CREATE SEARCH INDEX
既存のテーブルに対して新しい検索インデックスを定義します。
cassandra.yaml
cassandra.yamlファイルの場所は、インストールのタイプによって異なります。| パッケージ・インストール | /etc/dse/cassandra/cassandra.yaml |
| tarボール・インストール | installation_location/resources/cassandra/conf/cassandra.yaml |
既存のテーブルに対して新しい検索インデックスを定義します。検索インデックス・スキーマと構成を自動的に作成してから、インデックスを生成します。
制約事項: DSE Searchノードでのみ使用できるコマンドです。大きなデータセットに対して検索インデックスの管理コマンドを実行すると、CQLSHのデフォルトで指定された10分のタイムアウトよりも長くかかることがあります。必要に応じて、CQLSHクライアント・タイムアウトの値を引き上げてください。
重要: このコマンドは、現在のデータ・センターでのみ実行されるため、整合性レベルがQUORUMで実行されます。
構文
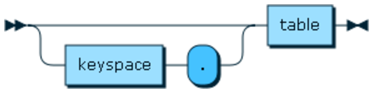
CREATE SEARCH INDEX [ IF NOT EXISTS ] ON [keyspace_name.]table_name
[ WITH [ COLUMNS column_list { option : value } [ , ... ] ]
[ [ AND ] PROFILES profile_name [ , ... ] ]
[ [ AND ] CONFIG { option:value } [ , ... ] ]
[ [ AND ] OPTIONS { option:value } [ , ... ] ] ] ;
CREATE SEARCH INDEX文にオプションが指定されていない場合、すべてのカラムでデフォルト値を使用してインデックスが作成されます。
| 構文規則 | 説明 |
|---|---|
| 大文字 | リテラル・キーワード。 |
| 小文字 | リテラル以外。 |
イタリック体 |
変数値。ユーザー定義値と置き換えます。 |
[] |
任意。角かっこ( [] )で任意指定のコマンド引数を囲みます。角かっこは入力しないでください。 |
( ) |
グループ。丸かっこ(( ))は、選択肢を含むグループを示します。丸かっこは入力しないでください。 |
| |
または。縦棒( | )で代替要素を区切ります。要素のいずれかを入力してください。縦棒は入力しないでください。 |
... |
繰り返し可能。省略記号(...)は、構文要素を必要な回数だけ繰り返すことができることを示します。 |
'Literal string' |
単一引用符( ' )でCQL文内のリテラル文字を囲みます。大文字を維持するには、単一引用符を使用します。 |
{ key : value } |
マップ・コレクション。中かっこ( { } )でマップ・コレクションまたはキーと値のペアを囲みます。コロンでキーと値を区切ります。 |
<datatype1,datatype2> |
セット、リスト、マップ、またはタプル。山かっこ(< >)で、セット、リスト、マップまたはタプル内のデータ型を囲みます。データ型はコンマで区切ります。 |
cql_statement; |
CQL文の終了。セミコロン( ; )ですべてのCQL文を終了します。 |
[--] |
コマンドライン・オプションとコマンド引数は、2つのハイフン(--)。この構文は、引数がコマンドライン・オプションと間違われる可能性がある場合に役立ちます。 |
' <schema> ... </schema> ' |
検索CQLのみ:単一引用符( ' )でXMLスキーマ宣言全体を囲みます。 |
@xml_entity='xml_entity_type' |
検索CQLのみ:スキーマ・ファイルおよびsolrConfigファイル内のXML要素を上書きするための実体とリテラル値を示します。 |
EBNF
EBNF構文:
createSearchIndex ::= 'CREATE' 'SEARCH' 'INDEX' ('IF' 'NOT' 'EXISTS')?
'ON' tableName
('WITH' indexOptions)?
tableName ::= (keyspace '.')? table
indexOptions ::= indexOption ('AND' indexOption)*
indexOption ::= 'COLUMNS' columnList
| 'PROFILES' profileName (',' profileName)*
| 'CONFIG' optionMap
| 'OPTIONS' optionMap
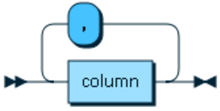
columnList ::= column (',' column)*
column ::= (columnName | '*')('{' optionMap '}')?
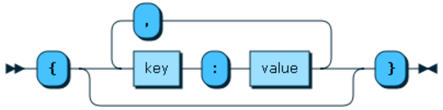
optionMap ::= '{' (optionName ':' optionValue (',' optionName ':'
optionValue)*)? '}'レールロード・ダイアグラム:




COLUMNS
インデックスに含めるフィールドの定義、インデックス型の設定、ファセット検索用の非トークン化フィールドの作成を行います。
COLUMNS column_list { copyField : true | false },
column_list { docValues : true | false },
column_list { excluded : true | false },
column_list { indexed : true | false }注: COLUMNSオプションが使用されている場合、インデックスを作成する必要があるPRIMARY KEYカラムを除き、リストされていないカラムはデフォルトでインデックスから除外されます。
- column_list
- コンマ区切りリストまたは*(すべてのカラム)。タプル・フィールドとサブフィールドを含めることができます。インデックスを作成する必要があるPRIMARY KEYカラムを除き、リストされていないカラムはデフォルトでインデックスから除外されます。
- 検索インデックスに含めるすべてのcolumn_name、tuplefield、またはtuplefield.subfieldのコンマ区切りリスト。サブフィールドが包含対象として選択されている場合は、親フィールドが常に含まれます。
- column_listのカラムごとに、copyField、docValues、excluded、またはindexedについてtrueまたはfalseを指定します。
- すべてのカラムを選択するには、アスタリスク(*)を指定します。
COLUMNS column_name1, column_name2
COLUMNS column_name1, column_name2 {copyField:true} - copyField: (true | false)
StrField型の指定したカラムからコピーして新しいフィールドを作成するには、trueに設定します。元のフィールドのデータを新しいフィールドに複製します。検索とファセット化の両方で必要なカラムに使用します。デフォルト値はfalseです。
- docValues: (true | false)
- 指定したカラムごとにフォワード・インデックスを作成します。TrieField、UUIDField、およびStrFieldを拡張するSolr型でのみ有効な設定です。ソートまたはグループ化(ファセット化)されたカラムで使用します。デフォルト値は、TrieField型とUUIDField型ではtrue、StrField型ではfalseです。
SOLR-7264により、Solrスキーマのブーリアン・フィールドでdocValuesをtrueに設定することはできません。ブーリアンdocValuesの回避策として、TrieIntFieldで0および1を使用します。
注: spaceSavingsプロファイルを使用すると、DocValuesの自動生成が無効になります。 - excluded: (true | false)
- COLUMNSオプションを使用する場合、インデックスからカラムを除外します。
- true - リストされたカラムとカラム内のすべてのフィールドがインデックスから除外されます。
- false - リストされたカラムはインデックスから除外されません。インデックスにカラムを含めるには、含めるカラムを指定する必要があります。指定されない場合のデフォルトです。
- indexed: (true | false)
- COLUMNSオプションを使用する場合、以下のように設定します。
- true - 指定されたフィールドがインデックスに含まれます。指定されない場合のデフォルトです。
- false - 指定されたフィールドがインデックスから除外されます。
PROFILES
領域節約オプションを適用し、最初の作成時のインデックス・サイズを最小化します。spaceSavingAll、または適用するプロファイルのコンマ区切りリストを指定します。
PROFILES profile_name [, profile_name, ...]
注: プロファイルは最初のインデックス生成にのみ適用されます。ALTER SEARCH INDEX SCHEMAコマンドには適用されません。
- spaceSavingAll
- すべてのプロファイルを適用します。
- spaceSavingNoJoin
- 検索クエリーでテーブル全体の結合に必要な非表示のパーティション・キーをインデックスから除外します。使用する場合、検索インデックス・クエリーでテーブル結合を使用できません。
- spaceSavingSlowTriePrecision
- トライ・フィールドprecisionStepを「0」に設定すると、領域を大幅に節約できますがクエリーの速度は低下します。
CONFIG
構成オプションは検索インデックス構成ファイル内の値をオーバーライドします。CONFIGオプション・マップでオプションを渡すには、次の構文を使用します。
CONFIG { shortcut_name:value [, shortcut_name:value, ...] }- shortcuts
-
構成要素の値へのショートカット。SETを使用します。
autoCommitTime:デフォルト値は10,000です。defaultQueryField:フィールドの名前です。デフォルトは設定されていません。注: SETを使用して追加します。削除するには、DROPを使用します。directoryFactory:directoryFactoryClassオプションの代わりに使用できます。オプションは以下のとおりです。- 'standard'
- 'encrypted'
filterCacheLowWaterMark:デフォルトは1024です。filterCacheHighWaterMark:デフォルトは2048です。directoryFactoryClass:ディレクトリー係数の完全修飾名を指定します。標準および暗号化ディレクトリー係数以外のディレクトリー係数に対して、directoryFactoryオプションの代わりに使用します。mergeMaxThreadCount:mergeMaxMergeCountとともに構成する必要があります。デフォルト値は、tpc_coresの数値です(この数値はcassandra.yamlで構成されています)。mergeMaxMergeCount:mergeMaxThreadCountを使用して構成する必要があります。デフォルト値はmax(max(<maxThreadCount * 2>, <num_tokens * 8>), <maxThreadCount + 5>)
です。ここで、num_tokensは、仮想ノード(vnode)を割り当てるトークン範囲の数値です(この数値はcassandra.yamlで構成されています)。ramBufferSize:デフォルトは512です。realtime:デフォルトはfalseです。
OPTIONS
要求オプションで要求全体を構成します。OPTIONSマップでオプションを渡すには、次の構文を使用します。
OPTIONS { option:value [, option:value, ...] }要求オプションはブーリアン値です。 - recovery
-
- true - インデックスが破損していて検索コアで読み込むことができない場合、インデックスを削除し、再作成して復元します。deleteAllフラグは、deleteAllが具体的に設定されていない限り、復元フラグに基づいて設定されます。
- false - 復元されません。デフォルト。
- reindex
-
- true - データのインデックスを再作成します。新しいインデックスの作成中に現在のインデックスを保持します(読み取りを受け入れる)。デフォルト。
- false - データのインデックスは再作成されません。
- lenient
-
- true - スキーマ生成中にサポートされていないカラム型が検出された場合は、フィールドを自動的に無視します。
- false - スキーマ生成中にサポートされていないカラム型が検出された場合は、エラーが増加します。
注: このオプションは、インデックスが自動的に作成されるようになったため、SpatialRecursivePrefixTreeFieldTypeフィールドでは不要です。
例
wiki.solrキースペースとテーブル、および指定したオプションで検索インデックスを作成します。
検索インデックスが存在しない場合は作成する
CREATE SEARCH INDEX IF NOT EXISTS ON wiki.solr WITH COLUMNS id, body {excluded : false};リアルタイム(RT)検索インデックスを作成するが、データのインデックスは再作成しない
CREATE SEARCH INDEX ON wiki.solr WITH CONFIG { realtime:true } AND OPTIONS { reindex : false };透過的なデータ暗号化(TDE)を使用して検索インデックスを作成する
CREATE SEARCH INDEX IF NOT EXISTS ON wiki.solr WITH COLUMNS c1,c2 {docValues:true} AND PROFILES spaceSavingAll AND CONFIG {directoryFactory:'encrypted'};サポートされている型のすべてのカラムに対して設定されているdocValuesで検索インデックスを作成する
CREATE SEARCH INDEX ON wiki.solr WITH COLUMNS * { docValues:true };検索インデックスを作成し、インデックスに含めるカラムとインデックスから除外するカラムを指定する
CREATE SEARCH INDEX ON wiki.solr WITH COLUMNS field1 { indexed:true }, field2 { indexed:false };インデックスが作成されていないカラムは、HTTPクエリー結果とシングルパス・クエリー結果に含まれています。除外するには、excludedオプションを使用します。
タプルおよびUDTフィールドの制御を使用して検索インデックスを作成する
CREATE SEARCH INDEX ON wiki.solr WITH COLUMNS tuplefield.field1 {docValues:true};サブフィールドが包含対象として選択されているため、親フィールドが含まれます。 検索インデックスを作成して、HTTPクエリー結果とsinglePassクエリーから除外するカラムを指定する
CREATE SEARCH INDEX ON wiki.solr WITH COLUMNS field1 { excluded:true }, field2 { excluded:false };除外されたカラムはHTTPクエリー結果に存在しませんが、インデックスが作成されていないカラムは含まれています。