Sparkとは
Sparkのアーキテクチャーおよび機能に関する情報。
Sparkは、パッケージ型インストールでAnalyticsノードを起動する場合のデフォルトのモードです。Sparkは、各ノードでローカルに実行され、可能な場合はメモリー内で実行されます。Sparkは複数のプロセスではなく複数のスレッドを使用することで、1つのノードでの並列処理を実現し、複数のJVMでメモリー・オーバーヘッドが生じるのを防ぎます。
- DSEのデータ・ストアにアクセスするためのSpark Cassandra Connector
- DSEクラスター内のSparkコンポーネントを管理するためのDSE Resource Manager(DSEリソース・マネージャー)
- Sparkジョブ・サーバー
- Spark SQLのサポート
- Spark SQL Thriftサーバー
- Sparkストリーミング
- Spark内でデータを操作するためのDataFrames API
- DataStax EnterpriseでSparkRを使用する
Sparkアーキテクチャー
- Sparkワーカー
- DataStax Enterpriseファイル・システム(DSEFS)
- Cassandraファイル・システム(CFS)。DSE 5.1以降廃止予定
- データベース
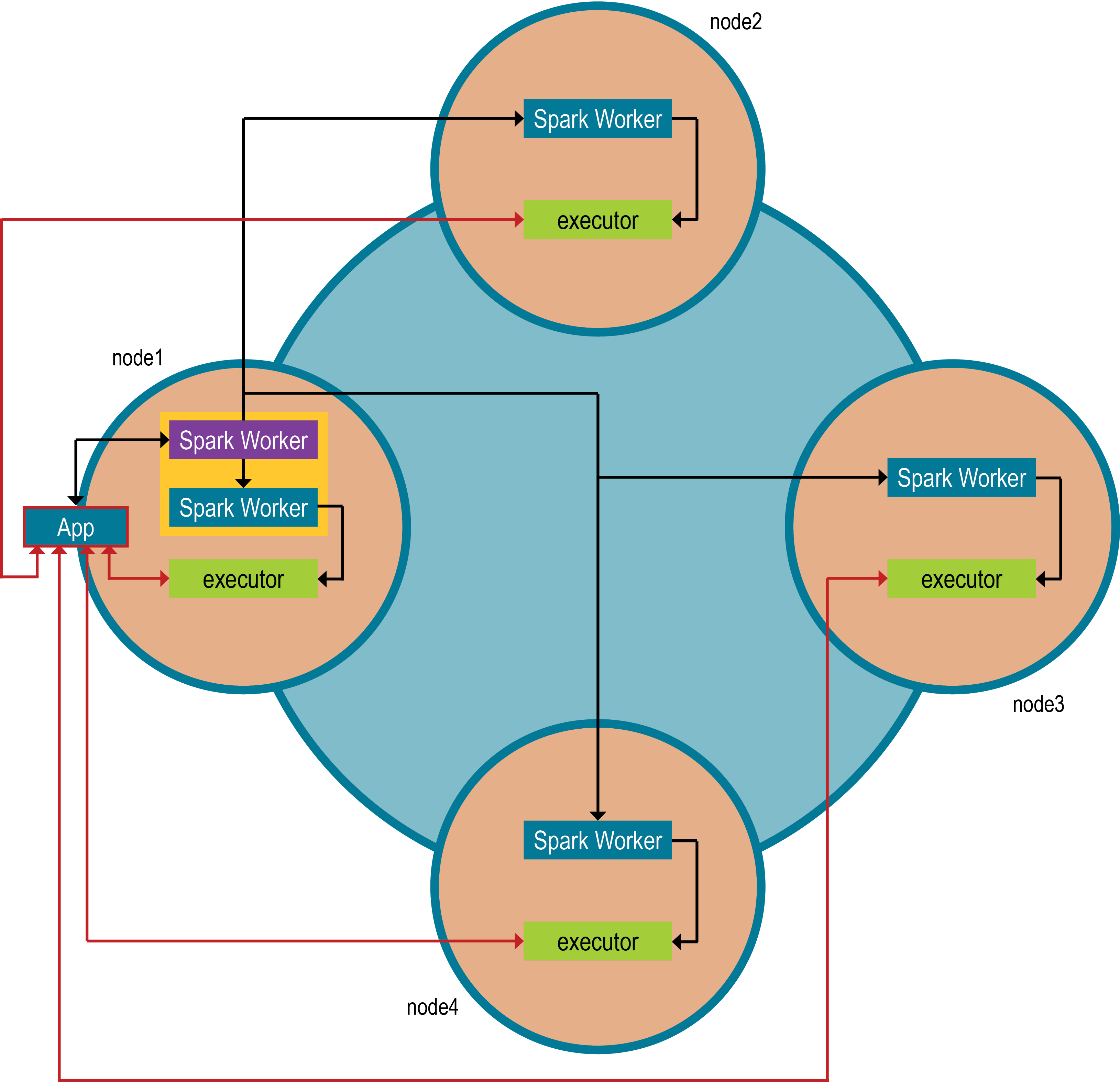
Sparkマスターは、純粋にSparkアプリケーションのリソース・マネージャーとして機能します。Sparkワーカーは、Sparkマスターに送信されたジョブの一部の実行を担当するエグゼキューターを起動します。アプリケーションごとに独自のエグゼキューターのセットがあります。Sparkアーキテクチャーの詳細については、Apacheのドキュメントを参照してください。
DSE Sparkノードは、スタンドアローンSparkノードとは別のリソース・マネージャーを使用します。DSE Resource Manager(DSEリソース・マネージャー)によって、SparkとDSE間の統合が簡素化されます。DSE Sparkクラスターでは、クライアント・アプリケーションはCQLプロトコルを使用して任意のDSEノードと接続し、そのノードはSparkマスターに要求をリダイレクトします。
Sparkクライアント・アプリケーション(またはドライバー)とSparkマスター間の通信は、DSEとの接続と同じ方法でセキュリティ保護されます。すなわち、普通のパスワード認証とKerberos認証がサポートされ、SSL暗号化の採用は任意となります。暗号化と認証は、クラスターごとではなく、アプリケーションごとに構成できます。Sparkマスターとワーカーのノード間の認証と暗号化は、アプリケーションの設定に関係なく、有効または無効にすることができます。
Sparkは複数のアプリケーションをサポートしています。1つのアプリケーションによって複数のジョブが生成される場合、これらのジョブは並列実行されます。アプリケーションは各ノードで一部のリソースを予約し、これらのリソースはアプリケーションが終了するまで解放されません。たとえば、Sparkシェルの各セッションは、リソースを予約するアプリケーションです。デフォルトで、スケジューラーは、最大数のノードにアプリケーションを割り当てようとします。たとえば、4つのコアが必要であることをアプリケーションが宣言している場合に、2コアずつ搭載したサーバーが10台あるとします。この場合、アプリケーションは、それぞれ異なるノードに置かれて1つのコアを消費する、4つのエグゼキューターを取得する可能性が大です。ただし、このアプリケーションは、それぞれ2つの異なるノードに置かれて2コアを消費する、2つのエグゼキューターを取得する可能性もあります。ユーザーはアプリケーション・スケジューラーを構成できます。SparkワーカーとSparkマスターは、メインDSEプロセスに含まれています。ワーカーは、Sparkアプリケーション(またはドライバー)の実際の作業を実行するエグゼキューターJVMプロセスを生成します。Sparkエグゼキューターは、ネイティブ統合を使用して、オープン・ソースのSpark-Cassandra Connector経由でローカル・トランザクション・ノード内のデータにアクセスします。エグゼキューターJVMのメモリー設定は、ユーザーがドライバーをDSEに送信することで設定されます。
各Analyticsデータ・センターのデプロイ環境では、1つのノードがSparkマスターを実行し、各ノードでSparkワーカーが実行されます。Sparkマスターには、自動高可用性機能が組み込まれています。
Sparkを実行すると、Hadoop分散ファイル・システム(HDFS)、Cassandraファイル・システム(CFS)、またはDataStax Enterpriseファイル・システム(DSEFS)の各ファイル・システムのURLを使用して、そのファイル・システム内のデータにアクセスできます。
高可用性Sparkマスター
Sparkマスターの高可用性メカニズムでは、spark_systemキースペースの特殊なテーブルを使用して、Sparkワーカーとアプリケーションのリカバリーに必要な情報を格納します。Sparkのドキュメントに記載されている高可用性メカニズムと異なり、DataStax EnterpriseではZooKeeperは使用されません。
元のSparkマスターで障害が発生した場合は、予備のSparkマスターが自動的に処理を継承します。現在のSparkマスターを見つけるには、以下のように実行します。
$ dse client-tool spark master-address
DataStax Enterpriseでは、自動Sparkマスター管理を利用できます。
サポートされていないSparkの機能
- SparkからBLOBカラムへの書き込み
あらゆる型のカラムの読み取りがサポートされていますが、シリアライズする前に、BLOBのコレクションをバイト配列に変換しておく必要があります。