Using Hive
DataStax Enterprise includes a Cassandra-enabled Hive MapReduce client.
DataStax Enterprise includes a Cassandra-enabled Hive MapReduce client. Hive is a data warehouse system for Hadoop that projects a relational structure onto data stored in Hadoop-compatible file systems. You use Hive to query Cassandra data using a SQL-like language called HiveQL.
You start the Hive client on an analytics node and run MapReduce queries directly on data stored in Cassandra. Using the DataStax Enterprise ODBC driver for Hive, a JDBC compliant user interface can connect to Hive from the Hive server.
Why Hive
By using Hive, you typically eliminate boilerplate MapReduce code and enjoy productivity gains. The large base of SQL users can master HiveQL quickly. Hive has a large set of standard functions, such as mathematical and string functions. You can use Hive for queries that Cassandra as a NoSQL database does not support, such as joins. DataStax Enterprise support of Hive facilitates the migration of data to DataStax Enterprise from a Hive warehouse. Hive capabilities are extensible through a Hive user-defined function (UDF), which DataStax Enterprise supports.
Typical uses for Hive are:
- Reporting
User engagement and impression click count applications
-
Ad hoc analysis
- Machine learning
Advertising optimization
Hive in DataStax Enterprise
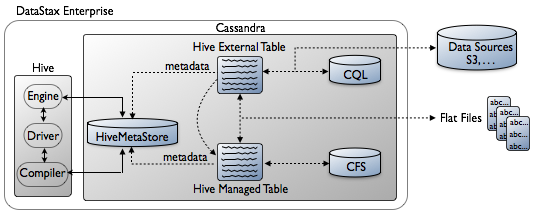
DataStax Enterprise analytics nodes store Hive table structures in the Cassandra File System (CFS) instead of in a Hadoop Distributed File System (HDFS). You layer a Hive table definition onto a directory in the file system or use Hive to query a CQL table. The Hive table definition describes the layout of the data and is stored in the HiveMetaStore keyspace. DataStax Enterprise implements the Hive metastore as the HiveMetaStore keyspace within Cassandra. Unlike open source Hive, there is no need to run the metastore as a standalone database to support multiple users.
The consistency level of Hadoop nodes is ONE by default, but when processing Hive queries, if DataStax Enterprise can guarantee that all replicas are in the same data center, the consistency level of LOCAL_ONE is used.
There are two types of Hive tables: external tables and managed tables.
Automatically created external tables
DataStax Enterprise 4.5 automatically creates a Hive external table for each existing CQL table when you attempt to use the keyspace/table name in Hive. Exception: After upgrading, you need to enable auto-creation of tables.
About custom external tables
You can create a custom external table using TBLPROPERTIES and SERDEPROPERTIES when the auto-created table does not suit your needs. The external table data source is external to Hive, located in CQL. When you drop a Hive external table, only the table metadata stored in the HiveMetaStore keyspace is removed. The data persists in CQL.
Restoring tables after upgrading
You need to map custom external tables to the new release format after upgrading any release of DataStax Enterprise 4.5. DataStax Enterprise provides the hive-metastore-migrate tool for mapping the tables to the new format. The tool is in the hive-metastore-<version>.jar in resources/hive/lib.
Use the hive-metastore-migrate tool only after upgrading and only on a stable cluster.
- Upgrade DataStax Enterprise.
- Check that the cluster is stable after upgrading.
- Call the hive-metastore-migrate tool using the following options:
- -from <from>
Source release number
- -help
Print hive-metastore-migrate command usage
- -host <host>
Host name
- -password <password>
Password
- -port <port>
Port number
- -to <to>
Destination release number
- -user <user>
User name
bin/dse hive-metastore-migrate --to 4.7.1 --from 4.5.0In this example, the old Hive tables in 4.5.0 format are mapped to the new 4.7.1 release format.
The hive-metastore-migrate tool copies the metadata to a row key using a prefix, for example 4.5.0_, that you specify using the -to option. The tool inserts data for a row key only if there is no data for that row/column.
Enabling automatic generation of external tables after upgrading
After upgrading to DataStax Enterprise 4.5.x automatic generation of external tables is disabled. To enable automatic generation of external tables, start Hive and run one of these commands at the Hive prompt to enable automatic generation of external tables:- SHOW databases
- USE <database name>
Managed tables
Instead of an external table, you can use a Hive managed table. Hive manages storing and deleting the data in this type of table. DataStax Enterprise stores Hive managed table data in the Cassandra File System (CFS). The data source for the Hive managed table can be a flat file that you put on the CFS using a dse hadoop -fs command or the file can be elsewhere, such as on an operating system file system. To load the managed file file, use the LOAD [LOCAL] DATA INPATH, INSERT INTO, or INSERT OVERWRITE Hive commands. You use Hive external tables to access Cassandra or other data sources, such as Amazon S3. Like the Hive managed table, you can populate the external table from flat files on the local hard drive, as well as dumped the data from Hive to a flat file. You can also copy an external table, which represents a Cassandra table, into a Hive managed table stored in CFS. The following diagram shows the architecture of Hive in DataStax Enterprise.
Hive metastore configuration
The HiveMetaStore in DataStax Enterprise supports multiple users and requires no configuration except increasing the default replication factor of the keyspace. The default replication for system keyspaces is 1. This replication factor is suitable for development and testing, not for a production environment. To avoid production problems, alter the replication factor of these system keyspaces from 1 to at least 3.
- HiveMetaStore
- cfs
- cfs_archive keyspaces
To prevent missing data problems or data unavailable exceptions after altering keyspaces that contain any data, run nodetool repair as shown in these examples.
Supported Hive features
The Hive component in DataStax Enterprise includes querying capabilities, data type mapping, and performance enhancements. The following Hive 0.12 features are supported:
- Windowing functions
- RANK
- LEAD/LAG
- ROW_NUMBER
- FIRST_VALUE, LAST_VALUE
- Aggregate OVER functions with PARTITION BY and ORDER BY
DataStax Enterprise supports most CQL and Cassandra internal data types. DataStax provides a Hive user-defined function (UDF) for working with unsupported types, such as blob:
org.apache.hadoop.hive.cassandra.ql.udf.UDFStringToCassandraBinary
This UDF converts from Hive Strings to native Cassandra types. Due to limitations in Hive, the UDF can be used only to convert Hive Strings to string primitives, not collections that are arrays and maps of strings. It is not possible to use the UDF to convert, for example, an array of strings representing inet addresses to an array of InetAddress columns in Cassandra.
.