DSE Graphとリレーショナル・データベースの比較
Graphデータベースとリレーショナル データベースはどちらもデータを格納できますが、ストレージ方法、スケーラビリティ、およびそれぞれが使用するインデックス作成の手法は大きく異なります。
DSE Graphは、非常に複雑なデータやクエリーに適しています。グラフ・データベースとリレーショナル・データベースは両方ともデータを格納できます。どちらのデータベース・タイプもクエリーして、フィルター処理された結果を取得できます。ただし、ストレージ方法、スケーラビリティ、およびそれぞれのデータベース・タイプが使用するインデックス作成の手法は大きく異なります。
以下のユース・ケースではDSE Graphをお勧めします。
- 不正検知
- レコメンデーション・エンジン
- ITネットワークおよびデバイス管理
- 在庫管理
- マスター・データ管理
格納
リレーショナル・データベースとDSE Graphの両方とも、データをテーブルに格納します。リレーショナル データベースでは、データを取得するためにキーが定義され、リレーションシップを共有するテーブルをリンクするために外部キーが必要です。データは正規化されます。つまり、データは重複が生じないように格納されます。複雑なクエリーを作成するには、複数のテーブルにアクセスして、データを結合および取得する必要があります。
DSE GraphではデータをDSEデータベース・テーブルに格納し、データ間のリレーションシップがモデルに埋め込まれます。グラフ・データベース内のデータ格納は、組み込みのデータ・リレーションシップを持つ事前に結合されたリレーショナル・データベースと比較できるため、外部キーは不要です。データはグラフを探索して取得されるため、時間がかかりエラーが発生しやすいJOIN操作は不要です。
ストリーミング
グラフ・データベースの追加の利点は、データベースの分散をスケーリングする機能があることです。グラフ・データベース・クエリーでは、特定の頂点から開始し、クエリー要件に基づいてグラフをフィルタリングします。一般に、取得にはグラフ全体のサブセットのフィルタリングが伴うため、グラフを分割することができます。クエリーは、DataStax Enterprise(DSE)クラスター内の単一または少数のノードで動作する、探索のいくつかのステップでは並行して実行できます。相互接続されたテーブルのため、クエリーを成功させるには、リレーショナル・データベース内の多数のテーブルにアクセスする必要があります。データの結合にはコストがかかるため、リレーショナル・データベースのスケール・アウトと分散が困難になります。
インデックス作成
グラフ・データベースとリレーショナル・データベースとの間のインデックス作成手法は大きく異なるため、パフォーマンスに著しく影響する可能性があります。XBox Oneを購入したすべての購入者を検索するクエリーを考えてみましょう。リレーショナル・データベースでは、そのクエリーに答えるために、3つのテーブルにアクセスします。
購入者テーブルの各購入者アイテム・テーブルでクエリーされているアイテム- JOIN操作で作成された、
購入者-アイテム・テーブルの購入者とアイテム

対照的に、グラフ・データベースでは、必要となるアイテムのインデックス検索は1つだけで、次にグラフを各購入者の頂点に移動してクエリーを完了します。
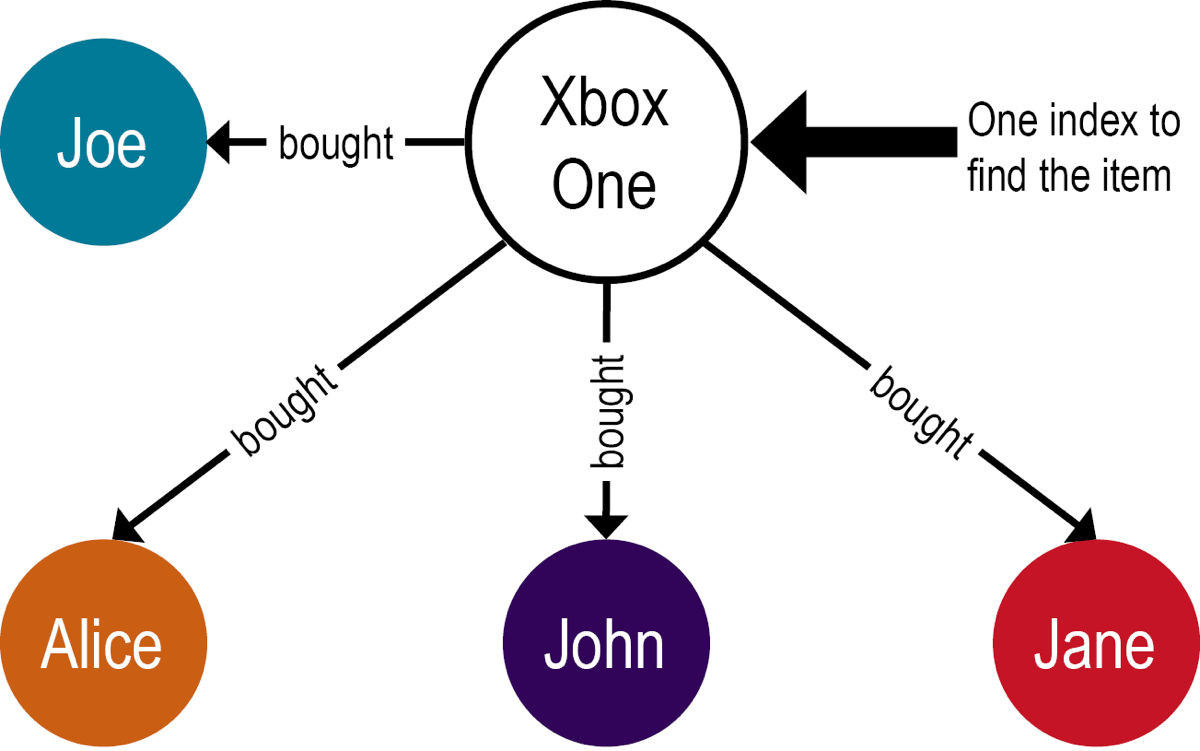
グラフ・データベース・クエリーは、ほぼ一定時間で実行されます。リレーショナル・データベース・クエリーは、バランスしたツリー(B-tree)インデックスが想定されている場合、O(log N)時間で実行されます。ここでNは、参照する必要のある各外部キーに対するテーブル内のレコード数です。1層クエリーであっても、これはパフォーマンスに大きな違いをもたらします。クエリーがより深くネストされると、パフォーマンスのギャップはさらに大きくなります。
DSE Graphでの複雑なクエリーの記述は、SQLを使用するリレーショナル・データベースよりもはるかに簡単です。製品に関する推奨エンジンに必要なクエリーを考えてみましょう。左側のSQLクエリーは、右側のGremlinクエリーよりもはるかに複雑です。
SQLに精通している開発者は多いのですが、この例は、複雑なクエリーを記述することが、専門家にとっても困難であることを示しています。対照的に、Gremlinのクエリーは左から右に直観的に読み込むことができ、各ステップは前のステップから引き継がれます。
