Restoring a backup to a specific point-in-time
A point-in-time restore uses commit log archives to restore data from a backup to a specific date and time using OpsCenter.
For a point-in-time restore, OpsCenter intelligently chooses which snapshots and commit logs to restore from based on the date and time you are restoring the cluster to. If an acceptable combination of snapshots and commit logs cannot be found, the restore fails. A detailed error message is visible in the Activity section of the OpsCenter UI.
- Restoring a snapshot that contains only the system keyspace is not allowed. There must be both system and non-system keyspaces, or only non-system keyspaces in the snapshot you want to restore.
- Restoring a snapshot that does not contain a table definition is not allowed.
- Restoring a snapshot to a location with insufficient disk space fails. The Restore Report indicates which nodes do not have sufficient space and how much space is necessary for a successful restore. For more information and tips for preventative measures, see Monitoring sufficient disk space for restoring backups.
- OpsCenter does not back up indexes. Therefore, DSE must recompute the indexes after a restore.
dse-env.sh
The default location of the dse-env.sh file depends on the type of installation:| Package installations | /etc/dse/dse-env.sh |
| Tarball installations | installation_location/bin/dse-env.sh |
Prerequisites
For point-in-time restores to work, you must enable commit log backups and complete at least one snapshot backup before the time to which you are restoring.
Known limitations
- Point-in-time restore fails if any tables were recreated during the time period of the actual point-in-time restore.
- For point-in-time restores, you cannot choose a different cluster because the commitlog cannot be played on a different node other than the one it was recorded.
Procedure
- Click .
- Click the Details link for the Backup Service.
-
Click Restore Backup.
The Restore from Backup, Step 1 of 2: Select Backup dialog appears.
-
Click the Point In Time tab.
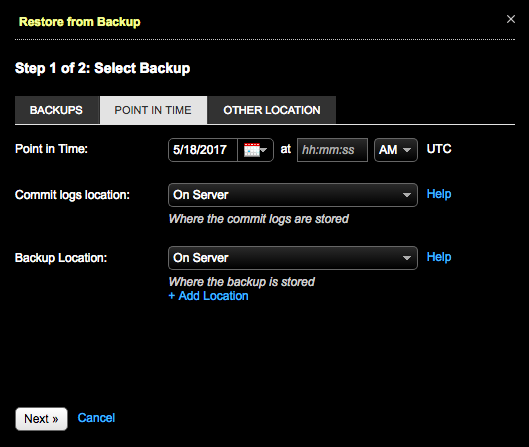
-
Complete your selections:
-
Click Next.
The Restore from Backup, Step 2 of 2: Configure and Restore dialog appears.
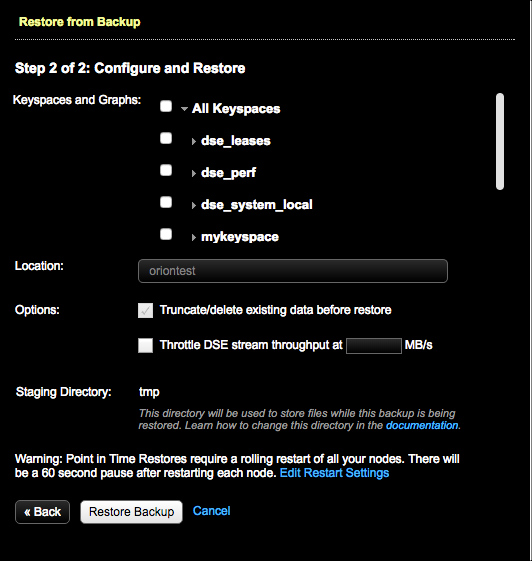
-
Click Next.
-
In Keyspaces and Graphs, select the tables or graphs you
want to restore.
- Click All Keyspaces or All Graphs to restore all keyspaces or all graphs.
- Click the keyspace name or graph name to include all tables or all graphs in the keyspace.
- To select specific tables or graphs, expand the keyspace name or graph name and select the specific tables or graphs to back up.
Note: For DSE 6.0.0-6.0.4, when restoring a DSE Graph backup without selecting Use sstableloader, DSE must be restarted to ensure all data is available. - Optional:
To remove the existing keyspace data before the data is restored, select
Truncate/delete existing data before restore. This
completely removes any updated data in the cluster for the keyspaces you are
restoring.
Note: Choosing to not truncate or delete existing data can be selected only when sstableloader is used for the restore. If not using sstableloader, truncating or deleting existing data is selected by default.
-
To prevent overloading the network, set a maximum
transfer rate for the restore using the Throttle DSE stream
throughput at ____ MB option.
Note: To enter a value for this option, you must select Use sstableloader. Otherwise, the transfer rate value is ignored.
- Optional:
To bulk load external data into a cluster, select Use
sstableloader.
Important: OpsCenter 6.7.5 and earlier cannot execute a restore that bypasses
sstableloaderfor DataStax Enterprise (DSE) 6.7.6 and later, DSE 6.0.11 and later, and DSE 5.1.17 and later. This issue is caused by an OpsCenter check that cannot validate the SSTable format change in DSE 6.7.6. To restore data on a cluster from a DSE backup with the new SSTable format, select Use sstableloader when restoring data or upgrade to OpsCenter 6.7.6 or later. (OPSC-16237)Note: Using sstableloader restores data to a cluster regardless of its original topology, at the expense of speed and performance. Restoring to a cluster that uses tiered storage requires using sstableloader. See sstableloader for details.When restoring from a backup, OpsCenter might report that the restore was successful, even if it failed. This behavior can occur when copying SSTables into the new data directories and running
nodetool refreshafterward. To determine whether the restore failed, search the DataStax Agent logs for a string indicating"Error copying sstables to data dir:". This issue is present only in OpsCenter 6.7.0. - Optional:
If necessary, change the staging directory by setting the
backup_staging_directoryconfiguration option in address.yaml. - Optional: Click the Edit Restart Settings link to adjust settings for the rolling restart. The default is a 60 second pause after restarting each node. Point-in-Time restores require a rolling restart of all nodes.
- Click Restore Backup.
-
Click Restore Backup.
The Confirm Restore dialog appears.
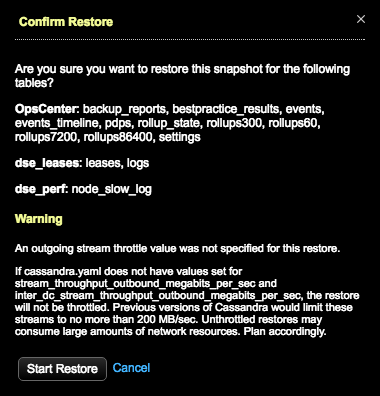 Warning: If a value was not set for throttling stream output, a warning message indicates the consequences of unthrottled restores. Take one of the following actions:
Warning: If a value was not set for throttling stream output, a warning message indicates the consequences of unthrottled restores. Take one of the following actions:- Click Cancel and set the throttle value in the Restore from Backup dialog.
- Set the
stream_throughput_outbound_megabits_per_secandinter_dc_stream_throughput_outbound_megabits_per_secvalues in cassandra.yaml. - Proceed anyway at the risk of creating network bottlenecks.
Tip: If using LCM to manage DSE cluster configuration, update Cluster Communication settings in cassandra.yaml in the configuration profile for the cluster and run a configuration job. Stream throughput (not inter-dc) is set to 200 in LCM defaults.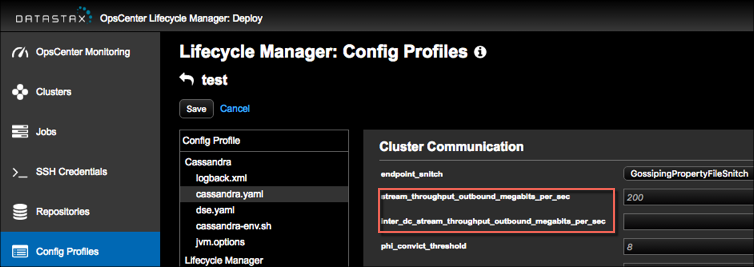
- Click Start Restore to confirm when prompted.
Results
OpsCenter retrieves the backup data and sends the data to the nodes in the cluster. A snapshot restore is completed first, following the same process as a normal snapshot restore. After the snapshot restore successfully completes, OpsCenter instructs all agents in parallel to download the necessary commit logs, followed by a rolling commit log replay across the cluster. Each node is configured for replay and restarted after the previous node finishes successfully.
If an error occurs during a point-in-time restore for a subset of tables, you might
need to manually revert changes made to some cluster nodes. To clean up a node, edit
dse-env.sh and remove the last line that specifies
JVM_OPTS. For example:
export JVM_OPTS="$JVM_OPTS -Dcassandra.replayList=Keyspace1.Standard1"