Hadoop support
Cassandra support for integrating Hadoop with Cassandra.
- MapReduce
- You must run separate datacenters: one or more datacenters with nodes running just Cassandra (for Online Transaction Processing) and others with nodes running C* & with Hadoop installed. See Isolate Cassandra and Hadoop for details.
- Before starting the datacenters of Cassandra/Hadoop nodes, disable virtual nodes
(vnodes).Note: You only need to disable vnodes in datacenters with nodes running Cassandra AND Hadoop.
- In the cassandra.yaml file, set num_tokens to 1.
- Uncomment the initial_token property and set it to 1 or to the value of a generated token for a multi-node cluster.
- Start the cluster for the first time.
You cannot convert single-token nodes to vnodes. See Enabling virtual nodes on an existing production clusterfor another option.
Setup and configuration, involves overlaying a Hadoop cluster on Cassandra nodes, configuring a separate server for the Hadoop NameNode/JobTracker, and installing a Hadoop TaskTracker and Data Node on each Cassandra node. The nodes in the Cassandra datacenter can draw from data in the HDFS Data Node as well as from Cassandra. The Job Tracker/Resource Manager (JT/RM) receives MapReduce input from the client application. The JT/RM sends a MapReduce job request to the Task Trackers/Node Managers (TT/NM) and an optional clients MapReduce. The data is written to Cassandra and results sent back to the client.
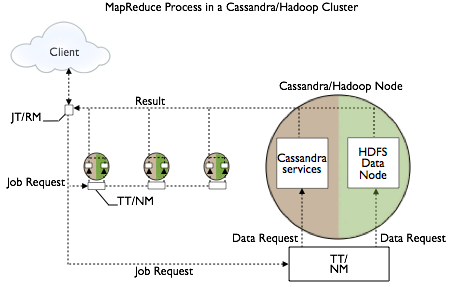
The Apache docs also cover how to get configuration and integration support.
Input and Output Formats
Hadoop jobs can receive data from CQL tables and indexes and can write their output to Cassandra tables as well as to the Hadoop FileSystem. Cassandra 3.0 supports the following formats for these tasks:
- CqlInputFormat class: for importing job input into the Hadoop filesystem from CQL tables
- CqlOutputFormat class: for writing job output from the Hadoop filesystem to CQL tables
- CqlBulkOutputFormat class: generates Cassandra SSTables from the output of Hadoop jobs, then loads them into the cluster using the SSTableLoaderBulkOutputFormat class
Reduce tasks can store keys (and corresponding bound variable values) as CQL rows (and respective columns) in a given CQL table.
Running the wordcount example
Wordcount example JARs are located in the examples directory of the Cassandra source code installation. There are CQL and legacy examples in the hadoop_cql3_word_count and hadoop_word_count subdirectories, respectively. Follow instructions in the readme files.
Isolating Hadoop and Cassandra workloads
When you create a keyspace using CQL, Cassandra creates a virtual datacenter for a cluster, even a one-node cluster, automatically. You assign nodes that run the same type of workload to the same datacenter. The separate, virtual datacenters for different types of nodes segregate workloads running Hadoop from those running Cassandra. Segregating workloads ensures that only one type of workload is active per datacenter. Separating nodes running a sequential data load, from nodes running any other type of workload, such as Cassandra real-time OLTP queries is a best practice.
| DataStax Enterprise 5.0 Installer-Services and package installations | /etc/dse/cassandra/cassandra.yaml |
| DataStax Enterprise 5.0 Installer-No Services and tarball installations | install_location/resources/cassandra/conf/cassandra.yaml |
| Cassandra package installations | /etc/cassandra/cassandra.yaml |
| Cassandra tarball installations | install_location/resources/cassandra/conf/cassandra.yaml |