When you start a DataStax Enterprise cluster without vnodes, you must ensure that the data
is evenly divided across the nodes in the cluster using token assignments and that no two
nodes share the same token even if they are in different datacenters. Tokens are hash values
that partitioners use to determine where to store rows on
each node. This value determines the node's position in the ring and what data the node is
responsible for. Each node is responsible for the region of the cluster between itself
(inclusive) and its predecessor (exclusive).
As a simple example, if the range of possible tokens is 0 to 100 and there are four nodes,
the tokens for the nodes are: 0, 25, 50, 75. This division ensures that each node is
responsible for an equal range of data. For more information, see Data distribution and replication.
Before starting each node in the cluster for the first time, comment out the num_token property and assign an initial-token value in the
cassandra.yaml configuration file.
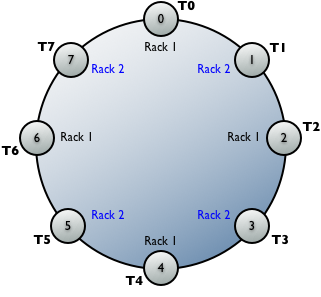
Assign the tokens to nodes on alternating racks in the cassandra-rackdc.properties or
the cassandra-topologies.properties file. Alternating rack assignments
Calculating tokens for a multiple datacenter
cluster
Note: Do not use SimpleStrategy for this type of cluster. You must use the
NetworkTopologyStrategy. This strategy determines replica placement independently within
each datacenter.
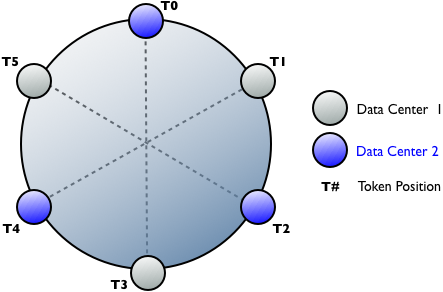
After calculating the tokens, assign the tokens so that the nodes in each datacenter are
evenly dispersed around the ring.Token position and datacenter assignments
Alternate the rack assignments as described above.
Calculating tokens when adding or replacing nodes/datacenters
To avoid token collisions, use the --ringoffset option.
Calculate the tokens with the
offset:
token-generator 3 2 --ringoffset 100
The results show the
generated token values for the Murmur3Partitioner for one datacenter with 3 nodes and
one datacenter with 2 nodes with an
offset:
DC #1:
Node #1: 6148914691236517105
Node #2: 12297829382473034310
Node #3: 18446744073709551516
DC #2:
Node #1: 9144875253562394637
Node #2: 18368247290417170445
The value of the offset is for the first node and all other nodes are calculated for
even distribution from the offset.
After calculating the tokens, assign the tokens so that the nodes in each datacenter
are evenly dispersed around the ring and alternate the rack assignments.
The location of the
cassandra.yaml file depends on
the type of installation: