QuickStart Simple example
Simple DataStax Graph example.
About this task
Let’s start with a simple example from the recipe data model.
The data is composed of two vertices, one person who is an author (Julia Child) and one book (The Art of French Cooking, Vol.
1) with an edge between them to identify that Julia Child authored that book.
We’ll supply schema, insert data using graph traversals with g.addV() and g.addE(), then examine the data and run queries.
Execute all code samples using either Studio or Gremlin console by copy/pasting the codeblocks below.
|
As with all queries in Graph, if you are using Gremlin console, alias the graph traversal g to a graph with |
Procedure
-
Create the schema for a vertex label
person, along with the vertex properties and their data types:schema.vertexLabel('person'). ifNotExists(). partitionBy('person_id', Uuid). property('name', Text). property('gender', Text). property('nickname', setOf(Text)). property('cal_goal', Int). property('macro_goal', listOf(Int)). property('country', listOf(tupleOf(Text, Date, Date))). property('badge', mapOf(Text, Date)). create()The vertex label defines the Cassandra Query Language (CQL) table name that will store
personvertices. Each property consists of a property key and data type that define CQL columns in the table. Both the vertex label and the property definitions must adhere to CQL naming syntax. Like CQL tables, a single or multiple partition key must be defined with at least one property usingpartitionBy property\_name. Clustering columns may also be defined using a similarclusteringBy property\_name. The partition key defines where in the cluster the data will reside, while the clustering columns define the sort order of the data within a partition.A new feature of DataStax Graph 6.8 is the use of collections as data types for properties. The DSE 6.7 Graph and earlier concepts of meta-properties and multi-properties are replaced with collections or nested collections. For instance,
countryis now defined as a list of tuples, to store multiple records of a country,start_date and end_date in which a person has lived.A successful schema command will return:
==> OK -
Insert a vertex for Julia Child using a
g.addV()command.g.addV('person'). property('person_id', 'e7cd5752-bc0d-4157-a80f-7523add8dbcd' as UUID). property('name', 'Julia CHILD'). property('gender','F'). property('nickname', ['Jay', 'Julia'] as Set). property('country', [['USA', '1912-08-12' as LocalDate, '1944-01-01' as LocalDate] as Tuple, ['Ceylon', '1944-01-01' as LocalDate, '1945-06-01' as LocalDate] as Tuple, ['France', '1948-01-01' as LocalDate, '1960-01-01' as LocalDate] as Tuple, ['USA', '1960-01-01' as LocalDate, '2004-08-13' as LocalDate] as Tuple])The vertex label
personidentifies the type of vertex to add along with the property key-value pairs created. Note that some properties include additional information to define the data type conversion from a string to the required type.Using a
set, the property nickname is defined with multiple values, a replacement for previously supported multi-properties.The Studio result:

In Studio, the result can be displayed using different views: Raw JSON, Table, or Graph. Explore the options.
The Gremlin console result:
==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd] -
Create the schema for a vertex label
book:schema.vertexLabel('book'). ifNotExists(). partitionBy('book_id', Int). property('name', Text). property('publish_year', Int). property('isbn', Text). property('category', setOf(Text)). create()This command and the next one will return results similar to the actions above for creating a
person. -
Insert a book into the graph:
g.addV('book'). property('book_id',1001). property('name',"The Art of French Cooking, Vol. 1"). property('publish_year', 1961). property('category', ['French', 'American'] as Set)The Studio result:
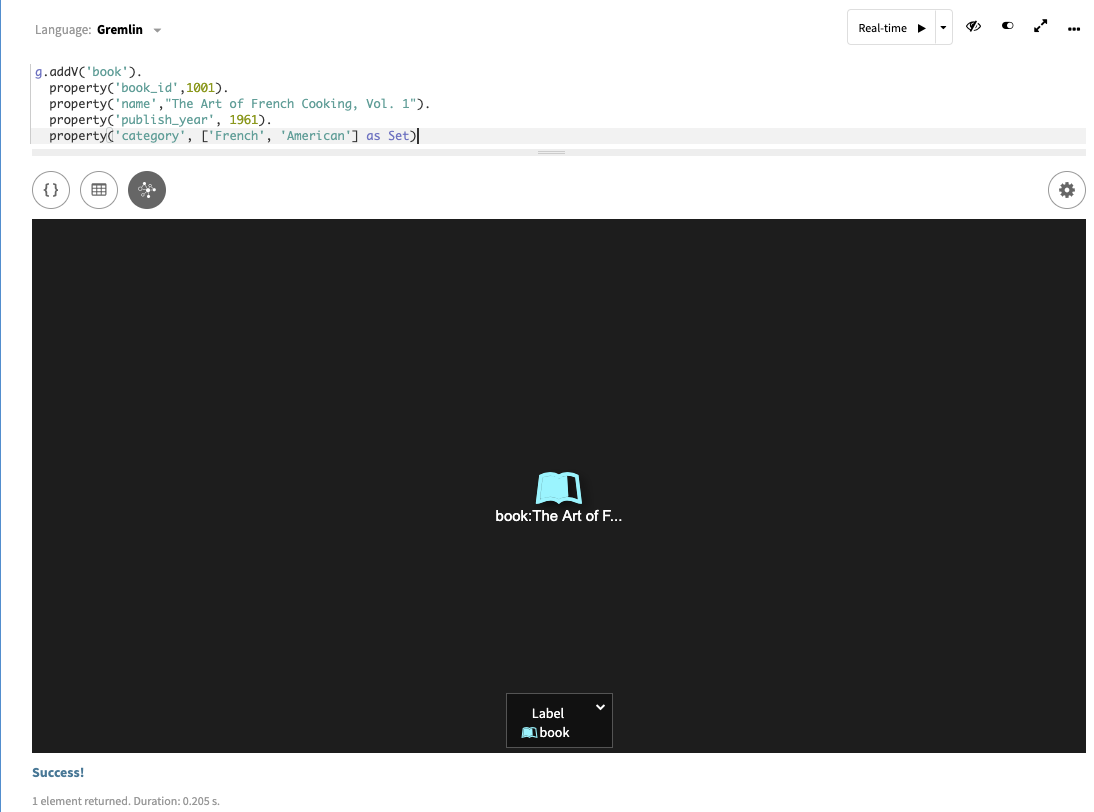
As with the person vertex, you can see all the information about the book vertex created. In Graph view, use the Settings button (the gear) to change the display label for person by entering
Chef {{name}}. Change the book display label withbook:{{{[name]}}}. Change the icon for books to a book icon as shown here with the Style-Vertex Shape menu. To set graph display names more generally, look for “Manage Global Defaults” under the Display NamesThe Gremlin console result:
==>v[dseg:/book/1001] -
Add schema for the edge between the two vertices for a person authoring a book:
schema.edgeLabel('authored'). ifNotExists(). from('person').to('book'). create()The edge label
authoredis defined, along with the outgoing vertex labelpersonand the incoming vertex labelbook. -
Insert an edge between Julia Child and one of her cookbooks:
g.V('dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd').as('a'). V('dseg:/book/1001').as('b'). addE('authored').from('a').to('b')In this query, each vertex is defined and given a temporary label,
personasaandbookasb, and the temporary labels used to add the edge withaddE().from().to(). The partition key and value for each vertex must be included in the query.Use Graph view in Studio to see the relationship. Scroll over elements to display additional information.
The Studio result:

The Gremlin console result:
==>e[dseg:/person-authored-book/e7cd5752-bc0d-4157-a80f-7523add8dbcd/1001][dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd-authored->dseg:/book/1001] -
In Studio, the results are easy to visualize and check. In the Gremlin console, ensure that the data inserted for the vertices is correct by checking with a query that gets all vertices. All of the commands can be executed in Studio as well as Gremlin console. In production, DSG prevents expensives queries from processing. In development, include the
with("label-warning", false)so that a query can run without specifying vertex labels.g.with("label-warning", false).V().
The Gremlin console result:
==>v[dseg:/book/1001] ==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd] -
Similarly, the edge data inserted can be checked with a query that gets all edges:
g.with("label-warning", false).E()The Gremlin console result:
==>e[dseg:/person-authored-book/e7cd5752-bc0d-4157-a80f-7523add8dbcd/1001][dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd-authored->dseg:/book/1001] -
A much more useful query would check the data for a vertex using a simple bit of information, like a person’s name. However, without adding an index for
name, this query will fail, because the value for the primary keyperson_idis not supplied. For example:g.V().has('person', 'name', 'Julia CHILD')Two alternatives exist, a development mode for running queries and a modifier mode
with('allow-filtering'). Thedevmode is intended for early exploration, before appropriate indexes have been settled upon:dev.V().hasLabel('person').has('name', 'Julia CHILD')An alternative in development is to use the
with('allow-filtering')step which will do a full scan of all partitions:g.with('allow-filtering').V().has('person', 'name', 'Julia CHILD')Both commands will return the same information, the vertex id for the vertex found with the query. In Studio:

and in Gremlin console:
==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd] -
You’ll notice when you tried the command
g.V().has('person', 'name', 'Julia CHILD'), you got an error message that provides the index required to do the query in a production-safe manner:schema.vertexLabel('person'). materializedView('person_by_name'). ifNotExists(). partitionBy('name'). clusterBy('person_id', Asc). create()Note that while the index has been created successfully, it may not yet be finished building. Alternatively, use '.waitForIndex(<optionalTimeout>).create()' during index creation to wait for the index to be built. OKThe index is created as a materialized view table, with a partition key of the column to index and a clustering column of the original table’s partition key. Once the index exists, the query will run without doing a full scan. Indexing is a large topic that is worth reading about, as efficient queries depend on indexes.
-
Notice that the original query about Julia Child will now run without warnings, after the index is created, and returns the same information as the development queries:
g.V().has('person', 'name', 'Julia CHILD') -
We now have data! Let’s see what kind of graph queries can be executed. First, check the data using the unique partition key:
g.V().has('person', 'person_id', UUID.fromString('e7cd5752-bc0d-4157-a80f-7523add8dbcd'))In Studio:
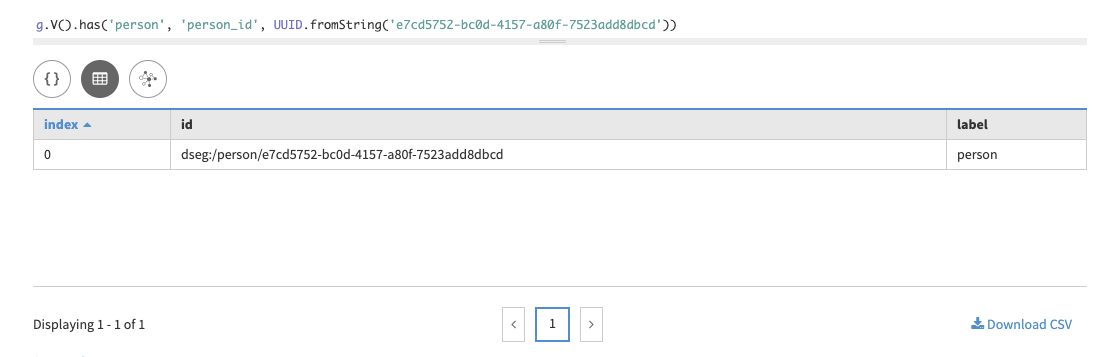
In Gremlin console:
==>v[dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd]While the partition key will be useful in some queries, generally queries use more user-friendly data, like
nameorcategory, to find vertices. -
Two other useful traversals are
elementMap()andvalueMap()which print the key-value listing of each property value for specified vertices.g.V().hasLabel('person').elementMap()In Studio:
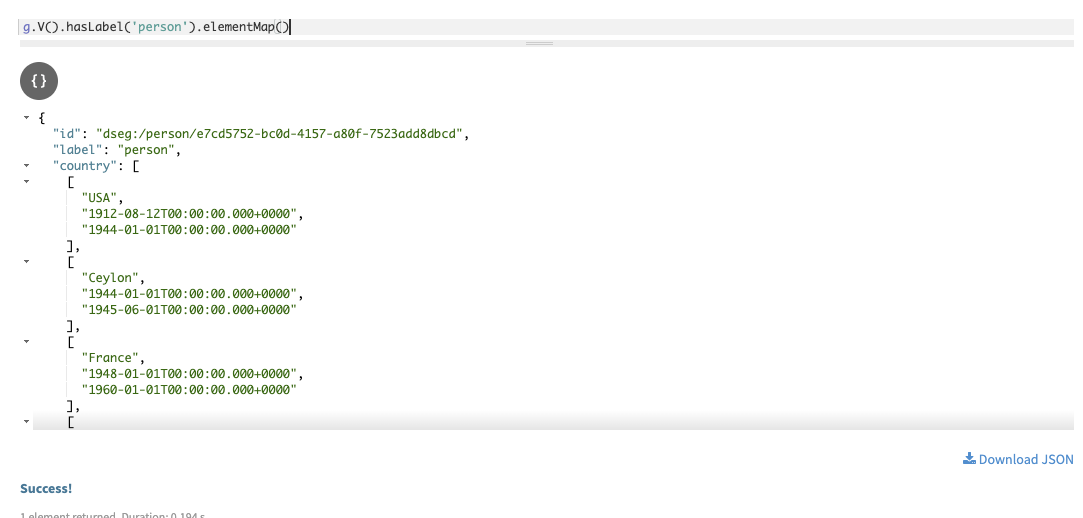
Using
elementMap()orvalueMap()without specifying properties can result in slow query latencies, if a large number of property keys exist for the queried vertex or edge. Specific properties can be specified, such aselementMap('name') or``valueMap('name').In Gremlin console:
gremlin> g.V().hasLabel('person').elementMap() ==>{id=dseg:/person/4ce9caf1-25b8-468e-a983-69bad20c017a, label=person, gender=M, name=James BEARD, nickname=[Jim, Jimmy], person_id=4ce9caf1-25b8-468e-a983-69bad20c017a} ==>{id=dseg:/person/888ad970-0efc-4e2c-b234-b6a71c30efb5, label=person, gender=M, name=Fritz STREIFF, person_id=888ad970-0efc-4e2c-b234-b6a71c30efb5} ==>{id=dseg:/person/4954d71d-f78c-4a6d-9c4a-f40903edbf3c, label=person, cal_goal=1800, gender=M, macro_goal=[30, 20, 50], name=John Smith, nickname=[Johnie], person_id=4954d71d-f78c-4a6d-9c4a-f40903edbf3c} ==>{id=dseg:/person/01e22ca6-da10-4cf7-8903-9b7e30c25805, label=person, gender=F, name=Kelsie KERR, person_id=01e22ca6-da10-4cf7-8903-9b7e30c25805} ==>{id=dseg:/person/6c09f656-5aef-46df-97f9-e7f984c9a3d9, label=person, cal_goal=1500, gender=F, macro_goal=[50, 15, 35], name=Jane DOE, nickname=[Janie], person_id=6c09f656-5aef-46df-97f9-e7f984c9a3d9} ==>{id=dseg:/person/e7cd5752-bc0d-4157-a80f-7523add8dbcd, label=person, country=[('USA','1912-08-12','1944-01-01'), ('Ceylon','1944-01-01','1945-06-01'), ('France','1948-01-01','1950-01-01'), ('USA','1960-01-01','2004-08-13')], gender=F, name=Julia CHILD, nickname=[Jay, Julia], person_id=e7cd5752-bc0d-4157-a80f-7523add8dbcd}Using
valueMap()returns similar information in a slightly different container, but doesn’t include the elementidandlabel. Try out the command and compare! In DSG 6.8.0,valueMap()is deprecated, so useelementMap().
