マッピング・スクリプト
マッピング・スクリプトの本文について説明します。
どのファイル形式を選択しても、マッピング・スクリプトの本文は同じです。構成を設定し、データ入力ソースを追加すると、マッピング・コマンドが指定されます。
手順
-
頂点ラベルが
authorでプロパティ・キーがnameのauthorInputから頂点が読み込まれ、keyについてリストされた頂点を一意に識別します。この例では、キーにgenderが選択された場合、データ・ファイルから各レコードを読み込むのに十分な一意性がなくなることに注意してください。構成設定load_new: trueを使用すると、読み込みプロセスの速度が大幅に向上しますが、レコードが既に存在する場合は、重複する頂点が作成されます。他のプロパティ・キーがすべて読み込まれますが、読み込みスクリプトで識別する必要はありません。author頂点の場合は、genderも読み込まれます。load(authorInput).asVertices { label "author" key "name" }1つ以上の頂点に対して同じファイルを再使用する場合でも、頂点を読み込むたびに読み込み文を1つ作成する必要があります。複数の頂点に同じ入力ファイルを使用すると、特定の頂点について無視する必要があるフィールドが入力ファイルに存在する場合があります。フィールドを無視する手順を参照してください。
authorsやreviewersなどの異なる頂点ラベルに読み込む必要がある複数のタイプの行が入力ファイルに含まれる場合は、labelFieldの手順を参照してください。 -
本の頂点の読み込みは、似たようなパターンに従います。
authorおよびbookの頂点ラベルは両方とも、頂点を識別するためのユニーク・キーとしてnameを使用します。これによって、読み込みプロセスの開始時に頂点レコードがグラフにまだ存在しないことが宣言されます。load(bookInput).asVertices { label "book" key "name" } -
頂点が読み込まれた後に、エッジが読み込まれます。頂点のマッピングと同様に、エッジ・ラベルが指定されます。また、エッジの外向き頂点(outV)と内向き頂点(inV)を識別する必要があります。
outVまたはinVの頂点ごとに、頂点ラベルはlabelで指定され、ユニーク・キーがkeyで指定されます。load(authorBookInput).asEdges { label "authored" outV "aname", { label "author" key "name" } inV "bname", { label "book" key "name" } }outVとinVの指定に使用される命名規則に注意してください。外向きと内向きの頂点キーは両方ともnameとしてリストされるため、入力ファイルのフィールド名として著者名と本の名前を区別するために指定子anameおよびbnameが使用されます。 -
前述の定義に代わる手段として、変数でマッピング・ロジックを指定してから、読み込み文を個別にリストすることが挙げられます。
authorMapper = { label "author" key "name"} bookMapper = { label "book" key "name" } authorBookMapper = { label "authored" outV "aname", { label "author" key "name" } inV "bname", { label "book" key "name" } } load(authorInput).asVertices(authorMapper) load(bookInput).asVertices(bookMapper) load(authorBookInput).asEdges(authorBookMapper)
入力ファイルのフィールドを無視する
DSE Graph Loaderを使用してデータのマッピング時にフィールドを無視する。
特定の頂点の読み込みについて無視する必要があるフィールドを入力ファイルに含める場合は、ignoreを使用します。
手順
-
フィールド
restaurantを無視するマップ・スクリプトを作成します。// authorInput includes name, gender, and restaurant // but restaurant is not loaded /* Sample input: name|gender|restaurant Alice Waters|F|Chez Panisse */ load(authorInput).asVertices { label "author" key "name" ignore "restaurant" } -
追加の例で、
ignoreの使用方法を示します。同じ入力ファイルを使用して、bookおよびauthorという2つの異なるタイプの頂点が作成されます。/* Sample input: name|gender|bname Julia Child|F|The French Chef Cookbook Simone Beck|F|The Art of French Cooking, Vol. 1 */ //inputfiledir = '/tmp/TEXT/' authorInput = File.text("author.dat"). delimiter("|"). header('name', 'gender','bname') //Specifies what data source to load using which mapper (as defined inline) load(authorInput).asVertices { label "book" key "bname" ignore "name" ignore "gender" } load(authorInput).asVertices { label "author" key "name" outV "book", "authored", { label "book" key "bname" } }
labelFieldを使用して、他の頂点ラベルへの入力を解析
labelFieldを使用してデータをマッピングし、DSE Graph Loaderで別の頂点ラベルへの入力を解析する。
入力ファイルには、頂点ラベルの識別に使用するフィールドが含まれる場合がよくあります。ファイルの読み込みと別の頂点ラベルの作成をその場で行うには、labelFieldを使用して特定のフィールドを識別します。
手順
labelFieldで同じファイルからauthorsとreviewersの両方を入力します。
/* SAMPLE INPUT
The input personInput includes type of person, name, gender; type can be either author or reviewer.
type::name::gender
author::Julia Child::F
reviewer::Jane Doe::F
*/
personInput = File.text('people.dat').
delimiter("::").
header('type','name','gender')
load(personInput).asVertices{
labelField "type"
key "name"
}g.V().hasLabel('author').valueMap()
{gender=[F], name=[Julia Child]}
g.V().hasLabel('reviewer').valueMap()
{gender=[F], name=[Jane Doe]}圧縮ファイルを使用したデータの読み込み
DSE Graph Loaderを使用した圧縮データのマッピング。
DSE Graph Loaderを使用して圧縮ファイルを読み込むと、頂点とエッジの両方を読み込むことができます。この例では、gzippedファイルを使用して、頂点とエッジおよびエッジ・プロパティを読み込みます。
手順
/* SAMPLE INPUT
rev_name|recipe_name|timestamp|stars|comment
John Doe|Beef Bourguignon|2014-01-01|5|comment
*/
// CONFIGURATION
// Configures the data loader to create the schema
config create_schema: false, load_new: false
// DATA INPUT
// Define the data input source (a file which can be specified via command line arguments)
// inputfiledir is the directory for the input files that is given in the commandline
// as the "-filename" option
inputfiledir = '/tmp/CSV/'
// This next file is not required if the reviewers already exist
reviewerInput = File.csv(inputfiledir + "reviewers.csv.gz").
gzip().
delimiter('|')
// This next file is not required if the recipes already exist
recipeInput = File.csv(inputfiledir +"recipes.csv.gz").
gzip().
delimiter('|')
// This is the file that is used to create the edges with edge properties
reviewerRatingInput = File.csv(inputfiledir + "reviewerRatings.csv.gz").
gzip().
delimiter('|')
//Specifies what data source to load using which mapper (as defined inline)
load(reviewerInput).asVertices {
label "reviewer"
key "name"
}
load(recipeInput).asVertices {
label "recipe"
key "name"
}
load(reviewerRatingInput).asEdges {
label "rated"
outV "rev_name", {
label "reviewer"
key "name"
}
inV "recipe_name", {
label "recipe"
key "name"
}
// properties are automatically added from the file, using the header line as property keys
// from previously created schema
}
圧縮ファイルは.gzファイルとして指定され、その後のgzip()ステップによって処理されます。エッジ・プロパティは、CSVファイルの各行にリストされた値に使用するプロパティ・キーを識別して、ヘッダーに基づいて入力ファイルのいずれかから読み込まれます。エッジ・プロパティによって、timestamp、stars、およびcommentプロパティでreviewer頂点とrecipe頂点間のratedエッジが指定されます。
複合カスタムIDを持つデータのマッピング
DSE Graph Loaderによる複合カスタムIDを持つデータのマッピング。
カスタムIDが定義用に複数のキー(partitionKeyまたはclusteringKeyのいずれか)を使用する場合、複合プライマリ・キーを持つデータには、読み込み用のキーを指定するときにいくつかの定義を追加する必要があります。
手順
-
複合カスタムIDを持つ頂点のデータを挿入するには、2つ以上のキーの宣言が必要です。
/* SAMPLE INPUT cityId|sensorId|fridgeItem santaCruz|93c4ec9b-68ff-455e-8668-1056ebc3689f|asparagus */ load(fridgeItemInput).asVertices { label "fridgeSensor" // The vertexLabel schema for fridgeSensor includes two keys: // partition key: cityId and clustering key: sensorId key cityId: "cityId", sensorId: "sensorId" }ヒント: 複合カスタムIDのスキーマは、DSE Graph Loaderを使用する前に作成する必要があり、データから推測することはできません。さらに、複合キーにすべてのプロパティを含む検索インデックスを作成します。この検索インデックスは、DSE Graph Loaderを使用して複合カスタムIDのデータを挿入するために必要です。頂点IDの結果をid()でチェックして、完全なプライマリ・キー定義を取得します。
各頂点は、データとしてgremlin> g.V().hasLabel('fridgeSensor').id() ==>{~label=fridgeSensor, sensorId=93c4ec9b-68ff-455e-8668-1056ebc3689f, cityId=santaCruz} ==>{~label=fridgeSensor, sensorId=9c23b683-1de2-4c97-a26a-277b3733732a, cityId=sacramento} ==>{~label=fridgeSensor, sensorId=eff4a8af-2b0d-4ba9-a063-c170130e2d84, cityId=sacramento}fridgeItemを格納します。gremlin> g.V().valueMap() ==>{fridgeItem=[asparagus]} ==>{fridgeItem=[ham]} ==>{fridgeItem=[eggs]} -
複合キーに基づいてエッジを読み込むには、変換が必要です。
/* SAMPLE EDGE DATA cityId|sensorId|name santaCruz|93c4ec9b-68ff-455e-8668-1056ebc3689f|asparagus */ the_edges = File.csv(inputfiledir + "fridgeItemEdges.csv").delimiter('|') the_edges = the_edges.transform { it['fridgeSensor'] = [ 'cityId' : it['cityId'], 'sensorId' : it['sensorId'] ]; it['ingredient'] = [ 'name' : it['name'] ]; it } load(the_edges).asEdges { label "contains" outV "ingredient", { label "ingredient" key "name" } inV "fridgeSensor", { label "fridgeSensor" key cityId:"cityId", sensorId:"sensorId" } }エッジ・ファイルは、パーティション・キーとクラスター化キーを
cityIdとsensorIdのマップに変換します。その後、このマップは、エッジを読み込むときに、fridgeSensor頂点のキーの指定に使用できます。結果のマップには、ingredientとfridgeSensorの頂点の間に作成されたエッジが表示されます。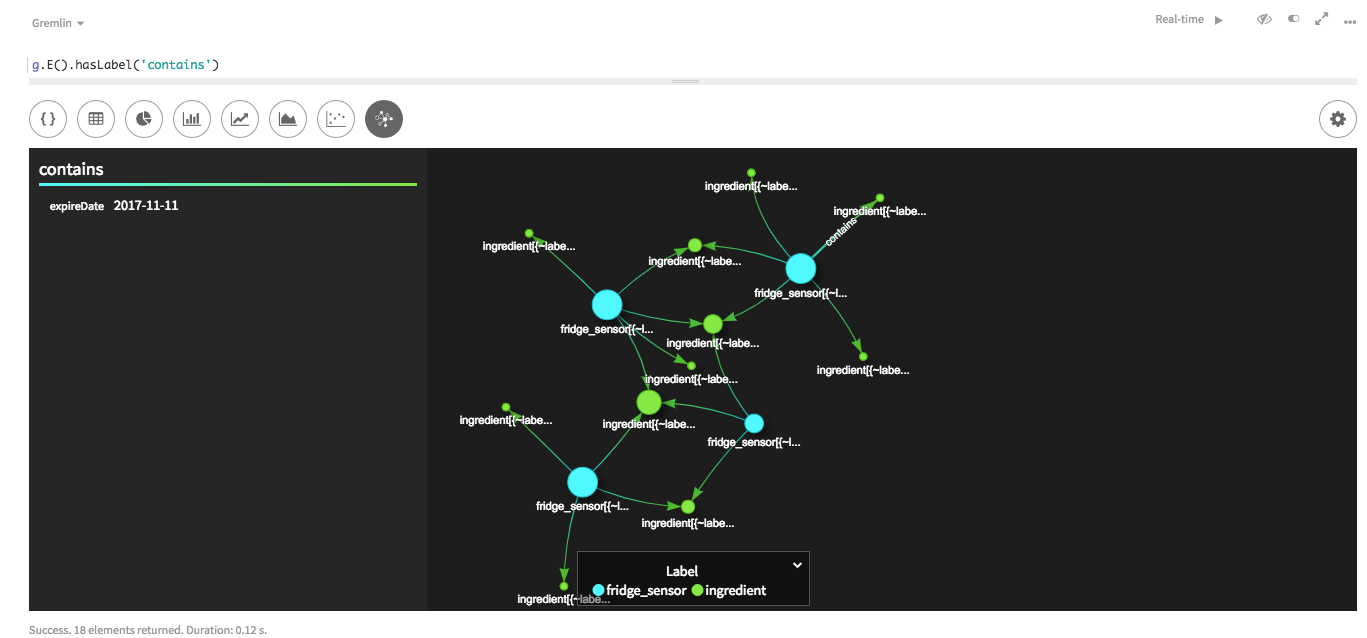
-
DSE 5.1.3以降では、CSVファイルからエッジ・データを読み込む方法を使用できます。
この例では、変換する必要はありませんが、/* SAMPLE EDGE DATA cityId|sensorId|homeId 100|001|9001 */ isLocatedAt_fridgeSensor = File.csv(/tmp/data/edges/" + "isLocatedAt_fridgeSensor.csv").delimiter('|') load(isLocatedAt_fridgeSensor).asEdges { label "isLocatedAt" outV { label "fridgeSensor" key cityId: "cityId", sensorId: "sensorId" exists() ignore "homeId" } inV { label "home" key "homeId" exists() ignore "cityId" ignore "sensorId" } ignore "cityId" ignore "sensorId" ignore "homeId" }inVおよびoutV宣言とエッジ・プロパティ・セクションの両方にignore文が必要です。内向き頂点および外向き頂点の宣言でexists()文を削除すると、頂点だけでなく、このマッピング・スクリプトのエッジの読み込みも有効になります。重要:inV宣言とoutV宣言には微妙な変更が新たに加えられています。複数キーのカスタムIDをサポートする必要があるため、inV "home", {などの入力フィールド名は今後使用されません。結果のマップは次のようになります。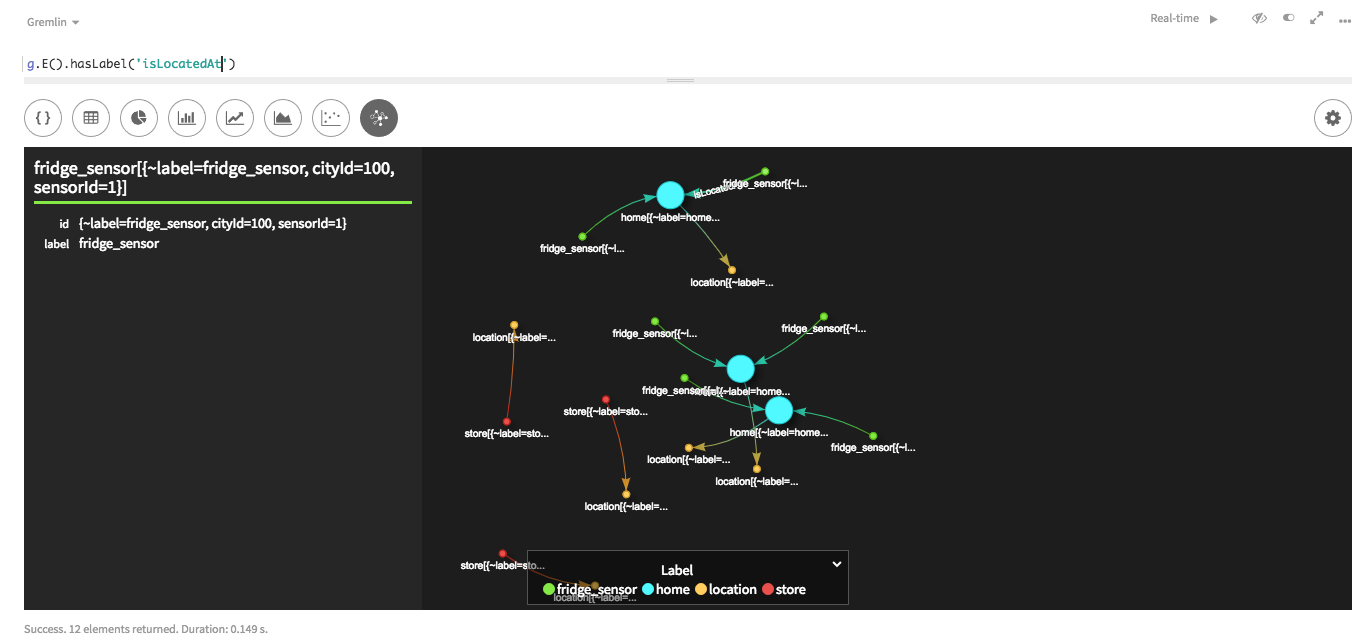
複数カーディナリティ・エッジのマッピング
DSE Graph Loaderを使用した複数カーディナリティ・エッジ・データのマッピング。
複数のカーディナリティ・エッジは、グラフに挿入される一般的なデータ型です。入力ファイルには、読み込み対象の頂点とエッジ両方の情報が含まれている場合がほとんどです。
手順
ignoreを慎重に使用して実行できます。
/* SAMPLE INPUT
authorCity:
author|city|dateStart|dateEnd
Julia Child|Paris|1961-01-01|1967-02-10
*/
// CONFIGURATION
// Configures the data loader to create the schema
config dryrun: false, preparation: true, create_schema: false, load_new: true, schema_output: 'loader_output.txt'
// DATA INPUT
// Define the data input source (a file which can be specified via command line arguments)
// inputfiledir is the directory for the input files
inputfiledir = '/tmp/multiCard/'
authorCityInput = File.csv(inputfiledir + "authorCity.csv").delimiter('|')
//Specifies what data source to load using which mapper (as defined inline)
// Ignore city, dateStart, and dateEnd when creating author vertices
load(authorCityInput).asVertices {
label "author"
key "author"
ignore "city"
ignore "dateStart"
ignore "dateEnd"
}
// Ignore author, dateStart, and dateEnd when creating city vertices
load(authorCityInput).asVertices {
label "city"
key "city"
ignore "author"
ignore "dateStart"
ignore "dateEnd"
}
// create edges from author -> city and include the edge properties dateStart and dateEnd
load(authorCityInput).asEdges {
label "livedIn"
outV "author", {
label "author"
key "author"
}
inV "city", {
label "city"
key "city"
}
}メタプロパティのマッピング
DSE Graph Loaderを使用したメタプロパティ・データのマッピング。
入力ファイルにメタプロパティ(プロパティを持つプロパティ)が含まれている場合は、vertexPropertyを使用します。
graphloaderを実行する前に作成する必要があります。// PROPERTY KEYS
schema.propertyKey('name').Text().single().create()
schema.propertyKey('gender').Text().single().create()
schema.propertyKey('badge').Text().single().create()
schema.propertyKey('since').Int().single().create()
// Create the meta-property since on the property badge
schema.propertyKey('badge').properties('since').add()
// VERTEX LABELS
schema.vertexLabel('reviewer').properties('name','gender','badge').create()
// INDEXES
schema.vertexLabel('reviewer').index('byname').materialized().by('name').add()手順
vertexPropertyを使用して、badgeを頂点プロパティとして識別します。JSONファイルのbadgeについてネストされているフィールドの構造に注意してください。
* SAMPLE INPUT
reviewer: { "name":"Jon Doe", "gender":"M", "badge" : { "value": "Gold Badge","since" : 2012 } }
*/
// CONFIGURATION
// Configures the data loader to create the schema
config dryrun: false, preparation: true, create_schema: true, load_new: true, load_vertex_threads: 3, schema_output: 'loader_output.txt'
// DATA INPUT
// Define the data input source (a file which can be specified via command line arguments)
// inputfiledir is the directory for the input files
inputfiledir = '/tmp/'
reviewerInput = File.json(inputfiledir + "reviewer.json")
//Specifies what data source to load using which mapper (as defined inline)
load(reviewerInput).asVertices{
label "reviewer"
key "name"
vertexProperty "badge", {
value "value"
}
}badgeがメタプロパティsinceを持つreviewer頂点が生成されます。g.V().valueMap()
{badge=[Gold Badge], gender=[M], name=[Jane Doe]}
g.V().properties('badge').valueMap()
{since=2012}複数のメタプロパティのマッピング
DSE Graph Loaderを使用した複数のメタプロパティ・データのマッピング。
入力ファイルに複数のメタプロパティ(複数のプロパティを持つプロパティ)が含まれている場合は、vertexPropertyを使用します。
graphloaderを実行する前に作成する必要があります。// PROPERTY KEYS
schema.propertyKey('badge').Text().multiple().create()
schema.propertyKey('gender').Text().single().create()
schema.propertyKey('name').Text().single().create()
schema.propertyKey('since').Int().single().create()
// VERTEX LABELS
schema.vertexLabel('reviewer').properties('name', 'gender', 'badge').create()
schema.propertyKey('badge').properties('since').add()
// INDEXES
schema.vertexLabel('reviewer').index('byname').materialized().by('name').add()手順
vertexPropertyを使用して、badgeを頂点プロパティとして識別します。JSONファイルのbadgeについてネストされているフィールドの構造に注意してください。
/* SAMPLE INPUT
reviewer: { "name":"Jane Doe", "gender":"F",
"badge" : [{ "value": "Gold Badge", "since" : 2012 },
{ "value": "Silver Badge", "since" : 2005 }] }
*/
// CONFIGURATION
// Configures the data loader to create the schema
config dryrun: false, preparation: true, create_schema: false, load_new: true, load_vertex_threads: 3, schema_output: 'loader_output.txt'
// DATA INPUT
// Define the data input source (a file which can be specified via command line arguments)
// inputfiledir is the directory for the input files
inputfiledir = '/tmp/'
reviewerInput = File.json(inputfiledir + "reviewerMultiMeta.json")
//Specifies what data source to load using which mapper (as defined inline)
load(reviewerInput).asVertices{
label "reviewer"
key "name"
vertexProperty "badge", {
value "value"
}
}/* SAMPLE INPUT
name|gender|value|since
Jane Doe|F|Gold Badge|2011
Jane Doe|F|Silver Badge|2005
Jon Doe|M|Gold Badge|2012
*/
// CONFIGURATION
// Configures the data loader to create the schema
config dryrun: false, preparation: true, create_schema: false, load_new: true, load_vertex_threads: 3, schema_output: 'loader_output.txt'
// DATA INPUT
// Define the data input source (a file which can be specified via command line arguments)
// inputfiledir is the directory for the input files
inputfiledir = '/tmp/'
reviewerInput = File.csv(inputfiledir + "reviewerMultiMeta.csv").delimiter('|')
//Specifies what data source to load using which mapper (as defined inline)
reviewerInput = reviewerInput.transform {
badge1 = [
"value": it.remove("value"),
"since": it.remove("since") ]
it["badge"] = [badge1]
it
}
load(reviewerInput).asVertices{
label "reviewer"
key "name"
vertexProperty "badge", {
value "value"
}
}badgeに複数の値が指定されているreviewer頂点が生成されます。 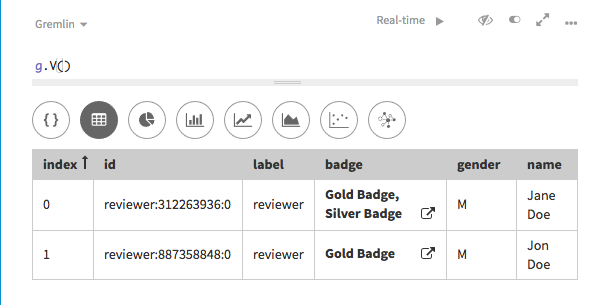
badgeのポップアップ・リンクを選択すると、メタプロパティ値が表示されます。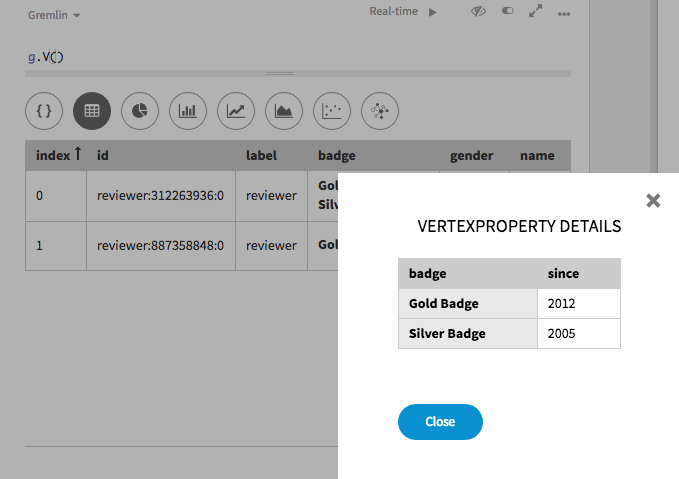
地理空間データとCartesianデータのマッピング
DSE Graph Loaderを使用した地理空間データとCartesianデータのマッピング。
地理空間データとCartesianデータは、DSE Graph Loaderを使用して読み込むことができます。DSE Graph Loaderでは、地理空間データとCartesianデータのスキーマを作成することができないため、スキーマを読み込む前に作成し、create_schema構成をfalseに設定する必要があります。
//SCHEMA
schema.propertyKey('name').Text().create()
schema.propertyKey('point').Point().withGeoBounds().create()
schema.vertexLabel('location').properties('name','point').create()
schema.propertyKey('line').Linestring().withGeoBounds().create()
schema.vertexLabel('lineLocation').properties('name','line').create()
schema.propertyKey('polygon').Polygon().withGeoBounds().create()
schema.vertexLabel('polyLocation').properties('name','polygon').create()
schema.vertexLabel('location').index('byname').materialized().by('name').add()
schema.vertexLabel('lineLocation').index('byname').materialized().by('name').add()
schema.vertexLabel('polyLocation').index('byname').materialized().by('name').add()
schema.vertexLabel('location').index('search').search().by('point').add()
schema.vertexLabel('lineLocation').index('search').search().by('line').add()
schema.vertexLabel('polyLocation').index('search).search().by('polygon').add()手順
- 必要に応じて、マッピング・スクリプトに構成を追加します。
-
データ入力ディレクトリーを指定します。変数
inputfiledirは、入力ファイルのディレクトリーを指定します。識別された各ファイルは、読み込みで使用されます。/* SAMPLE DATA name|point New York|POINT(74.0059 40.7128) Paris|POINT(2.3522 48.8566) */ // DATA INPUT // Define the data input source (a file which can be specified via command line arguments) // inputfiledir is the directory for the input files inputfiledir = '/tmp/geo_dgl/data/' ptsInput = File.csv(inputfiledir + "vertices/place.csv").delimiter('|') linesInput = File.csv(inputfiledir + "vertices/place_lines.csv").delimiter('|') polysInput = File.csv(inputfiledir + "vertices/place_polys.csv").delimiter('|') //Specifies what data source to load using which mapper (as defined inline) load(ptsInput).asVertices { label "location" key "name" } import com.datastax.driver.dse.geometry.Point ptsInput = ptsInput.transform { it['point'] = Point.fromWellKnownText(it['point']); return it; } load(linesInput).asVertices { label "lineLocation" key "name" } import com.datastax.driver.dse.geometry.LineString linesInput = linesInput.transform { it['line'] = LineString.fromWellKnownText(it['line']); return it; } load(polysInput).asVertices { label "polyLocation" key "name" } import com.datastax.driver.dse.geometry.Polygon polysInput = polysInput.transform { it['polygon'] = Polygon.fromWellKnownText(it['polygon']); return it; }入力データの変換機能が必要で、ポイントをWKT形式からDSE Graphが格納する形式に変換します。ポイントでは、変換機能によってポイント・ライブラリがインポートされ、fromWellKnownTextメソッドが使用されます。
ラインストリングと多角形では、同じライブラリとメソッドをそれぞれ使用します。import com.datastax.driver.dse.geometry.Point ptsInput = ptsInput.transform { it['point'] = Point.fromWellKnownText(it['point']); return it; } -
CSVの読み込みに、DSE Graph Loaderをディレクトリーから実行するには、次のコマンドを使用します。
$ graphloader geoMap.groovy -graph testGeo -address localhost
DSE Graphから生成されたGryoデータのマッピング
Gryoバイナリー・データを挿入するには、わずかに変更されたマップ・スクリプトが必要です。Gryoデータを読み込むには、DSE Graph Loaderによるスキーマの作成と新しいデータの読み込みを許可します。読み込み時に、グラフschema_modeを[Development]に設定する必要があります。
手順
//Need to specify a keymap to show how to identify vertices
vertexKeyMap = VertexKeyMap.with('meal','name').with('ingredient','name').with('author','name').with('book','name')
.with('recipe','name').build();
inputfiledir = '/tmp/Gryo/'
recipeInput = com.datastax.dsegraphloader.api.Graph.file(inputfiledir + 'recipesDSEG.gryo').
gryo().
setVertexUniqueKeys(vertexKeyMap)
load(recipeInput.vertices()).asVertices {
labelField "~label"
key "name"
}
load(recipeInput.edges()).asEdges {
labelField "~label"
outV "outV", {
labelField "~label"
key "name"
}
inV "inV", {
labelField "~label"
key "name"
}
}
Gryoデータ形式には、頂点とエッジを作成するために使用する必要がある~labelフィールド値とnameフィールド値が含まれます。たとえば、著者であるレコードにはauthorの~labelとプロパティnameが含まれます。vertexKeyMapによって、一意のプロパティに対する各頂点ラベルのマップが作成されます。このマップは、バイナリー・ファイルから頂点を読み込む際に使用されるユニーク・キーの作成に使用されます。
TinkerGraphによって生成されたGryoデータのマッピング
Gryoバイナリー・データを挿入するには、わずかに変更されたマップ・スクリプトが必要です。Gryoデータを読み込むには、DSE Graph Loaderによるスキーマの作成と新しいデータの読み込みを許可します。読み込み時に、グラフschema_modeを[Development]に設定する必要があります。
手順
//Specifies what data source to load using which mapper (as defined inline)
load(recipeInput.vertices()).asVertices {
labelField "~label"
key "~id", "id"
}
load(recipeInput.edges()).asEdges {
labelField "~label"
outV "outV", {
labelField "~label"
key "~id", "id"
}
inV "inV", {
labelField "~label"
key "~id", "id"
}
}Gryoデータ形式には、頂点とエッジを作成するために使用する必要がある~labelフィールド値とnameフィールド値が含まれます。たとえば、著者であるレコードにはauthorの~labelとプロパティnameが含まれます。vertexKeyMapによって、一意のプロパティに対する各頂点ラベルのマップが作成されます。このマップは、バイナリー・ファイルから頂点を読み込む際に使用されるユニーク・キーの作成に使用されます。
GraphMLバイナリー・データのマッピング
DSE Graph Loaderを使用したGraphMLデータのマッピング。
GraphMLバイナリー・データを挿入するには、わずかに変更されたマップ・スクリプトが必要です。GraphMLデータを読み込むには、DSE Graph Loaderによるスキーマの作成と新しいデータの読み込みを許可します。読み込み時に、グラフschema_modeを[Development]に設定する必要があります。
手順
//Specifies what data source to load using which mapper (as defined inline)
load(recipeInput.vertices()).asVertices {
labelField "~label"
key "~id", "id"
}
load(recipeInput.edges()).asEdges {
labelField "~label"
outV "outV", {
labelField "~label"
key "~id", "id"
}
inV "inV", {
labelField "~label"
key "~id", "id"
}
}~labelフィールド値と~idフィールド値が含まれます。たとえば、著者であるレコードにはauthorの~labelが含まれます。~idも同様に、レコードで他のデータとの違いが設定されます。違いについては、マッピング・スクリプトの各key設定の第2項目に基づいて、レコードを参照し、idフィールドの存在に留意することで確認できます。g.V().hasLabel('author').valueMap()
{gender=[F], name=[Julia Child], id=[0]}
{gender=[F], name=[Simone Beck], id=[3]}GraphSONバイナリー・データのマッピング
DSE Graph Loaderを使用したGraphSONデータのマッピング。
GraphSONデータを挿入するには、わずかに変更されたマップ・スクリプトが必要です。GraphSONデータを読み込むには、DSE Graph Loaderによるスキーマの作成と新しいデータの読み込みを許可します。読み込み時に、グラフschema_modeを[Development]に設定する必要があります。
手順
//Specifies what data source to load using which mapper (as defined inline)
load(recipeInput.vertices()).asVertices {
labelField "~label"
key "~id", "id"
}
load(recipeInput.edges()).asEdges {
labelField "~label"
outV "outV", {
labelField "~label"
key "~id", "id"
}
inV "inV", {
labelField "~label"
key "~id", "id"
}
}~labelフィールド値と~idフィールド値が含まれます。たとえば、著者であるレコードにはauthorの~labelが含まれます。~idも同様に、レコードで他のデータとの違いが設定されます。違いについては、マッピング・スクリプトの各key設定の第2項目に基づいて、レコードを参照し、idフィールドの存在に留意することで確認できます。g.V().hasLabel('author').valueMap()
{gender=[F], name=[Julia Child], id=[0]}
{gender=[F], name=[Simone Beck], id=[3]}