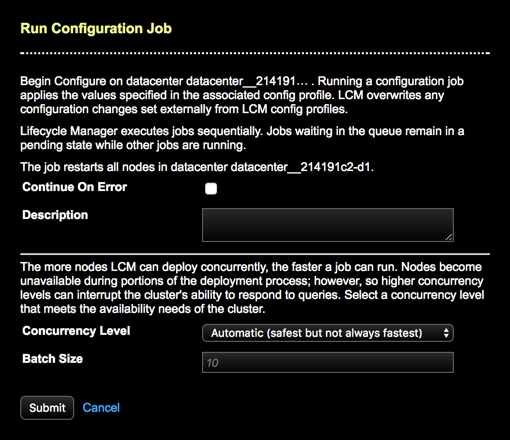
-
To override the default error behavior and continue running the job on
subsequent nodes until all nodes are finished, select Continue On
Error. The job continues running despite encountering
errors.
By default, a job ceases running on additional nodes upon encountering an error on any given node. Any nodes that are already running continue to completion.
- Optional: Enter a description about the job.
-
If running a configuration job on a cluster or datacenter, select a
Concurrency Level:
Note: Concurrency Level is not applicable to node-level jobs.
- Automatic (safest but not always fastest): Default.
Allows LCM to determine a safe concurrency level to use. Use this option when
unsure which other option would be appropriate.Note: The Automatic option executes one job at a time, both for nodes in datacenters that were previously installed by LCM, and for nodes in new datacenters where an install job has not yet successfully completed. This behavior mirrors the Single node option.
- Single node: Executes job on one node at a time. Use this option when having more than one node offline at a given time would impact availability.
- One node per DC: Executes job concurrently on at most one node per datacenter (DC). Use this option if having a single node in each DC offline does not impact availability.
- Single rack within a DC (might interrupt service): Executes job concurrently on nodes such that at most one rack has nodes down at a time. Use this option if having an entire rack within a DC offline does not impact availability.
- One rack per DC (might interrupt service): Executes job concurrently on nodes such that at most one rack in each DC has nodes down at a time. Use this option if having an entire rack in each DC offline does not impact availability.
- All nodes within a DC (interrupts service): Executes job concurrently on all nodes in a DC. Use this option if having all nodes in a DC offline is acceptable.
- All nodes (interrupts service): Executes a job concurrently on all nodes in a cluster. Use this option if having all nodes in a cluster offline is acceptable.
- Automatic (safest but not always fastest): Default.
Allows LCM to determine a safe concurrency level to use. Use this option when
unsure which other option would be appropriate.
-
If running a configuration job on a cluster or datacenter, enter a
Batch Size if the default (10) is not appropriate for
your environment.
Increase the Batch Size value if:
- The datacenter is large.
- The selected Concurrency Level makes many nodes eligible to run concurrently (such as the All nodes within a DC option).
- The default Batch Size results in job run times that are too long.
- Your environment can handle a larger number of nodes performing downloads and installs simultaneously without impacting network bandwidth or the LCM server.
Note: Batch size takes effect only when a large number of nodes are eligible for concurrent deployment, such as with the All nodes concurrency policy. Batch size has no effect on jobs with the Single node concurrency policy or on node-level jobs. - Click Submit to submit the job. A dialog indicates that the job is in the queue to run.
- Click View Job Summary to navigate to the Jobs page to monitor the job progress. Click Close if you do not want to immediately monitor the job and prefer to remain in the Clusters workspace.