Mixing workloads in a cluster
Organize nodes that run different workloads into virtual datacenters. Put analytic nodes in one datacenter, search nodes in another, and Cassandra real-time transactional nodes in another datacenter.
- Real-time Cassandra,
- DSE Hadoop, which is integrated Hadoop
- External Hadoop in the bring your own Hadoop (BYOH) model
- DSE Analytics (Spark)
- DSE Search nodes
The answer is to organize the nodes running different workloads into virtual datacenters: analytics workloads (either DSE Hadoop, Spark, or BYOH) nodes in one datacenter, search nodes in another, and Cassandra real-time nodes in another datacenter.
DataStax supports a datacenter that contains one or more nodes running in dual Spark/DSE Hadoop mode. Dual Spark/DSE Hadoop mode means you started the node using the -k and -t options on tarball or Installer-No Services installations, or set the startup options HADOOP_ENABLED=1 and SPARK_ENABLED=1 on package or Installer-Services installations.
DSE Analytics (Spark) workloads
The recommend approach for running Spark and Cassandra is to run all analytics (OLAP) in a datacenter that is separate from transactional (OLTP) Cassandra workload. This workload segregation avoids contention for Cassandra resources, and allows you to scale resources for OLTP and OLAP separately. If there is not a large demand for analytics, then you can run DataStax Enterprise in a single datacenter that serves both OLTP and OLAP requests. However, this combined transactional (OLTP) and analytics (OLAP) workload results in decreased performance.
DSE SearchAnalytics workloads (experimental)
DSE SearchAnalytics clusters can use DSE Search queries within DSE Analytics jobs. An integrated DSE SearchAnalytics cluster allows analytics jobs to be performed using search queries.
BYOH workloads
BYOH nodes must be isolated from Cloudera or Hortonworks masters.
DSE Search workloads
The batch needs of Hadoop and the interactive needs of DSE Search are incompatible from a performance perspective, so these workloads need to be segregated.
Cassandra workloads
To keep Cassandra write throughout at the maximum performance, segregate Cassandra workloads separate from other workload types like DSE Search workloads.
Creating a virtual datacenter
When you create a keyspace using CQL, Cassandra creates a virtual datacenter for a cluster, even a one-node cluster, automatically. You assign nodes that run the same type of workload to the same datacenter. The separate, virtual datacenters for different types of nodes segregate workloads that run DSE Search from those nodes that run other workload types. Segregating workloads ensures that only one type of workload is active per datacenter.
Workload segregation
- Real-time queries (Cassandra and no other services)
- DSE Analytics (either DSE Hadoop, Spark, or dual mode DSE Hadoop/Spark)
- DSE Search
- External Hadoop system (BYOH)
In a cluster that has BYOH and DSE Hadoop nodes, the DSE Hadoop nodes would have priority with regard to start up. Start up seed nodes in the BYOH datacenter after starting up DSE Hadoop datacenters.
Occasionally, there is a use case for keeping DSE Hadoop and Cassandra nodes in the same datacenter. You do not have to have one or more additional replication factors when these nodes are in the same datacenter.
To deploy a mixed workload cluster, see "Multiple datacenter deployment."
- Real-time queries (Cassandra and no other services)
- Analytics (Cassandra and integrated Hadoop)
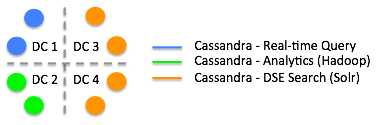
This diagram shows DSE Hadoop analytics, Cassandra, and DSE Search nodes in separate datacenters. In separate datacenters, some DSE nodes handle search while others handle MapReduce, or just act as real-time Cassandra nodes. Cassandra ingests the data, Solr indexes the data, and you run MapReduce against that data in one cluster without performing manual extract, transform, and load (ETL) operations. Cassandra handles the replication and isolation of resources. The DSE Search nodes run HTTP and hold the indexes for the Cassandra table data. If a DSE Search node goes down, the commit log replays the Cassandra inserts, which correspond to Solr inserts, and the node is restored automatically.
Restrictions
- Do not create the keyspace using SimpleStrategy for production use or for use with mixed workloads.
- Within the same datacenter, do not run Solr workloads on some nodes and other types of workloads on other nodes.
- Do not run DSE Search and DSE Hadoop on the same node in either production or development environments.
- Do not run some nodes in DSE Hadoop mode and some in Spark mode in the same
datacenter.
You can run all the nodes in Spark mode, all the nodes in Hadoop mode or all the nodes in Spark/DSE Hadoop mode.
Recommendations
Run the CQL or Thrift inserts on a DSE Search node in its own datacenter.
NetworkTopologyStrategy is highly recommended for most deployments because it is much easier to expand to multiple datacenters when required by future expansion.
Getting cluster workload information
- Analytics
- Cassandra
- Search
SELECT workload FROM system.local;The output looks something like this:
workload
----------
AnalyticsDESCRIBE FULL schemaCREATE TABLE peers (
peer inet,
data_center text,
host_id uuid,
preferred_ip inet,
rack text,
release_version text,
rpc_address inet,
schema_version uuid,
tokens settext,
workload text,
PRIMARY KEY ((peer))
) WITH
. . .;Replicating data across datacenters
You set up replication by creating a keyspace. You can change the replication of a keyspace after creating it.