Getting started with graph databases
Graph databases are useful for discovering simple and complex relationships between objects. These things can be people, software, locations, automobiles, or anything else you can think of. Relationships are fundamental to how objects interact with one another and their environment. Graph databases are the perfect representation of the relationships between objects.
Graph databases consist of three elements: vertices, edges and properties Vertices are objects, such as people or artifacts. Edges define the relationships between nodes. Vertices, edges and properties can have properties; for this reason, DSE Graph is classified as a property graph. The properties for all elements are an important element of storing and querying information from a property graph.
Property graphs are typically quite large, although the nature of querying the graph will vary depending on whether the graph has large numbers of vertices, edges, or both vertices and edges. To get started with graph database concepts, a "toy" graph is used for simplicity. The example used here explores the world of food.
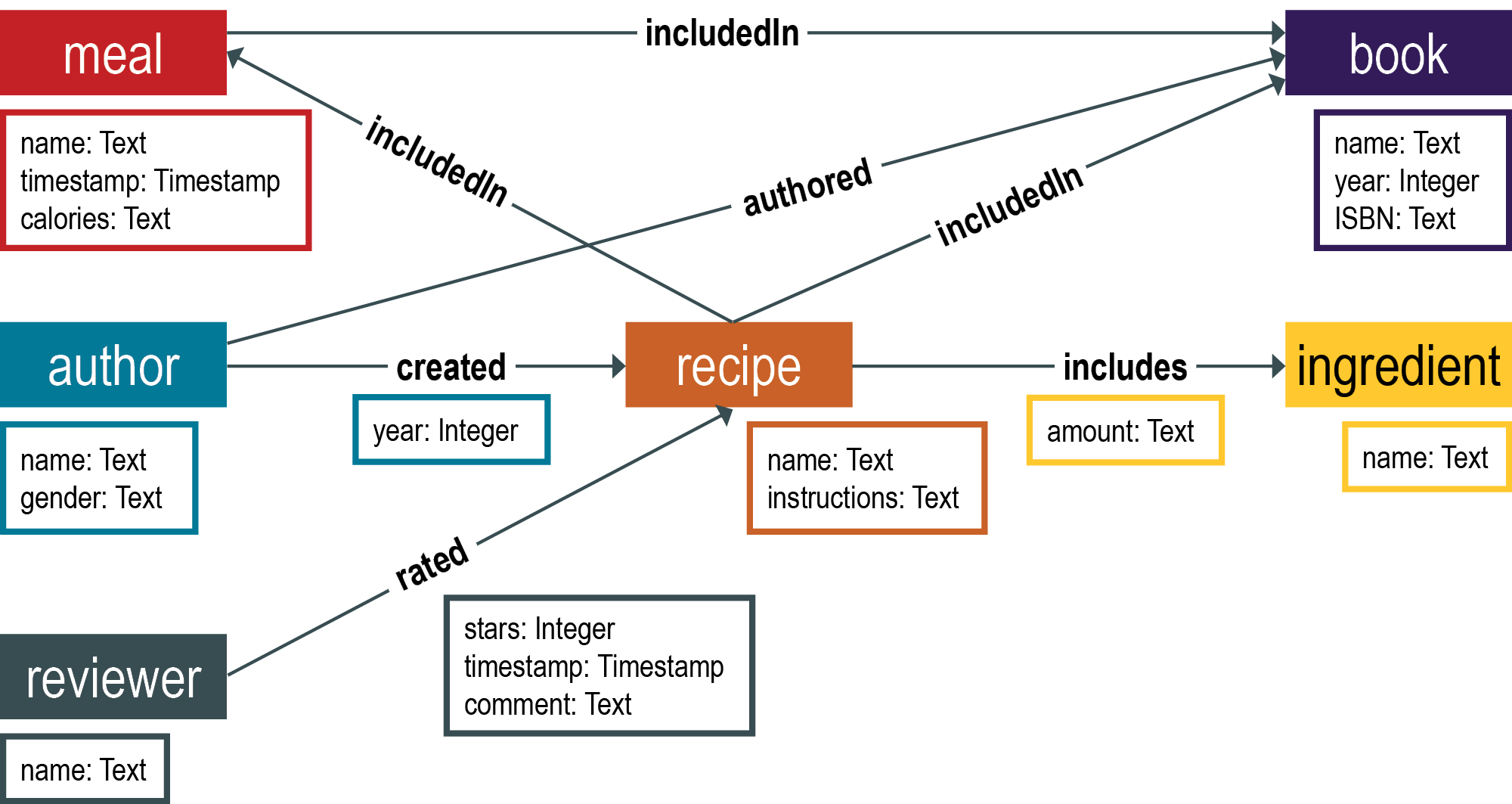
Elements are labeled to distinguish the type of vertices and edges in a graph database. A vertex that will hold information about an author is labeled author. An edge in the graph is labeled authored. Labels specify the types of vertices and edges that make up the graph. Specifying appropriate labels is an important step in graph data modeling.
Vertices and edges generally have properties. For instance, an author vertex can have a name. Gender and current job are examples of additional properties for a author vertex. Edges also have properties. A created edge can have a timestamp property that identifies when the adjoining recipe vertex was created.
Properties can also have properties. Consider the locations that an author may have lived in while authoring books. While knowing the writing location may be interesting by itself, generally an inquirer is interested in the dates that a person lived in a particular location. Would it be interesting to know if Julia Child lived in France or the United States while writing her first cookbook? It could be relevant if the cookbook is on French cuisine.
There are a variety of methods for ingesting data into DSE Graph.
- DSE Graph Loader
-
Data can be loaded using the DSE Graph Loader. CSV, JSON, text parsed with regular expressions, and data selected from a JDBC compliant database can be loaded using a command line tool.
- Gremlin commands
-
Data can be added using Gremlin commands. This is a useful method for toy (small graphs) used for development and test. An API exists for adding data using Gremlin commands as well, so Gremlin is common in scripts. The Quick Start shows some of the common Gremlin commands for creating a graph and running traversals.
- Gryo
-
Data can be loaded using Gryo, a binary format, if the data was previously stored in Titan or TinkerGraph. Gryo files can be transferred directly using the schema from the original database.
- GraphSON
-
Data can be entered with GraphSON, a JSON format that is useful for transferring human-readable data. GraphSON files can lose data type information in transfer unless lossless data is generated.
- GraphML
-
Data can be entered using GraphML, an XML format that is useful for transferring graph data. However, data type information is lost with GraphML data transfer.
After loading data, graph traversals are executed to retrieve filtered information.
In relational databases, queries are retrieved that combine and filter information.
In graph databases, the vertex properties, edge connections, and edge properties all play a role in picking a starting point in the graph and traversing the connections to provide a particular answer to a query.
Several TraversalSources, that supply a traversal strategy and traversal engine to use in executing traversals, can be generated for any Graph.
Queries in graph databases can consist of several traversals if a complex question is asked, or trivially include no traversals, if a mathematical calculation like 1 + 1 is submitted.
