Cloning cluster data from a defined other location
Clone cluster data from one DSE cluster to another using the Restore Backup feature in OpsCenter. The data is cloned from a supported, available location.
Clone cluster data from one DSE cluster to another using the Restore Backup feature in OpsCenter. This workflow does not require the source and target clusters to both be managed by the same OpsCenter instance, and does not necessarily require another existing cluster instance. The data can be cloned, provided that it was backed up to a supported, available location.
This procedure steps you through the basic required selections in each of the three restore dialogs presented during the workflow.
- Ensure the source and target datacenter names and topology are identical. See Managing datacenter topologies and Cloning cluster data.
- Ensure the encryption keys are identical when cloning encrypted tables to a different cluster.
Prerequisites
- Restoring a snapshot that contains only the system keyspace is not allowed. There must be both system and non-system keyspaces, or only non-system keyspaces in the snapshot you want to restore.
- Restoring a snapshot that does not contain a table definition is not allowed.
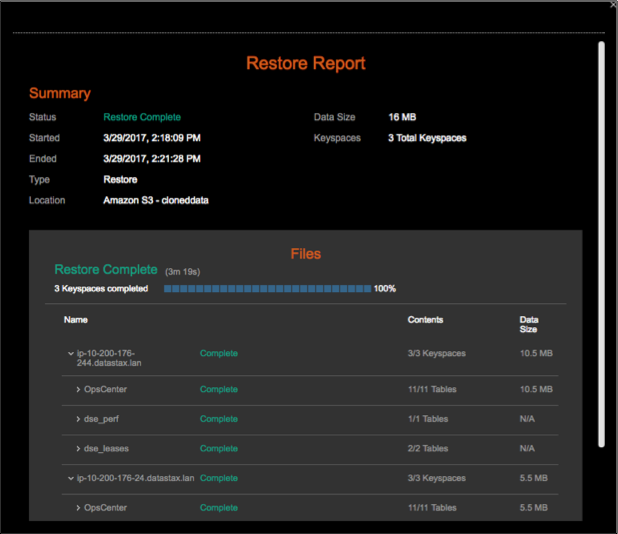
- Restoring a snapshot to a location with insufficient disk space fails. The Restore Report indicates which nodes do not have sufficient space and how much space is necessary for a successful restore. For more information and tips for preventative measures, see Monitoring sufficient disk space for restoring backups.
- OpsCenter does not back up indexes. Therefore, DSE must recompute the indexes after a restore.
Procedure
- Click .
- Click the Details link for the Backup Service.
- In the Activity tab, click Restore Backup.
-
Click the Other Location tab.
The Step 1 of 3: Select Backup Restore from Backup dialog appears.
- Select the Location to restore from. Available options are:
-
Enter the location of the S3 bucket so that OpsCenter can locate it.
Option Description Amazon S3 Enter the Region where the S3 bucket is located. If blank, OpsCenter will try to query S3 for the bucket region or use the
remote_backup_regionas a default.Note: Some regions, such as China (Beijing), require a region to be specified and cannot be queried.S3 Compatible Enter a URL that points to an S3 Endpoint. For example, mys3endpoint:9000. -
Enter the S3 Bucket name.
Note: The bucket name must be at least 4 characters long. Bucket names must only contain lowercase letters, numbers, and hyphens. Additionally, OpsCenter requires that bucket prefixes contain only lowercase letters, numbers, and safe characters. See the S3 guidelines for more details about bucket naming restrictions.Tip: To indicate a bucket subfolder location, delineate the bucket name from the folder name with a forward slash (/) character. Example: mybucket/myfolder/mysubfolder. Remember that slashes are not allowed within bucket or folder names themselves.
-
Select the source type of your AWS credentials.
Warning: The AWS credentials and bucket names are stored in cluster_name.conf (with the exception of ad hoc backups). Be sure to use proper security precautions to ensure that this file is not readable by unauthorized users.
Option Description User-Supplied Credentials Enter your AWS Key and AWS Secret. AWS Credential Provider chain Use the default credential provider chain to locate AWS credentials. See Working with AWS Credentials on the AWS website.
- Select Microsoft Azure as the backup Location.
- Enter the Storage Account name that OpsCenter backs up to.
- Enter the Container Name, which is the name of the Azure Blob where OpsCenter saves backup data.
- Enter a Storage Key for the storage container, which is an access key for the storage account that houses the Blob storage container.
- Enter the Path to the backups.
-
Click Next.
The Step 2 of 3: Select Backup Version dialog appears populated with the available backups at the selected location. For more, see Adding an Amazon S3 backup location.
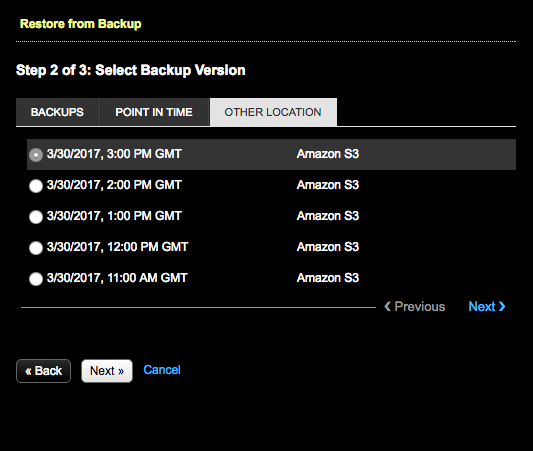
-
Select the backup to restore and click Next.
The Step 3 of 3: Configure and Restore dialog appears.

-
In Keyspaces and Graphs, select the tables or graphs you
want to restore.
- Click All Keyspaces or All Graphs to restore all keyspaces or all graphs.
- Click the keyspace name or graph name to include all tables or all graphs in the keyspace.
- To select specific tables or graphs, expand the keyspace name or graph name and select the specific tables or graphs to back up.
Note: For DSE 6.0.0-6.0.4, when restoring a DSE Graph backup without selecting Use sstableloader, DSE must be restarted to ensure all data is available. - In the Location list, select the cluster to clone the data to.
- When cloning data, it is not necessary to select the Truncate/delete existing data before restore option because it is a not operational for a cloning workflow. The truncate option purges data on a target before a restore runs. When using the restore feature to clone, the truncate option does not do anything because there is no data to purge before the restore runs.
-
To prevent overloading the network, set a maximum
transfer rate for the restore using the Throttle DSE stream
throughput at ____ MB option.
Note: To enter a value for this option, you must select Use sstableloader. Otherwise, the transfer rate value is ignored.
- Optional:
If necessary, change the staging directory by setting the
backup_staging_directoryconfiguration option in address.yaml. -
Click Restore Backup.
The Confirm Restore dialog appears.
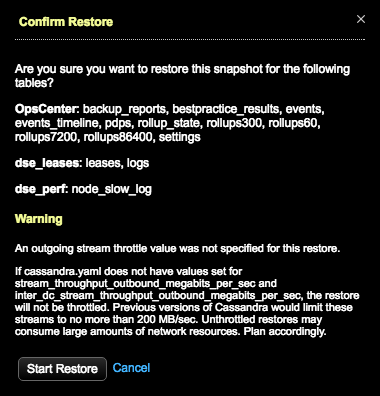 Warning: If a value was not set for throttling stream output, a warning message indicates the consequences of unthrottled restores. Take one of the following actions:
Warning: If a value was not set for throttling stream output, a warning message indicates the consequences of unthrottled restores. Take one of the following actions:- Click Cancel and set the throttle value in the Restore from Backup dialog.
- Set the
stream_throughput_outbound_megabits_per_secandinter_dc_stream_throughput_outbound_megabits_per_secvalues in cassandra.yaml. - Proceed anyway at the risk of creating network bottlenecks.
Tip: If using LCM to manage DSE cluster configuration, update Cluster Communication settings in cassandra.yaml in the configuration profile for the cluster and run a configuration job. Stream throughput (not inter-dc) is set to 200 in LCM defaults.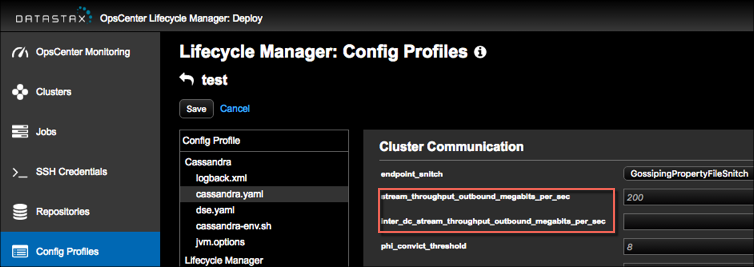
-
Review the information to determine if adjustments or corrections to the
current schema are required :
- To correct schema issues, click Cancel, rectify the issues, and try the restore again.
- To proceed despite the schema mismatch, click Continue
Restore.Warning: Attempting to restore a backup with an incompatible schema might result in corrupt or inaccessible data. Before forcing the restore, back up your current data.
Results