The write path to compaction
Cassandra processes data at several stages on the write path.
- Logging data in the commit log
- Writing data to the memtable
- Flushing data from the memtable
- Storing data on disk in SSTables
- Compaction
Logging writes and memtable storage
When a write occurs, Cassandra stores the data in a structure in memory, the memtable, and also appends writes to the commit log on disk, providing configurable durability. The commit log receives every write made to a Cassandra node, and these durable writes survive permanently even after power failure. The memtable is a write-back cache of data partitions that Cassandra looks up by key. The memtable stores writes until reaching a limit, and then is flushed.
Flushing data from the memtable
When memtable contents exceed a configurable threshold, the memtable data, which includes indexes, is put in a queue to be flushed to disk. You can configure the length of the queue by changing memtable_flush_queue_size in the cassandra.yaml. If the data to be flushed exceeds the queue size, Cassandra blocks writes until the next flush succeeds. You can manually flush a table using the nodetool flush command. Typically, before restarting nodes, flushing the memtable is recommended to reduce commit log replay time. To flush the data, Cassandra sorts memtables by token and then writes the data to disk sequentially.
Storing data on disk in SSTables
Data in the commit log is purged after its corresponding data in the memtable is flushed to an SSTable.
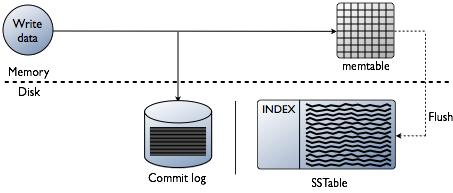
Memtables and SSTables are maintained per table. SSTables are immutable, not written to again after the memtable is flushed. Consequently, a partition is typically stored across multiple SSTable files.
For each SSTable, Cassandra creates these structures:
- Partition index
A list of partition keys and the start position of rows in the data file (on disk)
- Partition summary (in memory)
A sample of the partition index.
Compaction
Periodic compaction is essential to a healthy Cassandra database because Cassandra does not insert/update in place. As inserts/updates occur, instead of overwriting the rows, Cassandra writes a new timestamped version of the inserted or updated data in another SSTable. Cassandra manages the accumulation of SSTables on disk using compaction.
Cassandra also does not delete in place because the SSTable is immutable. Instead, Cassandra marks data to be deleted using a tombstone. Tombstones exist for a configured time period defined by the gc_grace_seconds value set on the table. During compaction, there is a temporary spike in disk space usage and disk I/O because the old and new SSTables co-exist. This diagram depicts the compaction process:
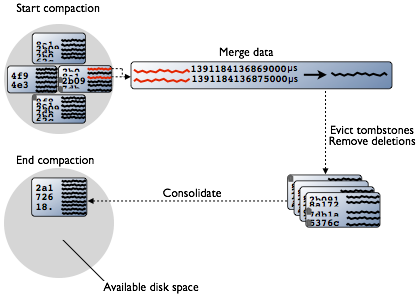
Compaction merges the data in each SSTable data by partition key, selecting the latest data for storage based on its timestamp. Cassandra can merge the data performantly, without random IO, because rows are sorted by partition key within each SSTable. After evicting tombstones and removing deleted data, columns, and rows, the compaction process consolidates SSTables into a single file. The old SSTable files are deleted as soon as any pending reads finish using the files. Disk space occupied by old SSTables becomes available for reuse.
Data input to SSTables is sorted to prevent random I/O during SSTable consolidation. After compaction, Cassandra uses the new consolidated SSTable instead of multiple old SSTables, fulfilling read requests more efficiently than before compaction. The old SSTable files are deleted as soon as any pending reads finish using the files. Disk space occupied by old SSTables becomes available for reuse.
Although no random I/O occurs, compaction can still be a fairly heavyweight operation. During compaction, there is a temporary spike in disk space usage and disk I/O because the old and new SSTables co-exist. To minimize deteriorating read speed, compaction runs in the background.
- Throttles compaction I/O to compaction_throughput_mb_per_sec (default 16MB/s).
- Requests that the operating system pull newly compacted partitions into the page cache when the key cache indicates that the compacted partition is hot for recent reads.
You can configure these types of compaction to run periodically: SizeTieredCompactionStrategy, DateTieredCompactionStrategy (Cassandra 2.0.11), and LeveledCompactionStrategy.
SizeTieredCompactionStrategy is designed for write-intensive workloads, DateTieredCompactionStrategy for time-series and expiring data, and LeveledCompactionStrategy for read-intensive workloads. You can manually start compaction using the nodetool compact command.
For more information about compaction strategies, see When to Use Leveled Compaction, Leveled Compaction in Apache Cassandra, and DateTieredCompactionStrategy.